专栏文章
AC自动机 学习笔记
算法·理论参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @miqosil4
- 此快照首次捕获于
- 2025/12/04 08:17 3 个月前
- 此快照最后确认于
- 2025/12/04 08:17 3 个月前
AC 自动机
AC 自动机这个东西折磨了我好久,第一次写文章,记录一下,如有哪里笔误请在评论区留言,轻喷 QAQ。
引言
- 这是一种用于多个字符串与同一个文本串匹配的算法,整体运用到了 kmp 和字典树的思想。
实现
定义
CPPstruct node {
int fail; // 失配指针
int son[26]; // 当前节点所连接的子节点编号,分别对应26个字母
int id; // 以这个节点结尾的字符串编号
int count; // 标记有几个单词以这个节点结尾
} t[maxn];
此处重点说一下 ,状态 的 所指向的 是 的最长后缀,换句话说,我们去匹配的是所有模式串的前缀和当前前缀公共后缀最长的一个,我们的 kmp 算法里也有一个类似的 指针,不同的是 可能指向别的字符串的节点。
建树
- 就是建一颗字典树,这里放一下图和代码:
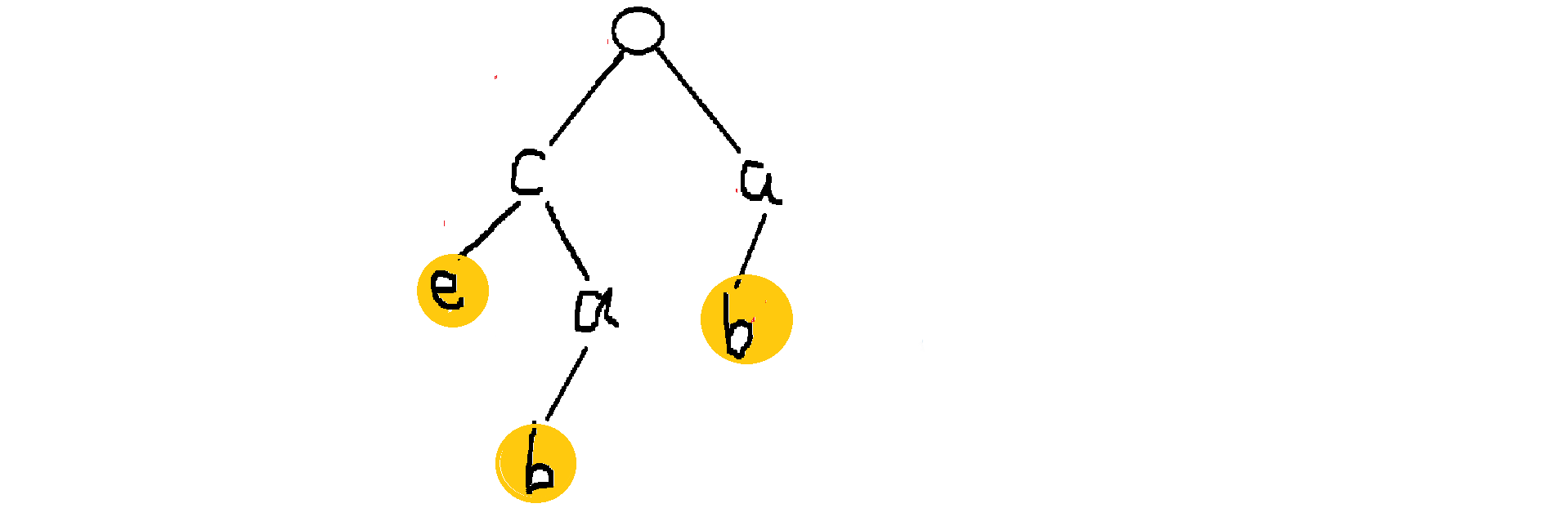 黄色节点标注的就是模式串的结尾,这颗树上一共存储了三个字符串,分别是
黄色节点标注的就是模式串的结尾,这颗树上一共存储了三个字符串,分别是 ce cab ab。
void build(string x) {
int m = x.size();
int now = 0;
