专栏文章
字符串·学习笔记·算法详解 1
算法·理论参与者 7已保存评论 10
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 8 条
- 当前快照
- 1 份
- 快照标识符
- @mi4ddhsz
- 此快照首次捕获于
- 2025/11/18 17:27 3 个月前
- 此快照最后确认于
- 2025/12/02 00:11 3 个月前
字符串·学习笔记·算法详解
*如果要了解字符串相关的定义先看 OI wiki,定义类的东西就不在这里赘述了。
星号(*)开头的句子是提示,建议还是看看吧。
Changelog
Created on 11/7:
中午起床之后没什么做题的动力啊,所以就来写一下这几天学字符串的记录。
中午起床之后没什么做题的动力啊,所以就来写一下这几天学字符串的记录。
其实记录是一直都有在写的,不过这几天看到很多朋友都和我一样,接触的字符串算法很少,在 CSP-S 的 T3 阴了,所以把这些东西整理了下,希望能够有帮助。
写这篇记录除了上面,其实还有一个原因,就是我在学字符串的时候没找到有很好的整理好的讲解,在 OI wiki 上的相关内容对于初学者也没有那么友好(反正看的我一愣一愣的),就写了这个东西。
毕竟也是我啃 OI wiki 啃出来的,所以划分和 OI wiki 也基本一样,不过把顺序调整了一下(后缀自动机放马拉车前面什么意思啊!!!),然后不用 OI wiki 上那么严谨科学的语言,对初学者还是通俗易懂好一点。而且对于字符串题还是画图理解会比较好,所以我画图了。
希望这篇记录能够在各位碰到说:“唉怎么又是串串题,我关于这些的算法一个都不会”的人直接甩出去,所以如果有不是那么易懂的地方/有错误的地方/需要删减的地方直接在评论就行了。
Updated on 11/17:
本来想着学完后缀自动机再来写这个的,但是发现如果要加上后缀自动机,篇幅就太大了,更何况字符串又不只有这些东西,所以就想着先把字符串学习笔记拆成 部分。然后就简单的整理了一下。
本来想着学完后缀自动机再来写这个的,但是发现如果要加上后缀自动机,篇幅就太大了,更何况字符串又不只有这些东西,所以就想着先把字符串学习笔记拆成 部分。然后就简单的整理了一下。
自己翻了翻,发现其实一开始我在自己的日常记录写的还是有点抽象,还是花了点修正了一些错误和一些并不友好的地方。然后有一些实在没办法的地方加上了一些提醒(星号开头的句子),然后第一部分我们就撒花了。
Updated on 11/18:
布豪!被打回了。
布豪!被打回了。
没办法啊,第一次写字符串类的专栏,还不清楚各类表达,就只能按照 OI wiki 上的表示来了,然后就:
拒绝原因
上下标应使用 (
拒绝原因
上下标应使用 (
$a _ {b} ^ {c}$)进行表示。Emm...不过也感谢管理员十点多审核,比上次鸽了 天快多了。
我放一些这几天我在用的题单吧,我才刚学还没刷完,在这下面也会放一些我不是很懂的题的记录。
字典树 Trie
字典树,英文名 Trie。顾名思义,就是一个像字典一样的树。——OI wiki
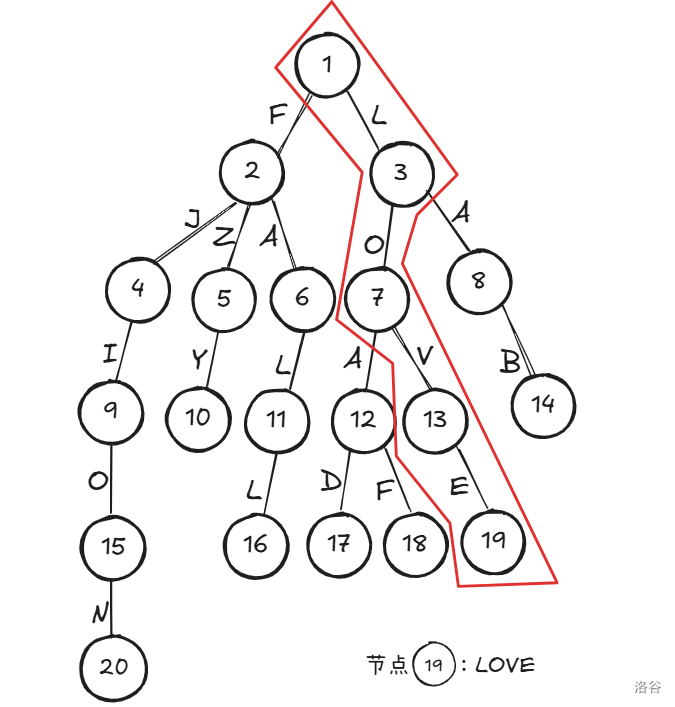
如上,在 Trie 中,每一条边都代表一个字母,那么根节点到一个节点的一条路径就是一个字符串。
例如上图的节点 。
代码非常好懂,用处也非常多。
Code.Trie 模板
CPPstruct Trie{
bool bj[N];
int nxt[N][26],cnt;
void add(string x){
int p = 0,len = x.size();
for(int i = 0;i < len;i ++){
if(!nxt[p][x[i] - 'a']) nxt[p][x[i] - 'a'] = ++ cnt;
p = nxt[p][x[i] - 'a'];
}
bj[p] ++;
}
void Find(string x){
int p = 0,len = x.size();
for(int i = 0;i < len;i ++){
if(!nxt[p][x[i] - 'a']) return 0;
p=nxt[p][x[i] - 'a'];
}
return bj[p];
}
}trie;
应用:检索字符串
检索一个字符串是否在给定字符串集合出现。
应用:AC自动机
AC 自动机就是根据 KMP 的思想增加了失配指针的 Trie。
应用:01 Trie
根据二进制建立 Trie。
这部分就跟字符串没有什么太大的关系了,所以我们在这里先按下不表,到关于数据结构的部分我再详细讲解。
这部分就跟字符串没有什么太大的关系了,所以我们在这里先按下不表,到关于数据结构的部分我再详细讲解。
前缀函数与 KMP 算法
定义关于字符串 的函数 表示 的子串 中,真前缀与真后缀相等的最大长度,其中 表示 的长度。
那么这个函数就是前缀函数,而我们需要求解这个关于字符串 每一个位置的 函数。
首先思考根据定义的朴素算法:
遍历字符串 ,每到一个 ,枚举最大长度并判断进行判断。
遍历字符串 ,每到一个 ,枚举最大长度并判断进行判断。
遍历次数为 ,枚举长度次数为 ,判断过程为 ,故总的时间复杂度为 ,显然不优。
思考优化。
发现性质 1: 的最大可能是 。
那么则可分情况:
- ,此时,有 。
- ,此时,需要重新遍历判解。
初步优化后 Code.
