专栏文章
线段树学习笔记(或者是个教学?)
算法·理论参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @minbucdq
- 此快照首次捕获于
- 2025/12/01 23:51 3 个月前
- 此快照最后确认于
- 2025/12/01 23:51 3 个月前
线段树
线段树基础
引入
新手期的我们看到这道题一定非常头疼,因为我们惊讶地发现,如果暴力枚举,两种操作的时间复杂度都是 ,进行 次操作的时间复杂度是 级的,在的数据下必定超时。
当我们稍微有了点信息知识点的积累,我们会试图用前缀和或者差分去做这道题。
前缀和可以 高效地维护区间查询,但是区间修改就被迫上升到 ,很明显无法通过。
差分则刚好相反,我们可以 高效维护区间修改操作,却无法高效完成区间查询操作,十分头疼。
于是,我们隆重介绍一个在未来会被反复改编、反复利用的数据结构:线段树。
当我们稍微有了点信息知识点的积累,我们会试图用前缀和或者差分去做这道题。
前缀和可以 高效地维护区间查询,但是区间修改就被迫上升到 ,很明显无法通过。
差分则刚好相反,我们可以 高效维护区间修改操作,却无法高效完成区间查询操作,十分头疼。
于是,我们隆重介绍一个在未来会被反复改编、反复利用的数据结构:线段树。
线段树基本结构
首先,线段树是一棵树,而且是一个二叉树。
树上每一个节点都维护着一个区间 的信息。
根节点一般是编号为1的节点,对于每一个节点,其左儿子的编号是它编号的2倍,其右儿子的编号是其左儿子编号 +1 ,一般如果节点编号为 ,在代码中将 定义为 , 的定义是 ,至于为何可以转化为这样的位运算,自己去思考。使用位运算可以优化常数话说真有人会可以去卡这玩意吗。
根节点维护的是区间 的信息,对于每一个节点维护的是 ,其左儿子维护的区间是 ,其右儿子维护的区间是 ,其中 ,以此递推,直到叶节点仅维护单点信息。
是不是有点乱了?我们缕一缕。
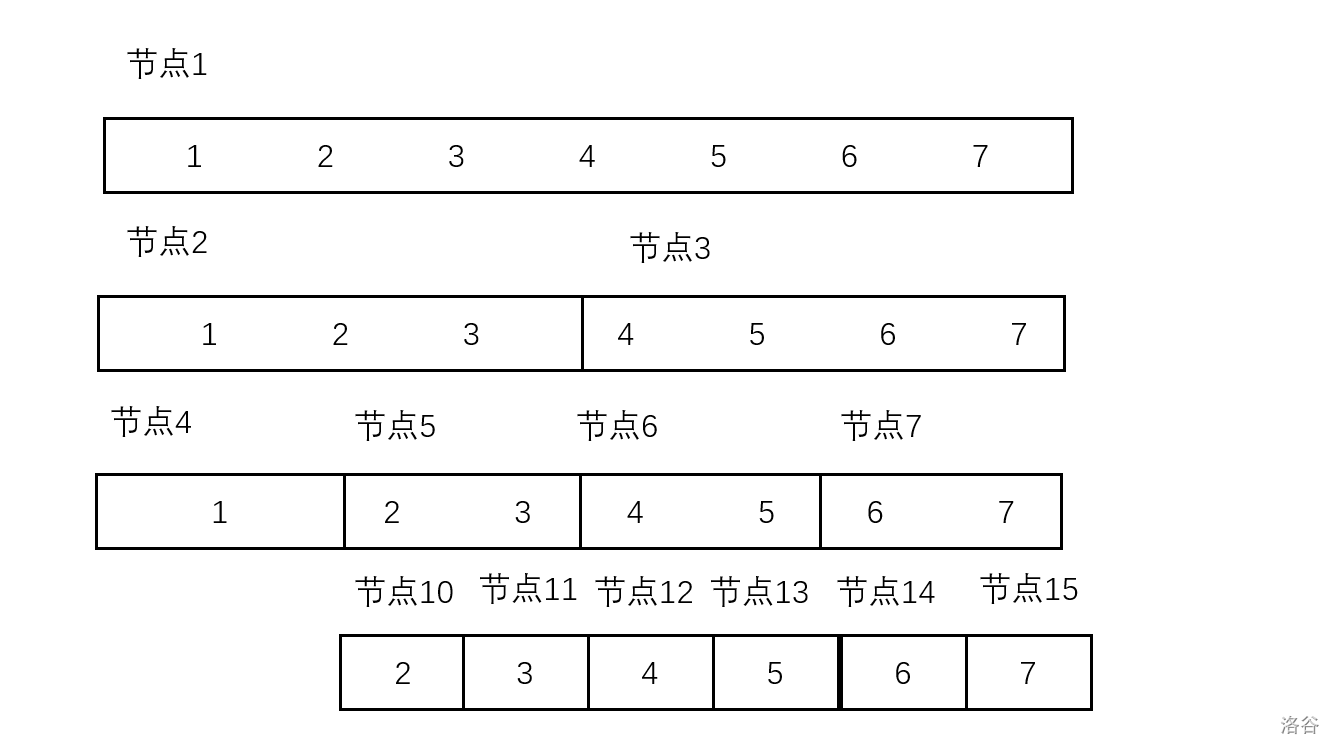
在上面的图片中,我们有一个长度为7的序列,我们对这个序列构建的线段树就是图上的这个结构。
树上每一个节点都维护着一个区间 的信息。
根节点一般是编号为1的节点,对于每一个节点,其左儿子的编号是它编号的2倍,其右儿子的编号是其左儿子编号 +1 ,一般如果节点编号为 ,在代码中将 定义为 , 的定义是 ,至于为何可以转化为这样的位运算,自己去思考。使用位运算可以优化常数
根节点维护的是区间 的信息,对于每一个节点维护的是 ,其左儿子维护的区间是 ,其右儿子维护的区间是 ,其中 ,以此递推,直到叶节点仅维护单点信息。
是不是有点乱了?我们缕一缕。
在上面的图片中,我们有一个长度为7的序列,我们对这个序列构建的线段树就是图上的这个结构。
建树
建树的过程很简单,递归建树即可。
先维护节点信息:
CPP先维护节点信息:
struct treenode{
int l,r,sum;