for (int i = 0; i < m; ++i) {
if (t[now].son[x[i] - 'a'] == 0) {
t[now].son[x[i] - 'a'] = ++tot;
// 这里的tot是节点编号
}
now = t[now].son[x[i] - 'a'];
}
}
这是最基础的,按照我们的题目所求会用到上文所求的另外两个变量,下面给出几个例子:
-
求有多少个不同的模式串在文本串里出现过(可能会有重复模式串):CPP
++t[now].count;相同的字符串就被累加起来了,因为最终答案和字符串的编号无关,所以直接累加就好。 -
求每个模式串在文本串中出现的次数(保证没有重复模式串):CPP
t[now].id = k; // k 是这个字符串的编号这就是一个和编号相关的问题,但是保证没有重复,但如果即和编号有关又可能出现重复的话我们就要改成下面这样的:CPPif (t[now].id == 0) { t[now].id = k; } um[k] = t[now].id;这里的 代表这个字符串编号, 是一个 map,因为所有的相同字符串最终答案必定一样,我们这里相当于去重了,而 一定是 ,我们就没有特地再记录一下的必要了。上述的代码分别对应了三个 AC 自动机的模板,其中第二个题目有改动,但是代码是一样的。
求 fail 指针
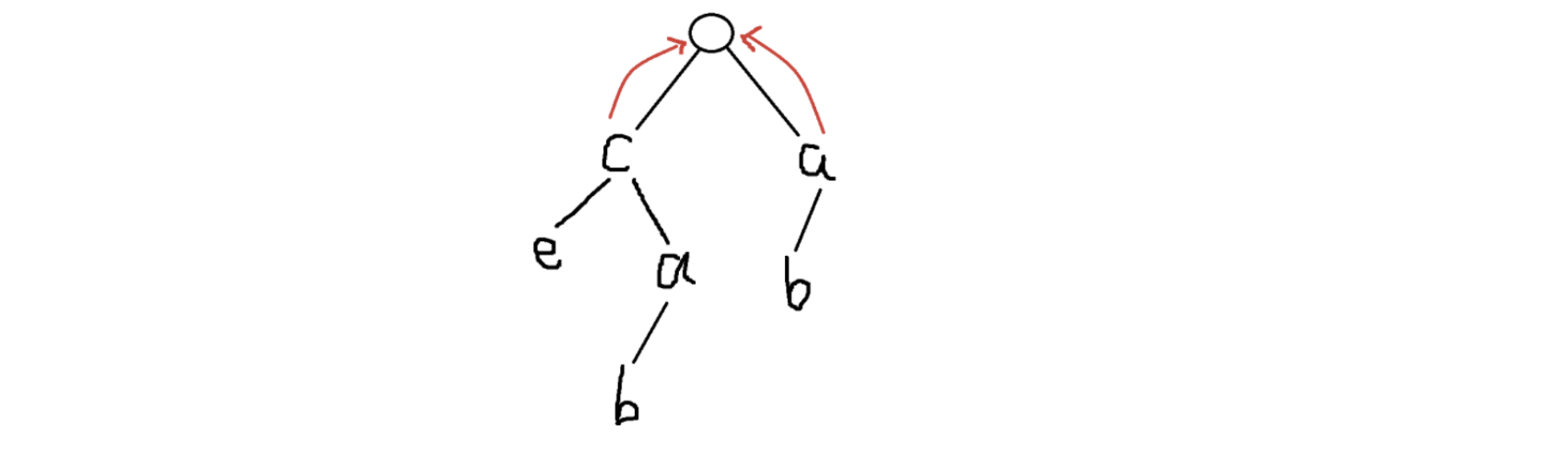
这里我们用了一种类似 bfs 的方法去完成,从 的定义我们可以发现,一个字符串的起点位置无论如何都不可能有前缀,所以这些点一定指向根,这里图中的红色边就是 边。