*by OI Wiki
CPPvector<int> prefix_function(string s) {
int n = (int)s.length();
vector<int> pi(n);
for (int i = 1; i < n; i++)
for (int j = pi[i - 1] + 1; j >= 0; j--) // improved: j=i => j=pi[i-1]+1
if (s.substr(0, j) == s.substr(i - j + 1, j)) {
pi[i] = j;
break;
}
return pi;
}
计算时间复杂度,由于性质 1,对于最大字符串比较次数的限制,可以看出每次只有在最好情况才会为字符串比较次数的上限积累 1,而每次超过一次的字符串比较消耗的是之后次数的增长空间。
那么可以构造数据,并得出当计算次数最多的时间复杂度:至少 次字符串比较次数的消耗和最多 次比较次数的积累,此时字符串比较次数为 ,此时总时间复杂度为 ,仍有优化空间。
*其实就是等效替代,不过这部分单看文字肯定很难看得懂,所以建议先翻到后面看具体过程,边看图片边理解,然后再翻上来看。
回推初步优化后,计算 的过程和目的:
设我们已经知道 ,尝试推出 。
首先,整理已知信息: 而我们需要寻求一个最大的长度 使 。
设我们已经知道 ,尝试推出 。
首先,整理已知信息: 而我们需要寻求一个最大的长度 使 。
然后,我们判断 是否等于 。
如果是,那么就是最大值。
如果不是,那么我们就需要找下一个长度 ,需要满足条件是: 尝试将条件拆解。
如果不是,那么我们就需要找下一个长度 ,需要满足条件是: 尝试将条件拆解。
- 。
注意第二个条件,容易发现,,所以 与 等价。同理,我们就可以推出一个关于 的方程:。
那么我们就可以递推得到最大满足条件的 。
具体过程:

首先,我们已知 ,,接下来,我们需要得到 的值,我们先设 为 。
然后我们判断, 是否与 相等,即 是否等于 。
不等。接下来,我们改变 的取值:,此时 为 ,判断, 是否与 相等,即 是否等于 。 退出递推,然后 。
首先,我们已知 ,,接下来,我们需要得到 的值,我们先设 为 。
然后我们判断, 是否与 相等,即 是否等于 。
不等。接下来,我们改变 的取值:,此时 为 ,判断, 是否与 相等,即 是否等于 。 退出递推,然后 。
那我们再来讨论什么时候 ,显然,当 且 使不存在相等的真前缀和真后缀,特别的,。
显然,时间复杂度为 。
Code.前缀函数
还是很简单的。
CPPfor(int i = 1;i < n;i ++){
int j = pi[i - 1];
while(j > 0 && s[j] != s[i]) j = pi[j - 1];
if(s[i] == s[j]) j ++;
pi[i] = j;
}
应用:字符串中查找子串(KMP)
将主串与模式串进行合并,将模式串作为前缀,且两串之间使用分隔符分隔。然后求出处理后的字符串的前缀函数,函数值为模式串的长度的数量
。
Code.KMP 模板
CPP#include<bits/stdc++.h>
using namespace std;
long long n;
string s1,s2,s3;
long long pi[N];
int main(){
cin >> s1 >> s2;
s3 = s2 + "#" + s1;
for(int i = 1;i < s3.size();i ++)
{
int j = pi[i - 1];
while(j > 0 && s3[i] != s3[j]) j = pi[j - 1];
if(s3[i] == s3[j]) j ++;
pi[i] = j;
}
for(int i = s2.size() + 1;i < s3.size();i ++)
if(pi[i] == s2.size())
cout << i - 2 * s2.size() + 1 << endl;
for(int i = 0;i < s2.size();i ++)
cout << pi[ i ]<<" ";
return 0;
}
应用:求解字符串周期
定义:
- 整数 是字符串 的周期当且仅当对于任何 满足 。
- 对于字符串 与整数 ,若 的长度为 的前缀与后缀相等时,称 是 的 border。
显然,根据定义,可以推出:若 是 的 border 时, 是 的周期。
那么我们可以通过前缀函数求出 的所有 border,即 。
其中,因为最大的 border 是 ,那么最小周期就是 。
应用:求解字符串前缀出现次数
分两种,一种是同一个字符串中求解前缀出现次数。另一种字符串不同。
先考虑第一种。根据前缀函数的定义, 表示以 为右端点的子串中出现了前缀 且不存在更长的前缀。而对于更短的前缀我们可以通过求解前缀函数时的做法来统计。
Code.统计前缀
OI WIKI 上比较简洁的实现。
CPPint ans[N];
for(int i = 0;i <= n;i ++) ans[pi[i]] ++;
for(int i = n;i >= 1;i --) ans[pi[i - 1]] += ans[i];
for(int i = 0;i <= n;i ++) ans ++;
应用:求解字符串本质不同的子串数目
考虑迭代求解答案,即先算出当前的答案,然后采取逐个添加的方式依次计算答案。
假设我们已知当前字符串 共有 个本质不同的子串。此时在 的末尾添加单个字符 ,思考如何计算增加的答案。
