专栏文章
冷门数据结构——浅谈划分树
算法·理论参与者 35已保存评论 42
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 42 条
- 当前快照
- 1 份
- 快照标识符
- @mhz5s8rz
- 此快照首次捕获于
- 2025/11/15 01:55 4 个月前
- 此快照最后确认于
- 2025/11/29 05:24 3 个月前
划分树,是一种可以解决静态区间第大的数据结构,时间复杂度和空间复杂度均为,在实际表现中,时间和空间都优于主席树,并且个人认为其理解难度也远低于主席树
既然这是个好东西,那就让我们看看它的实现
概述
划分树通过一定的方式,以原序列为基础建出一棵层的树(空间复杂度就是),之后根据“第K大”,逐层找出答案(所以时间复杂度也是)
而“一定的方式”则是按照区间内数值的大小顺序将前半段分到左儿子,后半段分到右儿子,这样就可以用类似于二分查找的方式解决静态区间第大问题
建树
划分树建出来就是这么一个东西(是不是很像线段树)

可以看到,其中有一些粗体和斜体的值,粗体表示该数值小于等于区间中位数,而斜体则就是区间中位数
我们发现,那些不大于区间中位数的数都被分到了左子树,剩下的则去了右子树。这就是划分树的建树方式,原理很简单,根据定义,我们要把排序后前半段分到左子树,但是对每一个节点一遍复杂度着实爆炸,这时候我们发现,排序后前半段一定不大于区间中位数,于是就省去了这个。代码相较于其他建树较长,但是也不是很难
但是这时候问题就产生了:一个区间的中位数怎么求?若是有大于一半的数值比区间中位数大怎么办?
第一个问题有一个很巧妙的办法解决:一个区间的中位数,就是整个序列排序后该区间的,很容易理解对不对。这就需要我们先对整个序列排个序,所以你也可以认为这是一棵基于sort的线段树
仔细第二个问题,发现它对问题的求解影响并不大,所以我们只要把节点的左儿子塞满就好了,这样就能保证划分树的深度不会超过
初始定义:
CPP#define mid ((le+ri)>>1)
#define lson le,mid,dep+1
#define rson mid+1,ri,dep+1
struct Node{
//树的每一层节点
int num[N],toleft[N];
//当前节点的值和去往左子树的数值数量
};
Node t[M];
int sorted[N];
//排序后的序列
建树部分代码(是不是很像归并排序):
CPPvoid build(int le,int ri,int dep){
if(le==ri){
return;
//到达叶子节点,直接返回
}
int key=sorted[mid];
int equ=mid-le+1;
for(int i=le;i<=ri;i++){
if(t[dep].num[i]<key){
equ--;
//找出等于区间等于中位数数值的个数,特殊处理
}
}
int tl=0;
int it1=le-1,it2=mid;
//左右儿子指针
for(int i=le;i<=ri;i++){
int now=t[dep].num[i];
if(now<key||(now==key&&equ)){
if(now==key){
equ--;
}
tl++;
t[dep+1].num[++it1]=now;
}
else{
t[dep+1].num[++it2]=now;
}
t[dep].toleft[i]=tl;
}
build(lson);
build(rson);
//递归建树,深度不大于log
}
查询
建好树之后,我们就可以用它解决我们的问题了
还是这张图,假如我们现在要查询区间内的第大数(是不是很像二叉查找树):
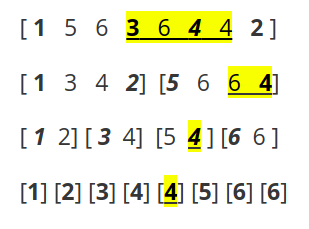
每次查询时,我们先看当前区间进入左子树的数值数量是否大于等于,如果是,则第大在左儿子,否则就在右儿子。就比如说上图的,可以看到其中的都进入了左儿子,一共是两个,比要小,所以我们进入右子树,依此类推,直到到达叶子节点,那就是我们要寻找的答案。
这时候,一个恶心麻烦的问题就来了:查询区间的缩小
这时候我们想一个事情:我们划分左右儿子时,是用的两个指针直接扫一遍的。也就是说,数值之间的相对位置没有改变。那么,在一个区间中,小于等于区间中位数的数值在左儿子中是连续的,大于(或者等于)区间中位数的数值在右儿子也是连续的。有了这个很好的性质,查询区间的缩小也就不那么麻烦了,还是挺好理解的
假如我们下一步要进入左子树,那么根据上面提到的性质,新的查询左端点就是左儿子节点的左端点加上查询区间左边进入左子树数值的数量,新的查询右端点就是新的查询左端点的基础上加上当前查询区间中进入左子树数值的数量,因为这些数值在左儿子中一定是连续的,所以它们一定是一个新的连续区间
假如下一步进入右子树也差不多,新的查询左端点就是当前节点右儿子的左端点加上原来的查询左端点之前的数值数,再减去原来查询区间之前进入左子树的数值的数量,新的查询右端点就是在新的查询左端点基础上加上旧的查询区间的长度,再减去旧查询区间中进入左子树数值的数量
大体上可以理解为,进入左子树就是把查询区间中不大于中位数的数值取出来组合成新的查询区间,再对应到左儿子中相应的位置,进入右子树则是反过来
建议揣摩一下代码+画图理解
查询部分代码:
CPPint query(int le,int ri,int dep,int x,int y,int z){
if(le==ri){
return t[dep].num[le];
//到达叶节点,说明已经找到答案,直接返回
}
int tl=0,del=t[dep].toleft[y];
//查询区间之前进入左儿子的数值数和查询区间内进入左儿子的数值数
if(le!=x){
//这里一定要特判
//如果当前节点管辖范围的左端点和查询区间左端点重叠
//那就不要减去,因为那就会越到该节点左边的那个节点