 然后我们继续向下扩展。
然后我们继续向下扩展。
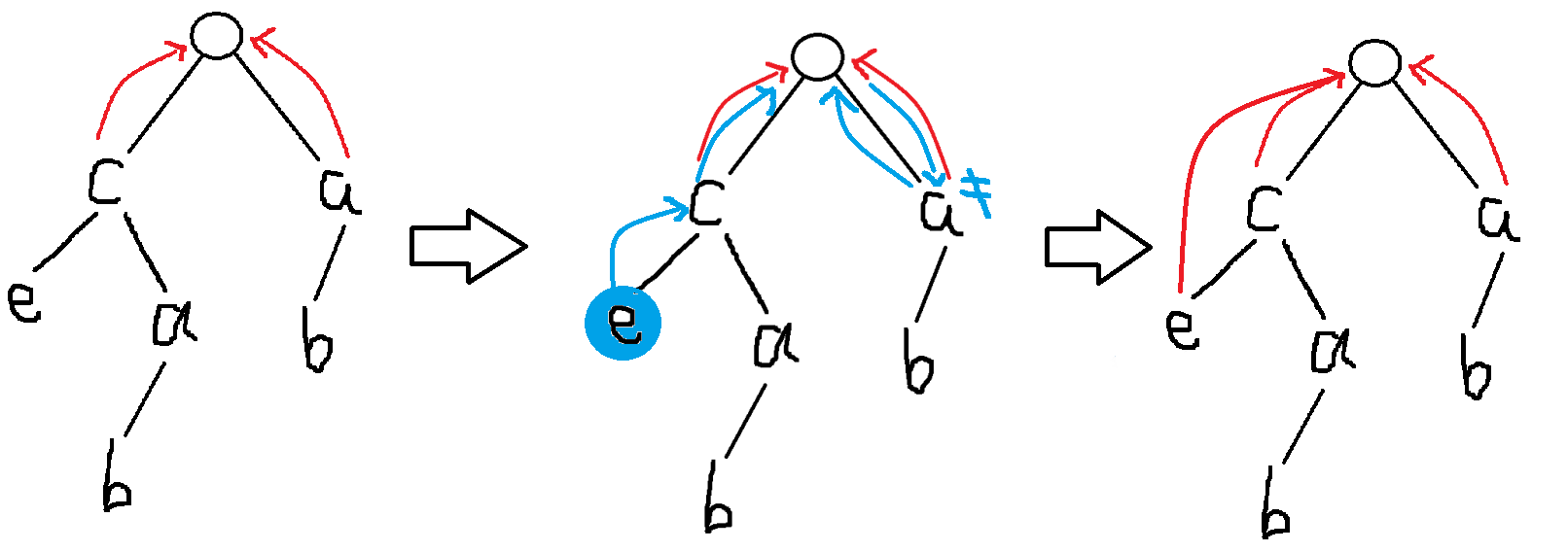 这里我们去求了图中这个蓝色的 的 指针,具体流程是,我们跳转到父节点的 ,然后看它的子节点中有没有和我相同的节点,有的话就连一条边,没有就连到根上,注意不是连父亲的 ,最终我们连出来的就是这样的。
这里我们去求了图中这个蓝色的 的 指针,具体流程是,我们跳转到父节点的 ,然后看它的子节点中有没有和我相同的节点,有的话就连一条边,没有就连到根上,注意不是连父亲的 ,最终我们连出来的就是这样的。
 其他的点可以遵循上述流程模拟一遍。
其他的点可以遵循上述流程模拟一遍。
然后我们继续向下扩展。
这里我们去求了图中这个蓝色的 的 指针,具体流程是,我们跳转到父节点的 ,然后看它的子节点中有没有和我相同的节点,有的话就连一条边,没有就连到根上,注意不是连父亲的 ,最终我们连出来的就是这样的。
其他的点可以遵循上述流程模拟一遍。而我们遍历时也可能遇到一种情况就是我们遍历到的这个子节点不存在,那么我们可以把这个点的子节点连到它 的对应子节点上,这里不难理解,可以自己手绘一下,不作过多赘述。
放一下这个部分的代码:
CPPvoid get() {
queue<int> q;
for (int i = 0; i < 26; ++i) {
if (t[0].son[i] != 0) {
t[t[0].son[i]].fail = 0;
q.push(t[0].son[i]);
}
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; ++i) {