发现添加字符后,增加的子串数量是 ,即以添加字符为右端点的所有后缀。而我们只需要考虑这些后缀。
将改变后的字符串设为 ,根据以上的推理,不妨我们将其反转,那么根据前缀函数的定义,我们需要找到最大的 ,而更小的也一定出现过,那么增加的本质不同的子串就为 。
我们可以在 的时间下计算出每个字符的贡献,则总时间复杂度为 。
应用:通过前缀函数构造自动机。
首先回到 KMP 的问题背景:字符串匹配。我们的做法是通过以分隔符连接两个字符串,然后进行操作。
容易发现,对于主串中,参与单次计算的当前字符,上一个字符的前缀函数与模式串中前缀函数。那么我们就可以利用这个性质构造自动机。
Code.前缀函数构造自动机模板
CPPvoid compute_automaton(string s){
s += '#';
int n = s.size();
for(int i = 0;i < n;i ++)
for(int c = 0;c < 26;c ++)
if(i > 0&&c + 'a' != s[i]) aut[i][c] = aut[pi[i-1]][c];
else aut[i][c] = i + ('a'+c == s[i]);
}
应用有二:加速 KMP,以及处理规则构造的巨型字符串问题。
第一个应用显而易见,下面讲解第二个应用。
第一个应用显而易见,下面讲解第二个应用。
思考下面一个问题:给出一个整数 以及一个字符串 求第 个 Gray 字符串子串中 的个数。
Gray 字符串构造方式
首先,我们使用自动机解决该问题。
除了自动机外,我们需要处理: 表示从 状态开始处理 后的状态, 表示从 状态开始处理 后的答案。
思考如何得到这两个数组。
先是初始状态,显然,。
再根据 Grey 字符串的构造方式,得到 的转移:
同理也能得到 的转移。 *:当括号内表达式为正值为 ,否则为 。
再根据 Grey 字符串的构造方式,得到 的转移:
同理也能得到 的转移。 *:当括号内表达式为正值为 ,否则为 。
那么我们可以通过以上转移得到答案,时间复杂度为 ,常数为字符种类数量。
举一反三地,我们可以通过以上方式解决更多类似的问题。
应用:失配树
我们在求解 KMP 的 数组时,我们可以发现具有树形结构,那么我们就可以根据 数组进行连边,然后进行操作。
Code.失配树模板
CPPlong long fa[N][35];
long long dep[N];
void KMP(string s){
vector<int> pi(s.size());
long long len = s.size();
for(int i = 2,j = 0;i < len;i ++){
while(j > 0 && s[i] != s[j+1]) j = fa[j][0];
if(s[i] == s[j+1]) j ++;
fa[i][0] = j,dep[i] = dep[j] + 1;
}
}
Z 函数(拓展 KMP)
与 KMP 类似的算法。
Z 函数求解的是字符串 内每一段后缀与自身或其它字符串的最长公共前缀。
那么我们从 的思路出发,怎么样从前面的状态推出下一个状态?
我们定义这样的一个数组: 表示模式串 以 开头的后缀与 的最长公共前缀。
因为大部分讲解不那么友好,所以我写了一个自己能看懂的。
当前,我们字符处理后的可视化状态为:
 首先,我们知道两个蓝色方框内的字符串相等。
首先,我们知道两个蓝色方框内的字符串相等。
首先,我们知道两个蓝色方框内的字符串相等。 这时,我们需要求解绿色分割线后的后缀与整个字符串的公共前缀。
这时,我们需要求解绿色分割线后的后缀与整个字符串的公共前缀。根据我们已经处理的情况,可以得到两个绿色方框内的字符串相等。
那么我们就可以进行等价替换:
因为我们已经处理了第一个绿色方框及后面组成的后缀与整个字符串的最大公共前缀。
所以我们可以再次用灰色方框框起来,根据它的长度进行分类讨论。
当灰色方框的长度小于绿色方框:

那么我们就可以再次进行替换,可以得到,图中的三个灰色方框内的字符串相等,所以此时 的值就是灰色方框的长度。
那么我们就可以再次进行替换,可以得到,图中的三个灰色方框内的字符串相等,所以此时 的值就是灰色方框的长度。
当灰色方框的长度大于绿色方框:

根据定义,前面两个灰色方框内的字符串相等,而后一个字符串中,黑色方框内的字符串未判定,所以我们需要暴力判定求解。
根据定义,前面两个灰色方框内的字符串相等,而后一个字符串中,黑色方框内的字符串未判定,所以我们需要暴力判定求解。
那么我们画图理解后,将其带入到实际问题。
先思考一个问题:蓝色的方框应该如何选取?
显然,肯定是右端点越远越好,因为右端点更远的蓝色方框会产生更大的绿色方框,那么就更有可能得到第一种情况,所以我们需要记录右端点最远的方框。
形式化的表达:对于 ,我们需要找到最大的 ,设其为 ,并记录 为与之对于的 。
形式化的表达:对于 ,我们需要找到最大的 ,设其为 ,并记录 为与之对于的 。
那么我们就可以用这些符号表示上面所对应的框。

根据上述的算法流程:
- 已经处理完 以及 ,我们需要求出 。
- 判断 是否大于 。
- 如果小于,直接赋值:。
- 否则从 一直往后枚举,直到与前面的不相等。由于此时已经向后拓展了,所以我们需要更新 。
时间复杂度分析:
第二种情况会让 的位置不断向后移,而 。所以总的时间复杂度是 。
第二种情况会让 的位置不断向后移,而 。所以总的时间复杂度是 。
处理完单个串,那么两个串之间匹配呢?