}tree[maxn<<2];
上面这个树节点中, 维护的是该区间的左边界和右边界, 表示的是该区间的区间和。
然后,我们要考虑的是和的维护问题,不然我们初始化都初始化不了。
要维护线段树节点的和,我们首先要考虑的是信息的上传更新。
CPP然后,我们要考虑的是和的维护问题,不然我们初始化都初始化不了。
要维护线段树节点的和,我们首先要考虑的是信息的上传更新。
void pushup(int u){
tree[u].sum=tree[lson].sum+tree[rson].sum;
}
这个 就是 ,也就是节点 的左儿子, 就是 ,也就是节点 的右儿子(之后出现我就不解释了)。
然后就是建树过程,如下:
CPP然后就是建树过程,如下:
void build(int u,int l,int r){
tree[u].l=l,tree[u].r=r;//初始化节点信息
if(l==r){
tree[u].sum=a[l];
return;
//若递归到叶节点则直接将区间和定义为该节点对应的单点值
}
build(lson,l,mid);
build(rson,mid+1,r);n
//分别递归左儿子和右儿子往下建树,mid是((l+r)>>1)
pushup(u);//将信息上传
}
之后代码会出现:
CPPbuild(1,1,n);
简单手玩说明一遍。
还是拿出那张图:
首先,我们从节点1开始建树,这时定义节点1的左边界和右边界为 。
分别递归左儿子和右儿子,左儿子到达节点2,右儿子到达节点3。
递归到节点2,此时定义节点2,定义其左边界为1,右边界为3。
继续向下递归,抵达节点4。定义节点4左边界为1,右边界为1。
这时我们发现左右边界相等,说明到达了叶节点。这个时候,我们定义该节点的区间和 为 。
回到节点2,我们继续向右递归到节点5完成一样的操作,得到节点5的区间和,这个时候节点2的区间和就由节点4和节点5上传得到,而节点1的区间和又可以在节点3的递归完成之后,由节点2和节点3上传得到。
然后我们就轻松完成了建树的过程。
还是拿出那张图:
首先,我们从节点1开始建树,这时定义节点1的左边界和右边界为 。
分别递归左儿子和右儿子,左儿子到达节点2,右儿子到达节点3。
递归到节点2,此时定义节点2,定义其左边界为1,右边界为3。
继续向下递归,抵达节点4。定义节点4左边界为1,右边界为1。
这时我们发现左右边界相等,说明到达了叶节点。这个时候,我们定义该节点的区间和 为 。
回到节点2,我们继续向右递归到节点5完成一样的操作,得到节点5的区间和,这个时候节点2的区间和就由节点4和节点5上传得到,而节点1的区间和又可以在节点3的递归完成之后,由节点2和节点3上传得到。
然后我们就轻松完成了建树的过程。
区间查询操作
听了一大堆关于线段树的乱七八糟的玩意,你可能还不清楚这个数据结构是如何维护区间和的,没关系,我马上讲解。

在这张图上,我想求出区间 中每一个数的和,我们怎么做呢?
很显然,我们可以通过节点5的和加上节点3的和得到。