if (t[u].son[i] != 0) {
t[t[u].son[i]].fail = t[t[u].fail].son[i];
// 如果没有匹配上,因为值默认是0,所以也会指向根节点
q.push(t[u].son[i]);
} else {
t[u].son[i] = t[t[u].fail].son[i];
}
}
}
}
匹配
CPPvoid match(string x) {
int m = x.size();
int now = 0;
for (int i = 0; i < m; ++i) {
now = t[now].son[x[i] - 'a'];
for (int j = now; j; j = t[j].fail) {
// 分题目
}
}
}
整体框架就是这样的,在第二层循环里我们可以通过 把所有前缀能匹配上的字符串都扫一遍这个东西我觉得它长得很像链式前向星,而中间的部分分不同的题目有不同的内容。
举几个例子:
-
CPP
++cnt[t[j].id];输出每个字符串的匹配次数,如果要排序的话可以用 pair 或结构体解决。 -
CPP
ans += t[j].count; t[j].count = -1;统计有多少个可以匹配的模式串,注意这里因为我们要避免重复计算,所以第二层循环的条件里要加上一个关于 的条件,具体是这个样子:CPPint j = now; j && t[j].count!= -1; j = t[j].fail
拓扑优化
拓扑优化版本的 AC 自动机和我们上面写的略有不同,下面依旧从建树、求 指针和匹配三部分来讲。
放在前言
-