骗你的其实是一样的。
Code.Z函数(拓展 KMP)模板
CPPstring a,b;
vector<ll> generate_Z(string s){
vector<ll>z(s.size());
ll k = 1,n = s.size(),p;
z[0] = n;
while(z[1] + 1 < n && s[z[1]] == s[z[1] + 1]) z[1] ++;
for(int i = 2;i < n;i ++){
p=k + z[k] - 1;
if(z[i - k] <= p - i) z[i] = z[i - k];
else{
ll j = max(0ll , p-i+1);
while(i+j < n && s[i + j] == s[j]) j ++;
k = i,z[i] = j;
}
}
ll ans = 0;
for(int i = 0;i < n;i ++)
ans^=(i + 1) * (z[i] + 1);
cout << ans << endl;
return z;
}
void generate_p(string a,string b){
vector<ll> z = generate_Z(b);
vector<ll> e(a.size());
ll k = 0,la = a.size(),p,lb = b.size();
while(e[0] < la && e[0] < lb && a[e[0]] == b[e[0]]) e[0] ++;
for(int i = 1;i < la;i ++){
p = k + e[k] - 1;
if(z[i - k] <= p - i) e[i] = z[i - k];
else{
ll j = max(0ll,p - i + 1);
while(i + j < la && j < lb && a[i + j] == b[j]) j ++;
k = i,e[i] = j;
}
}
ll ans = 0;
for(int i = 0;i < e.size();i ++)
ans ^= (i + 1) * (e[i] + 1);
cout << ans;
return;
}
Manacher
线性处理字符串中每个回文串的半径信息。
首先,我们先将回文串根据奇偶性分为两类,然后定义两个数组: 分别表示以 为中心的奇/偶数长度的最大回文串的半径。
我们可以应用上述思想:等效替代。借助前面的信息有效处理当下的情况,先处理长度为奇数的回文昌,而偶数的差不多。具体是这样的。
先记录前面的所有回文串中右端点最靠右的回文串的两端位置 。
首先,当前位置 不可能在 与 的中点的左边。然后根据回文串的定义,我们可以根据当前位置 与 的关系进行讨论。
对于 的情况,我们进行拓展操作:直接枚举 右边的字符,直到出现不满足回文的性质。
 此时 将会更新。
此时 将会更新。
此时 将会更新。然后,对于 的情况:
 我们可以给 关于 中点做一个对称操作,对称后得到 ,用橙框标出回文串范围:
我们可以给 关于 中点做一个对称操作,对称后得到 ,用橙框标出回文串范围:

当橙框范围没有超过红框,那么此时 。 否则:

此时因为超过了前面回文的特质,我们无法保证超出范围的字符一定能够满足条件,所以我们需要进行拓展操作。
我们可以给 关于 中点做一个对称操作,对称后得到 ,用橙框标出回文串范围:当橙框范围没有超过红框,那么此时 。 否则:
此时因为超过了前面回文的特质,我们无法保证超出范围的字符一定能够满足条件,所以我们需要进行拓展操作。
偶数长度亦如此。
但是,虽然我们按照奇偶性分了类,但是我们可以通过一些技巧将其整合:
我们将原字符串 的字符间插入分隔符
我们将原字符串 的字符间插入分隔符
# 的得到 ,然后就可以直接根据 来推出来总长度了: 中 位置在 对于的回文串长度为 。Code.Manacher 模板
CPPlen=s1.size();
for(int i = 0;i < len;i ++)
s += '#',s += s1[i];
s += '#',n = s.size();
for(int i = 0;i < n;i ++){
int k=(i > r)?1:min(d1[l + r - i],r - i + 1);
while(0 <= i - k && i + k < n && s[i - k] == s[i + k]) k ++;
d1[i] = k --;
if(i+k > r) l = i - k,r = i + k;
}
AC 自动机
解决多模式串匹配的线性算法。
在 Trie 上应用 KMP 思想。
下列的讨论,提及 节点,若无特殊说明,则所指的为从根节点到 节点所连成的字符串。
其实实际上就是一个 Trie,不过在 Trie 原有的边的基础上添加了一种指针 ,指向 Trie 图中出现的对于 节点 的最长后缀。
那么我们就可以通过遍历文本串时 指针的快速跳转,快速得到文本串中 Trie 中有的字符串,从而我们可以统计出每一个模式串出现的次数。
那么我们就可以通过遍历文本串时 指针的快速跳转,快速得到文本串中 Trie 中有的字符串,从而我们可以统计出每一个模式串出现的次数。
然后我们利用这种性质进行字符串的匹配及其统计。
接下来将模拟 AC 自动机的过程与优化。
首先,我们第一步是将模式串建 Trie。
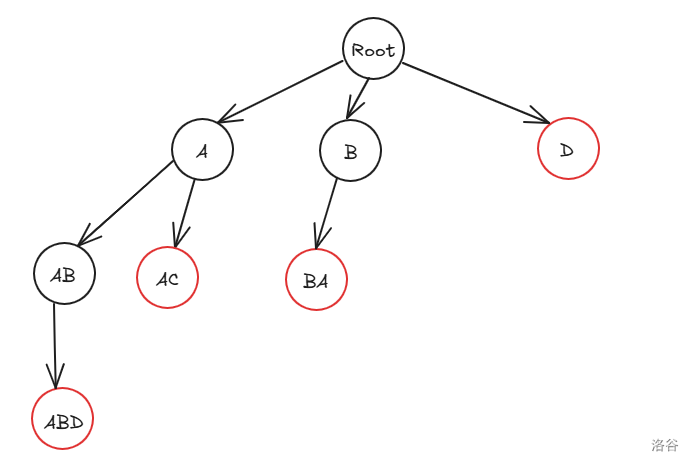
接下来,我们先考虑如何得到 。
类比 KMP,我们可以从前面的状态推到当前状态。
假设:我们已经知道深度小于当前节点 的所有 ,思考,如何得到 。
假设:我们已经知道深度小于当前节点 的所有 ,思考,如何得到 。
有一个想法,就是当前 可以继承父节点的 ,即 ,然后从 的子节点中找有没有当前的后缀,
如果有,那么肯定就是最大后缀。
如果没有,那么我们就需要继续跳 直到得到后缀。
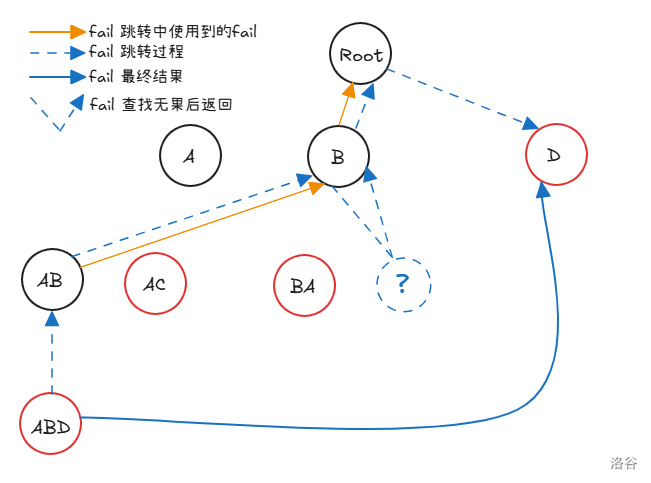
如果有,那么肯定就是最大后缀。
如果没有,那么我们就需要继续跳 直到得到后缀。
显然,我们可以从初始状态 推出所有状态。
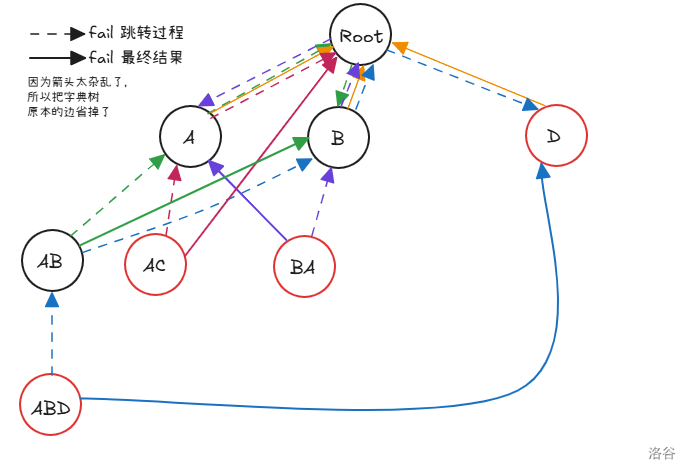