//而且重叠本身就不需要减去左端点之前的toleft
tl=t[dep].toleft[x-1];
del-=tl;
}
int nx,ny;
//新的查询区间
if(del>=z){
//如果当前进入左儿子的数值数大于k,则第k大在左儿子
nx=le+tl;
ny=nx+del-1;
return query(lson,nx,ny,z);
}
else{
//否则就在右儿子
nx=mid+1+x-le-tl;
ny=nx+y-x-del;
return query(rson,nx,ny,z-del);
}
}
完整代码:
CPP#include<iostream>
#include<cstdio>
#include<cctype>
#include<cstring>
#include<algorithm>
using namespace std;
int read(){
int w=0;
bool s=0;
char c=getchar();
while(!isdigit(c)){
s=(c=='-');
c=getchar();
}
while(isdigit(c)){
w=w*10+c-'0';
c=getchar();
}
return s?-w:w;
}
const int N=200005,M=20;
int n,m;
struct Tree{
#define mid ((le+ri)>>1)
#define lson le,mid,dep+1
#define rson mid+1,ri,dep+1
struct Node{
int num[N],toleft[N];
};
Node t[M];
int sorted[N];
void build(int le,int ri,int dep){
if(le==ri){
return;
}
int key=sorted[mid];
int equ=mid-le+1;
for(int i=le;i<=ri;i++){
if(t[dep].num[i]<key){
equ--;
}
}
int tl=0;
int it1=le-1,it2=mid;
for(int i=le;i<=ri;i++){
int now=t[dep].num[i];
if(now<key||(now==key&&equ)){
if(now==key){
equ--;
}
tl++;
t[dep+1].num[++it1]=now;
}
else{
t[dep+1].num[++it2]=now;
}
t[dep].toleft[i]=tl;
}
build(lson);
build(rson);
}
int query(int le,int ri,int dep,int x,int y,int z){
if(le==ri){
return t[dep].num[le];
}
int tl=0,del=t[dep].toleft[y];
if(le!=x){
tl=t[dep].toleft[x-1];
del-=tl;
}
int nx,ny;
if(del>=z){
nx=le+tl;
ny=nx+del-1;
return query(lson,nx,ny,z);
}
else{
nx=mid+1+x-tl-le;
ny=nx+y-x-del;
return query(rson,nx,ny,z-del);
}
}
};
Tree T;
int main(){
n=read(),m=read();
for(int i=1;i<=n;i++){
T.t[0].num[i]=read();
T.sorted[i]=T.t[0].num[i];
}
sort(T.sorted+1,T.sorted+1+n);
T.build(1,n,0);
int x,y,z;
for(int i=1;i<=m;i++){
x=read(),y=read(),z=read();
int ans=T.query(1,n,0,x,y,z);
printf("%d\n",ans);
}
return 0;
}
GL~
一些题目
模板题:P3834 【模板】可持久化线段树 1(主席树) ~主席树模板?不存在的~
板题,直接上划分树就好了。可以看到常数比主席树小很多(上方为划分树)

同上,没什么好说的
题目大意:给你一个序列,每次给你一个区间 ,求区间中不大于的数量
在划分树的基础上套一个二分即可,二分出第一个使得区间第大不小于的,即为答案
时间复杂度
核心代码:
CPPint find(int x,int y,int z){
int le=1,ri=y-x+1;
int res=0;
while(le<=ri){
int mid=(le+ri)>>1;
int tmp=T.query(1,n,0,x,y,mid);
if(tmp<=z){
res=mid;
le=mid+1;
}
else{
ri=mid-1;
}
}
return res;
}
int main(){
Case=read();
for(int C=1;C<=Case;C++){
printf("Case %d:\n",C);
n=read(),m=read();
for(int i=1;i<=n;i++){
T.t[0].num[i]=read();
T.sorted[i]=T.t[0].num[i];
}
sort(T.sorted+1,T.sorted+1+n);
T.build(1,n,0);
int x,y,z;
for(int i=1;i<=m;i++){
x=read(),y=read(),z=read();
x++;
y++;
int ans=find(x,y,z);
printf("%d\n",ans);
}
}
return 0;
}
一道好题:HDU3473 Minimum Sum
题目大意:给你一个序列,每次给出一个区间,要求从区间中取出一个使得最小,并求出这个最小值