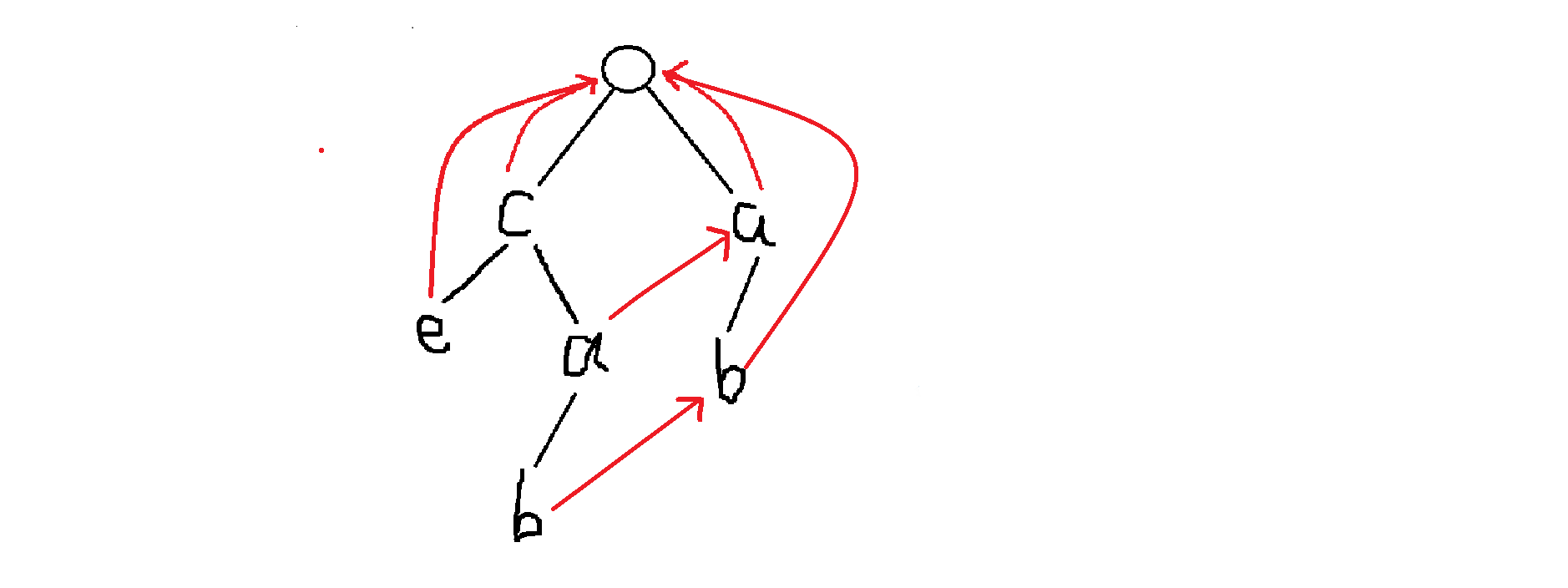
我们为什么需要这个优化?因为我们可能会重复更新一个点多次,造成损失,这里再放一个新图理解一下:
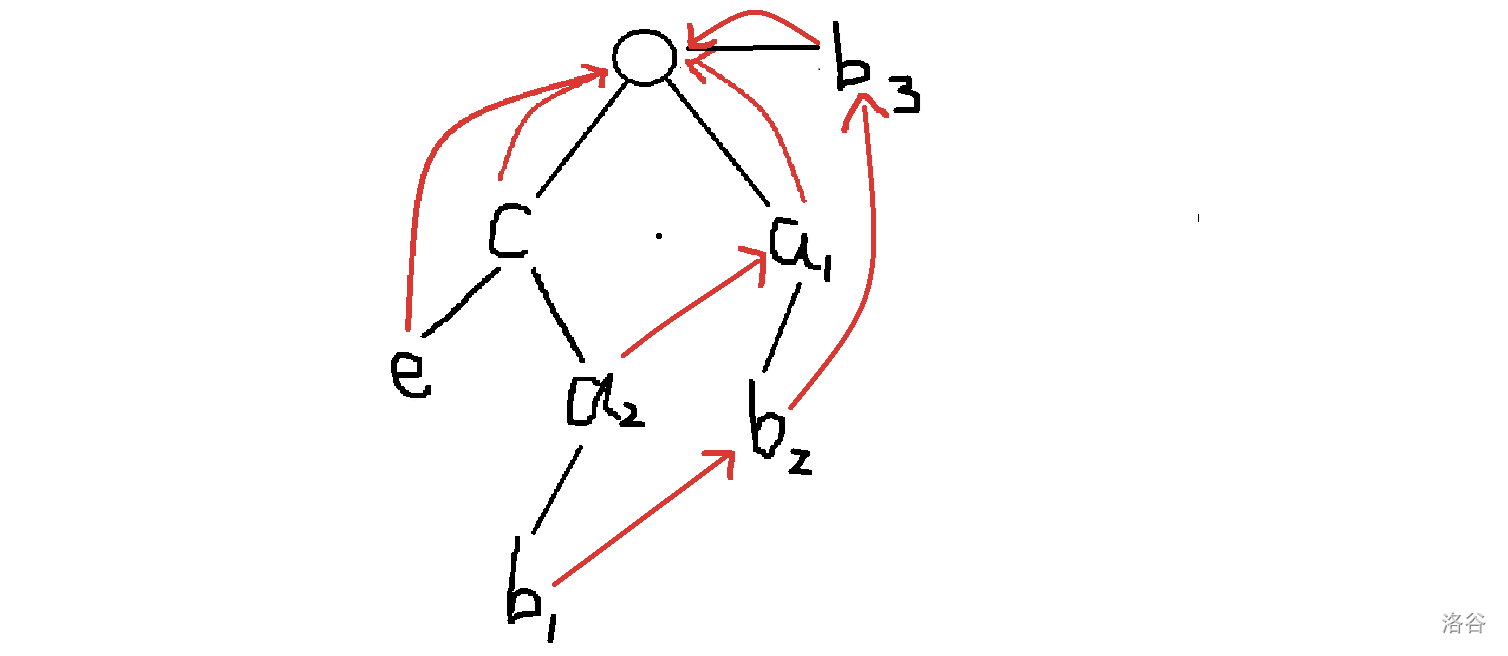
在这个图里面,我们走到 和 的时候都要更新 ,所以我们思考有没有只更新一次的做法,而这个时候,聪明的我们发现图中的红色边不就正好构成了一个树形结构吗,我们把这个部分拿出来单独拆解,为了对照方便,我们给原图里字符相同的点都编个号: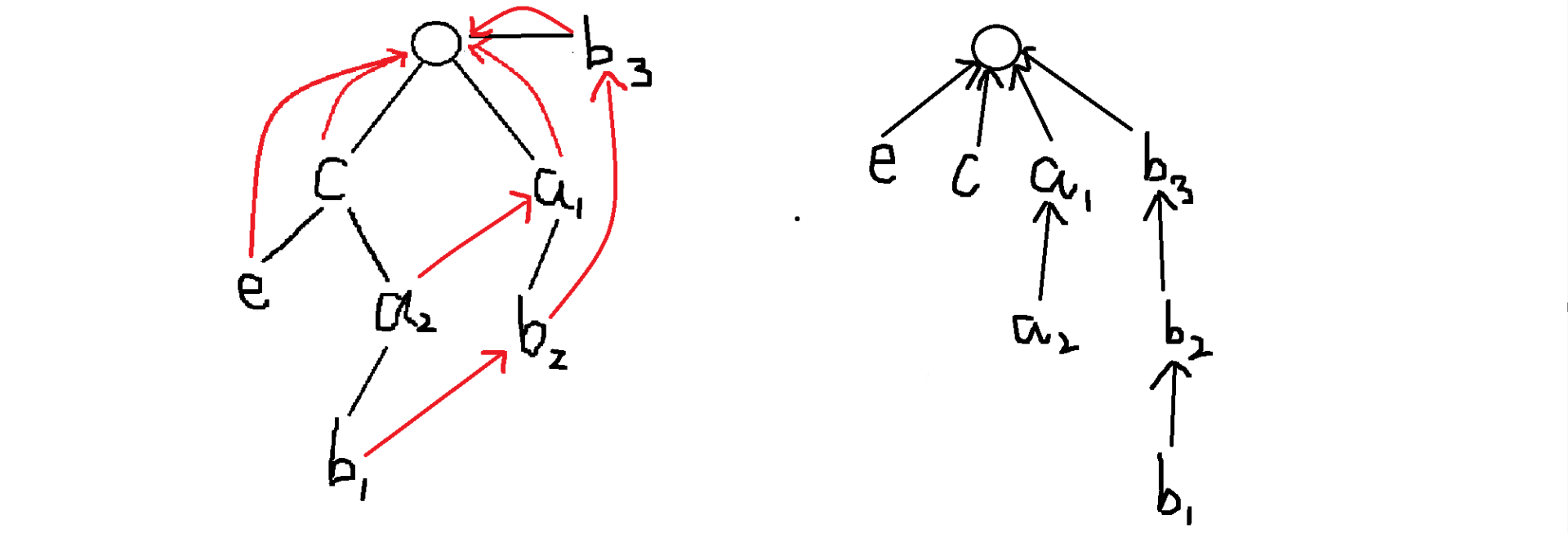 只不过方向似乎是反的,但是这个东西一定不构成环,那我们就想到了拓扑排序。
只不过方向似乎是反的,但是这个东西一定不构成环,那我们就想到了拓扑排序。
只不过方向似乎是反的,但是这个东西一定不构成环,那我们就想到了拓扑排序。建树
所以我们在前文里曾经在
CPPbuild 里要加的那一句就变成了这个,此处我们用 vector 来记录以当前节点结尾的模式串编号: g[now].push_back(k);
求 fail 指针
和上面的代码只有一行不同,是很基本的记录入度:我们把
++in[t[t[u].son[i]].fail]; 加在 while 里面 for 循环的 if 句里,就是当这个子节点存在时我们要更新 ,所以要记录入度。匹配
遵循拓扑的经典套路,判入度为 的点然后放进队列里跑就好,这里我们先放一下代码,结合代码来讲这一部分:
CPPvoid match(string x) {
int m = x.size();
int now = 0;
for (int i = 0; i < m; ++i) {
now = t[now].son[x[i] - 'a'];
++w[now];
}
queue<int> q;
for (int i = 1; i <= tot; ++i) {
if (!in[i]) {
q.push(i);
}
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (auto v : g[u]) {
ans[v] = w[u];
}
w[t[u].fail] += w[u];
--in[t[u].fail];
if (!in[t[u].fail]) {
q.push(t[u].fail);
}
}
}
这里 存的是每个点的权值,我们默认每个点值 ,让权值一点点往上传, 是我们最终要输出的那个数组。
然后我们把入度 的压进队列,这一部分无需多言。
接下来是比较关键的部分,我们整体还是拓扑的板子,然后里面有一句
auto v : g[u] 就是我们在遍历每个点对应的模式串编号,这个我们前面就提过,因为只有结束的点(就是我们第一张图的黄色点)存储了对应的编号,所以不用担心算重算多什么的。然后后遍历到的点会从它的前继继承权值,等到入度为 就压进队列。参考
- https://www.cnblogs.com/cjyyb/p/7196308.html
- https://blog.csdn.net/EQUINOX1/article/details/142420788
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...