我们先来分析一下时间复杂度。最大单次跳转次数是 ,而我们需要跳转 次。那么总的时间复杂度为 ,比最朴素的多模式匹配算法复杂度 更优。
但是仍有优化空间。
思考,耗费时间主要在哪一步上?显然,跳转 无法优化,而单次的跳转却没有完全发挥。
为什么会导致跳转次数的增加?是因为我们跳到一个字符串时我们发现一个字符串不存在,我们就只能往上跳一次,继续遍历。如果这个字符串一开始就存在,那我们就可以直接得到最大后缀。
那么我们能不能一开始就假定所有字符串存在,然后我们跳转跳到不存在的字符串时我们指向一个存在的字符串(正确性显然)。
可以的。建立虚拟点。
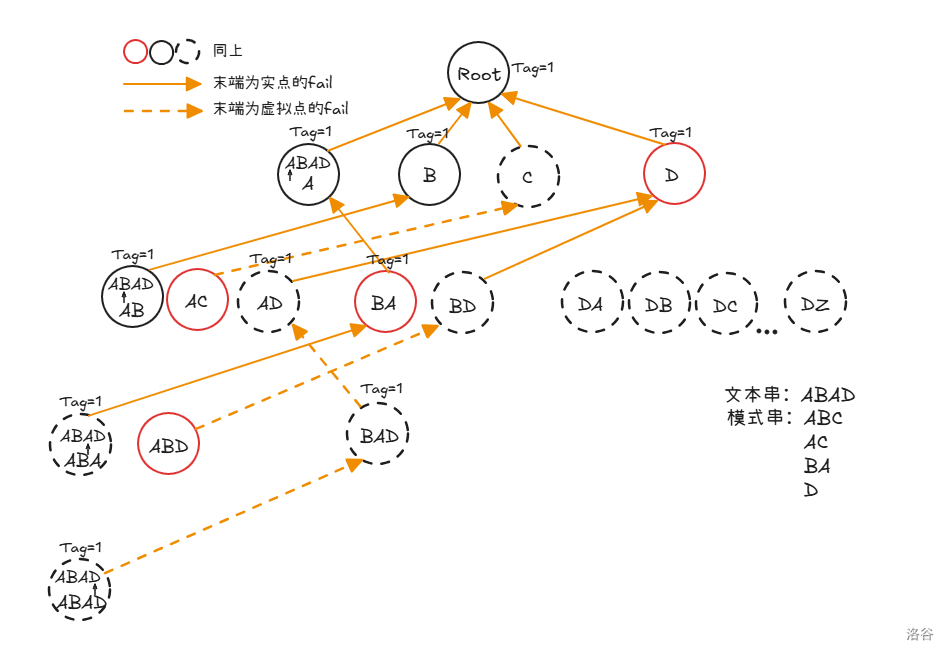
假定所有的点存在,然后我们将所有点的 求出,然后再记录能够跳到的第一个实点作为真正的 。
那么这样子我们就可以 得到了 了。
具体是这样的:
没有虚拟点时:
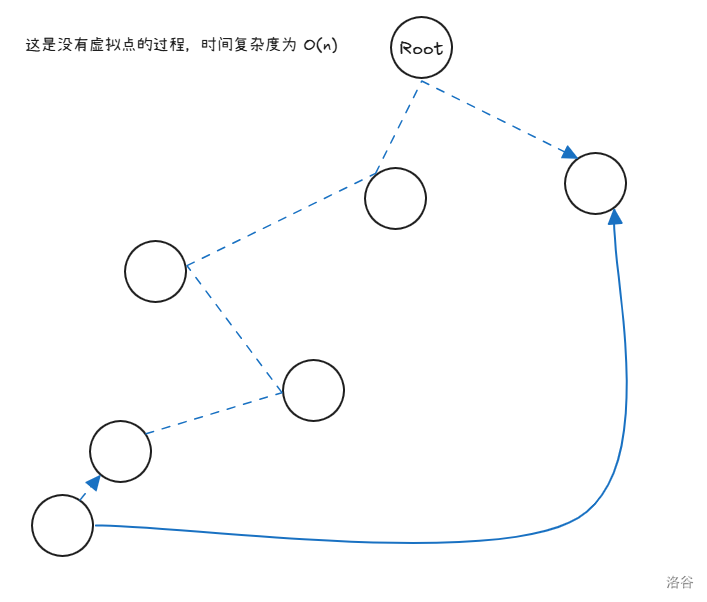
图中的虚线我们需要耗费时间真正的去跳转,因为我们没法预处理下一次跳转会到哪里。
有虚拟点时:
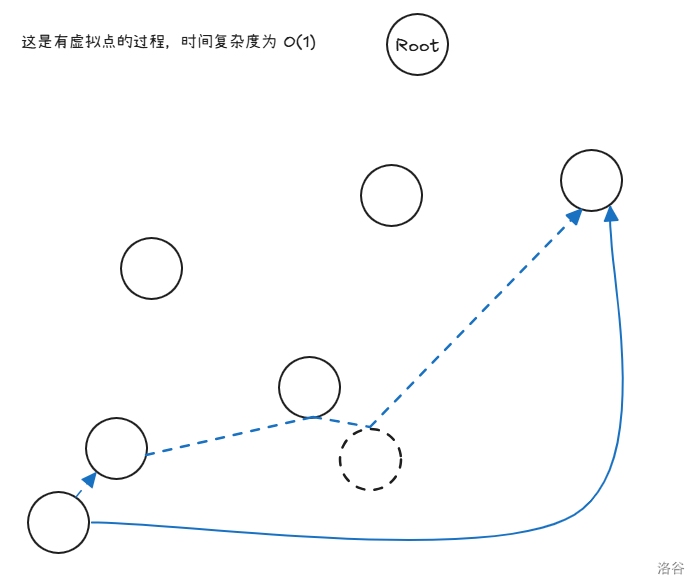
图中的虚线我们不需要真正的完全跳转,我们只需要只跳转前面两条,然后就可以自动跳转到最后了。
那么接下来,我们需要进行查询操作。
我们根据文本串在字典树遍历一条路径。
然后从每一个路径上的节点进行暴力跳转,然后给跳转碰到的节点打上标记,直到到达根节点或者碰到标记过的节点时停止。
这个时候我们就可以统计是否出现了。
但是又应该怎么统计次数。
一种显然的想法:我们碰到标记过的节点不退出,而是让 增加 ,而模式串的标记值就是在文本串中出现的次数。
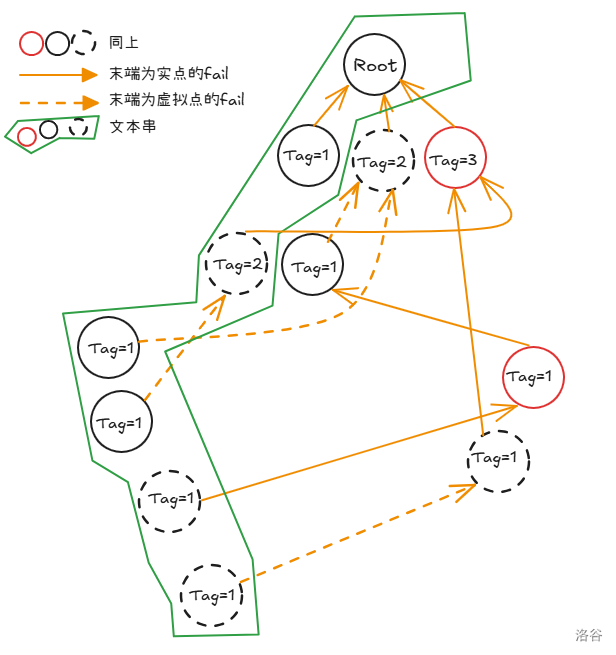
但是这个时候的时间复杂度会因为重复跳转而退化成 。
继续观察,我们可以发现,每一个 指向的只能是深度比它小的节点,因为不存在长度大于等于 的字符串是 的前缀。
那么我们就可以将这些 挑出来,然后进行一个拓扑排序。
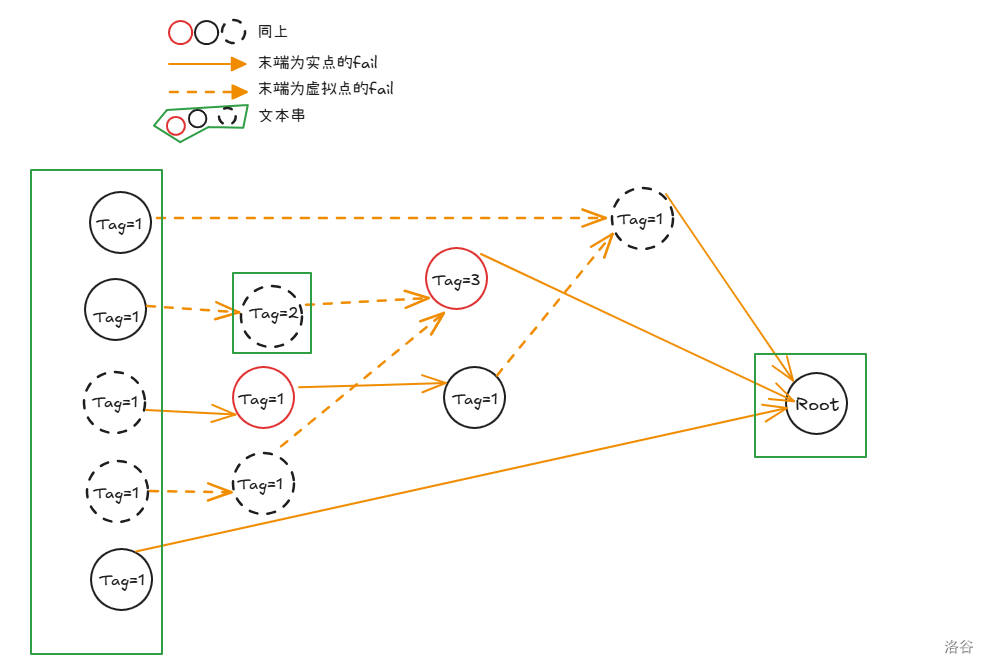
然后给文本串路径上的节点 设为 ,然后像前缀和一样往后传递。
最后每个模式串的 就是答案。
Code.AC自动机
CPP#include<bits/stdc++.h>
using namespace std;
const int N=2e5+10;
int n,len;
string s,x;
struct trie{
int fail,flag,tag,son[35];
}t[N];
int vis[N],in[N],back[N],cnt=1;
void build(string s,int q){//字典树插入字符串
int pos=1,len=s.size();
for(int i=0;i<len;i++){
if(!t[pos].son[s[i]-'a']) t[pos].son[s[i]-'a']=++cnt;
pos=t[pos].son[s[i]-'a'];
}
if(!t[pos].flag) t[pos].flag=q;
back[q]=t[pos].flag;//用于输出