这道题目就很好的体现了我们划分树的性质及应用
首先,我们选出的这个一定是查询区间的中位数,这个证明还算比较简单,就略过了。而用划分树求出区间中位数是非常方便的,因为一个区间的中位数就是区间第大的数,这个很好求
那么我们每一次询问的答案就是,其中为排好序的查询区间,是区间中位数的下标
化一下式子,答案就是,发现这个东西其实相当于把区间里大于中位数的数之和减去剩下的数之和
而这个东西可以在我们用划分树求解中位数时一起搞定。对于每一个节点,我们多维护一个前缀和数组。在查找中位数时,进入左子树,答案就加上当前查询区间进入右子树的数值之和,进入右子树,答案减去当前查询区间进入左子树的数值之和。结合划分树求解区间第大的原理,发现这样求出来的答案就等价于上面的式子
代码(注意:此题有点卡空间):
CPP#include<iostream>
#include<cstdio>
#include<cctype>
#include<cstring>
#include<algorithm>
#define ll long long
using namespace std;
ll read(){
int w=0;
bool s=0;
char c=getchar();
while(!isdigit(c)){
s=(c=='-');
c=getchar();
}
while(isdigit(c)){
w=w*10+c-'0';
c=getchar();
}
return s?-w:w;
}
const int N=100005,M=18;
int n,m;
struct Tree{
#define mid ((le+ri)>>1)
#define lson le,mid,dep+1
#define rson mid+1,ri,dep+1
struct Node{
ll sum[N];
int num[N],toleft[N];
};
Node t[M];
int sorted[N];
void build(int le,int ri,int dep){
if(le==ri){
t[dep].sum[le]=t[dep].num[le];
return;
}
int key=sorted[mid];
int equ=mid-le+1;
for(int i=le;i<=ri;i++){
if(t[dep].num[i]<key){
equ--;
}
}
int tl=0;
ll pre=0;
int it1=le-1,it2=mid;
for(int i=le;i<=ri;i++){
int now=t[dep].num[i];
pre+=now;
if(now<key||(now==key&&equ)){
if(now==key){
equ--;
}
tl++;
t[dep+1].num[++it1]=now;
}
else{
t[dep+1].num[++it2]=now;
}
t[dep].toleft[i]=tl;
t[dep].sum[i]=pre;
}
build(lson);
build(rson);
}
ll cnt;
int query(int le,int ri,int dep,int x,int y,int z){
if(le==ri){
return t[dep].num[le];
}
int tl=0,del=t[dep].toleft[y];
ll tmp1=t[dep].sum[y];
if(le!=x){
tl=t[dep].toleft[x-1];
del-=tl;
tmp1-=t[dep].sum[x-1];
}
int nx,ny;
if(del>=z){
nx=le+tl;
ny=nx+del-1;
ll tmp2=t[dep+1].sum[ny];
if(nx!=le){
tmp2-=t[dep+1].sum[nx-1];
}
cnt+=tmp1-tmp2;
return query(lson,nx,ny,z);
}
else{
nx=mid+1+x-tl-le;
ny=nx+y-x-del;
ll tmp2=t[dep+1].sum[ny];
if(nx!=mid+1){
tmp2-=t[dep+1].sum[nx-1];
}
cnt-=tmp1-tmp2;
return query(rson,nx,ny,z-del);
}
}
};
Tree T;
int Case;
int main(){
Case=read();
for(int C=1;C<=Case;C++){
printf("Case #%d:\n",C);
n=read();
for(int i=1;i<=n;i++){
T.t[0].num[i]=read();
T.sorted[i]=T.t[0].num[i];
}
sort(T.sorted+1,T.sorted+1+n);
T.build(1,n,0);
T.t[0].sum[0]=0;
m=read();
int x,y;
for(int i=1;i<=m;i++){
x=read(),y=read();
T.cnt=0;
x++;
y++;
ll tmp1=T.query(1,n,0,x,y,(((y-x+1)>>1)+((y-x+1)&1)));
ll ans=T.cnt;
if(!((y-x+1)&1)){
ans-=tmp1;
}
printf("%lld\n",ans);
}
putchar('\n');
}
return 0;
}
Update
- 2019-12-25 更正图片(感谢@oisdoaiu 的指出)
碎碎念
-
这个东西应用范围其实很小,
基本上没什么用 -
划分树的建树过程其实可以看作一个稳定的排序(虽然说本来就排了一遍序)
-
我之后又尝试打了个非递归版本,发现效率基本没差,甚至变慢了(也可能是我打丑了)
-
本人表达能力极差,若不能理解文字还请见谅
相关推荐
评论
共 42 条评论,欢迎与作者交流。
正在加载评论...