这就是线段树解决区间问题的魅力之处了:它通过巧妙的拆分将一个区间分成几个区间来高效维护区间和。
然后接下来的问题是,如何让计算机知道将一个区间拆分成哪几个不同的区间呢?
先上代码:
CPP在这张图上,我想求出区间 中每一个数的和,我们怎么做呢?
很显然,我们可以通过节点5的和加上节点3的和得到。
这就是线段树解决区间问题的魅力之处了:它通过巧妙的拆分将一个区间分成几个区间来高效维护区间和。
然后接下来的问题是,如何让计算机知道将一个区间拆分成哪几个不同的区间呢?
先上代码:
int query(int u,int L,int R){//事实上,query返回的是该区间和目标区间的交集的和,但直接使用节点1与目标区间交集就是目标区间和
int l=tree[u].l,r=tree[u].r;
if(l>R||r<L>)return 0;//如果在该区间与目标区间没有交集就停止递归
if(L<=l&&r<=R){
return tree[u].sum;//如果该区间刚好被目标区间包含,则返回该区间的区间和
}
return query(lson,L,R)+query(rson,L,R);//继续向左右儿子递归查询
}
之后代码会出现:
CPPcout<<query(1,l,r)<<endl;
简单手玩说明一遍(依旧看那张图)。
加入我们想要求出区间 的区间和,我们先从根节点开始递归。
首先,节点1的区间 并没有被区间 包含,于是向左右儿子递归到达节点2和节点3。
很明显,节点2的区间 也没有被区间 包含,于是继续向下递归,递归到节点4和节点5。
节点4 与区间 没有交集,返回0。
节点5的区间 被区间 包含。则返回 。
回到节点2,这里的返回值是节点4和节点5的返回值之和,即0加上 ,也就是
这时我们再去看节点3那边。
我们发现节点3的区间 刚好被目标区间 包含,所以这里的返回值就是其区间和
回到节点1,这里的返回值是节点2和节点3的返回值之和, 。
然后我们就得到了区间 的区间和。
加入我们想要求出区间 的区间和,我们先从根节点开始递归。
首先,节点1的区间 并没有被区间 包含,于是向左右儿子递归到达节点2和节点3。
很明显,节点2的区间 也没有被区间 包含,于是继续向下递归,递归到节点4和节点5。
节点4 与区间 没有交集,返回0。
节点5的区间 被区间 包含。则返回 。
回到节点2,这里的返回值是节点4和节点5的返回值之和,即0加上 ,也就是
这时我们再去看节点3那边。
我们发现节点3的区间 刚好被目标区间 包含,所以这里的返回值就是其区间和
回到节点1,这里的返回值是节点2和节点3的返回值之和, 。
然后我们就得到了区间 的区间和。
懒标记的实现与区间修改操作
线段树的区间查询速度显然没有前缀和快,但前缀和无法做到区间修改,所以我们看一下区间修改是如何在线段树中操作的,比如说我现在想要在刚才的线段树中让 中的所有数都加1。
首先,通过类似区间查询的方式找到目标区间分裂出的几个区间,这里还是找到了节点3和节点5。