return;
}
void build_fail(){
for(int i=0;i<=30;i++) t[0].son[i]=1;//减少一些特判
queue<int>q;
t[1].fail=0,q.push(1);
while(!q.empty()){//bfs 建立 fail 指针
int tmp=q.front();
q.pop();
for(int i=0;i<26;i++){
int v=t[tmp].son[i];
if(!v){
t[tmp].son[i]=t[t[tmp].fail].son[i];//建立虚点指针,虚点间可以一次性跳
continue;
}
t[v].fail=t[t[tmp].fail].son[i];//继承父节点的指针
in[t[v].fail]++;//统计入度方便拓扑
q.push(v);
}
}
return;
}
void query(string s){
int pos=1,len=s.size();
for(int i=0;i<len;i++)
pos=t[pos].son[s[i]-'a'],t[pos].tag++;//增加路径上的节点 tag
return;
}
void topo(){//拓扑快速统计模式串出现次数。
queue<int>q;
for(int i=1;i<=cnt;i++) if(in[i]==0)q.push(i);
while(!q.empty()){
int tmp=q.front();
q.pop();
vis[t[tmp].flag]=t[tmp].tag;
int x=t[tmp].fail;
in[x]--,t[x].tag+=t[tmp].tag;
if(in[x]==0)q.push(x);
}
return;
}
int main(){
cin>>n;
for(int i=1;i<=n;i++) cin>>x,build(x,i);
cin>>s;
build_fail(),query(s),topo();
for(int i=1;i<=n;i++)
cout<<vis[back[i]]<<endl;
return 0;
}
好的,到这里这一部分的就结束了,我有一些话想说:
- 关于单格缩进:
受邪教影响。不知道为什么在代码块里当单行里东西太多的时候就会自动换行,就算我不加空格也是这样的,这没办法,虽然单格缩进很丑,但是自动换行更丑。考虑到有一些朋友想要将模板复制下来,所以下面的模板总结我并没有使用单格缩进和空格分隔运算符。 - 字符串的话我应该会划分为 个部分,这是第一部分,然后我应该会用一整个专栏来写后缀数组、后缀自动机等相关的东西(其实到现在我还不怎么会,所以放到后面)作为第二部分,然后第三部分就把剩下的那些杂七杂八的东西结束掉。
- 碎碎念:其实写这篇专栏的时候还是有一些感触的,虽然我在 OI 上的经历并不一帆风顺,然后兴趣啥的也被消磨了很多,不过既来之则安之,既然学了 OI,那么起码也要为这里做些什么,因为自己现在还是一个彩笔,所以也就只能做做整理之类的东西,以后的事以后再说吧。
模板集合
模板们(Part 1.)
Code.Trie 模板
CPPstruct Trie{
bool bj[N];
long long nxt[N][26],cnt;
void add(string s){
int p=0;
for(int i=0;i<s.size();i++){
if(!nxt[p][s[i]-'a']) nxt[p][s[i]-'a']=++cnt;
p=nxt[p][s[i]-'a'];
}
bj[p]=1;
}
bool query(long long s){
int p=0;
for(int i=0;i<s.size();i++){
if(!nxt[p][s[i]-'a']) return 0;
p=nxt[p][s[i]-'a'];
}
if(bj[p]) return 1;
return 0;
}
}trie;
Code.前缀函数模板
CPP#include<bits/stdc++.h>
using namespace std;
string s;
long long pi[100005],n;
int main(){
cin>>s,n=s.size();
for(int i=1;i<n;i++){
int j=pi[i-1];
while(j>0 && s[j]!=s[i]) j=pi[j-1];
if(s[i]==s[j]) j++;
pi[i]=j;
cout<<j<<endl;
}
return 0;
}
Code.KMP 模板
CPP#include<bits/stdc++.h>
using namespace std;
long long n;
string s1,s2,s3;
long long pi[100000010];
int main(){
cin>>s1>>s2;
s3=s2+"#"+s1;
for(int i=1;i<s3.size();i++)
{
int j=pi[i-1];
while(j>0 && s3[i]!=s3[j]) j=pi[j-1];
if(s3[i]==s3[j]) j++;
pi[i]=j;
}
for(int i=s2.size()+1;i<s3.size();i++)
if(pi[i]==s2.size())
cout<<i-2*s2.size()+1<<endl;
for(int i=0;i<s2.size();i++)
cout<<pi[i]<<" ";
return 0;
}
Code.失配树模板
CPPlong long fa[N][35];
long long dep[N];
void KMP(string s){
vector<int>pi(s.size());
long long len=s.size();
for(int i=2,j=0;i<len;i++){
while(j>0 && s[i]!=s[j+1]) j=fa[j][0];
if(s[i]==s[j+1]) j++;
fa[i][0]=j,dep[i]=dep[j]+1;
}
}
Code.前缀函数构造自动机模板
CPPvoid compute_automaton(string s){
s+='#';
int n=s.size();
for(int i=0;i<n;i++)
for(int c=0;c<26;c++)
if(i>0&&c+'a'!=s[i]) aut[i][c]=aut[pi[i-1]][c];
else aut[i][c]=i+('a'+c==s[i]);
}
Code.Z函数(拓展 KMP)模板
CPPstring a,b;
vector<ll> generate_Z(string s){
vector<ll>z(s.size());
ll k=1,n=s.size(),p;
z[0]=n;
while(z[1]+1<n && s[z[1]]==s[z[1]+1]) z[1]++;
for(int i=2;i<n;i++){
p=k+z[k]-1;
if(z[i-k]<=p-i) z[i]=z[i-k];
else{
ll j=max(0ll,p-i+1);
while(i+j<n && s[i+j]==s[j]) j++;
k=i,z[i]=j;
}
}
ll ans=0;
for(int i=0;i<n;i++)
ans^=(i+1)*(z[i]+1);
cout<<ans<<endl;
return z;
}
void generate_p(string a,string b){
vector<ll>z=generate_Z(b);
vector<ll>e(a.size());
ll k=0,la=a.size(),p,lb=b.size();
while(e[0]<la && e[0]<lb && a[e[0]]==b[e[0]]) e[0]++;
for(int i=1;i<la;i++){
p=k+e[k]-1;
if(z[i-k]<=p-i) e[i]=z[i-k];
else{
ll j=max(0ll,p-i+1);
while(i+j<la && j<lb && a[i+j]==b[j]) j++;
k=i,e[i]=j;
}
}
ll ans=0;
for(int i=0;i<e.size();i++)
ans^=(i+1)*(e[i]+1);
cout<<ans;
return;
}
Code.Manacher 模板
CPPlen=s1.size();
for(int i=0;i<len;i++)
s+='#',s+=s1[i];
s+='#',n=s.size();
for(int i=0;i<n;i++){
int k=(i>r)?1:min(d1[l+r-i],r-i+1);
while(0<=i-k && i+k<n && s[i-k]==s[i+k]) k++;
d1[i]=k--;
if(i+k>r) l=i-k,r=i+k;
}
Code.AC自动机模板
CPP#include<bits/stdc++.h>
using namespace std;
const int N=2e5+10;
int n,len;
string s,x;
struct trie{
int fail,flag,tag,son[35];
}t[N];
int vis[N],in[N],back[N],cnt=1;
void build(string s,int q){//字典树插入字符串
int pos=1,len=s.size();
for(int i=0;i<len;i++){
if(!t[pos].son[s[i]-'a']) t[pos].son[s[i]-'a']=++cnt;
pos=t[pos].son[s[i]-'a'];
}
if(!t[pos].flag) t[pos].flag=q;
back[q]=t[pos].flag;//用于输出
return;
}
void build_fail(){
for(int i=0;i<=30;i++) t[0].son[i]=1;//减少一些特判
queue<int>q;
t[1].fail=0,q.push(1);
while(!q.empty()){//bfs 建立 fail 指针
int tmp=q.front();
q.pop();
for(int i=0;i<26;i++){
int v=t[tmp].son[i];
if(!v){
t[tmp].son[i]=t[t[tmp].fail].son[i];//建立虚点指针,虚点间可以一次性跳
continue;
}
t[v].fail=t[t[tmp].fail].son[i];//继承父节点的指针
in[t[v].fail]++;//统计入度方便拓扑
q.push(v);
}
}
return;
}
void query(string s){
int pos=1,len=s.size();
for(int i=0;i<len;i++)
pos=t[pos].son[s[i]-'a'],t[pos].tag++;//增加路径上的节点 tag
return;
}
void topo(){//拓扑快速统计模式串出现次数。
queue<int>q;
for(int i=1;i<=cnt;i++) if(in[i]==0)q.push(i);
while(!q.empty()){
int tmp=q.front();
q.pop();
vis[t[tmp].flag]=t[tmp].tag;
int x=t[tmp].fail;
in[x]--,t[x].tag+=t[tmp].tag;
if(in[x]==0)q.push(x);
}
return;
}
int main(){
cin>>n;
for(int i=1;i<=n;i++) cin>>x,build(x,i);
cin>>s;
build_fail(),query(s),topo();
for(int i=1;i<=n;i++)
cout<<vis[back[i]]<<endl;
return 0;
}
相关推荐
评论
共 10 条评论,欢迎与作者交流。
正在加载评论...