如果我们要让 中的所有数都+1,很明显节点3的区间和要+4,节点5的和要+2。 如果我们就这样草率地结束,那就酿成大错了,因为那两个节点的满堂子孙都得作类似的修改。
如果我们强行遍历所有的子子孙孙,那可就太麻烦了,而且时间复杂度明显超了。
这个问题,线段树的发明人想到了一个非常优雅且巧妙的方式解决了。
这个方法叫做懒标记。
对于每一次修改,我们不着急修改其区间和的值,对于每一个节点,我们多维护一个值,就是懒标记,每一次修改的时候直接加上懒标记,之后进行操作的时候再将懒标记下传。
所以我们需要先稍微修改一下树节点结构体的代码
CPP首先,通过类似区间查询的方式找到目标区间分裂出的几个区间,这里还是找到了节点3和节点5。
如果我们要让 中的所有数都+1,很明显节点3的区间和要+4,节点5的和要+2。 如果我们就这样草率地结束,那就酿成大错了,因为那两个节点的满堂子孙都得作类似的修改。
如果我们强行遍历所有的子子孙孙,那可就太麻烦了,而且时间复杂度明显超了。
这个问题,线段树的发明人想到了一个非常优雅且巧妙的方式解决了。
这个方法叫做懒标记。
对于每一次修改,我们不着急修改其区间和的值,对于每一个节点,我们多维护一个值,就是懒标记,每一次修改的时候直接加上懒标记,之后进行操作的时候再将懒标记下传。
所以我们需要先稍微修改一下树节点结构体的代码
struct treenode{
int l,r,sum,tag;//tag即懒标记
}tree[maxn<<2];
什么意思呢?我们再拿出来那张图:

在这张图中,我们使用 表示懒标记
我们修改节点3和节点5的懒标记,让它们加上1,并让sum加上对应的长度。
 这个时候你可能就要问了,这样子加不就是单纯的加了一通,没有下传吗?
这个时候你可能就要问了,这样子加不就是单纯的加了一通,没有下传吗?
这个方法的巧妙之处就在于,它不会要求递归操作,会在之后的区间查询和区间修改的时候如果用到了这个节点的信息,再将它更改并下传懒标记。
也就是说,如果这个时候我再求一次区间 的和,我们就将节点3和节点5的信息通过懒标记修改,并下传懒标记,就像这样: 懂了吧,下传操作不是在修改的时候直接完成,而是在之后用到这个节点的时候再去完成。
懂了吧,下传操作不是在修改的时候直接完成,而是在之后用到这个节点的时候再去完成。
我们先写一个更改并下传的函数操作:
CPP在这张图中,我们使用 表示懒标记
我们修改节点3和节点5的懒标记,让它们加上1,并让sum加上对应的长度。
这个时候你可能就要问了,这样子加不就是单纯的加了一通,没有下传吗?这个方法的巧妙之处就在于,它不会要求递归操作,会在之后的区间查询和区间修改的时候如果用到了这个节点的信息,再将它更改并下传懒标记。
也就是说,如果这个时候我再求一次区间 的和,我们就将节点3和节点5的信息通过懒标记修改,并下传懒标记,就像这样:
懂了吧,下传操作不是在修改的时候直接完成,而是在之后用到这个节点的时候再去完成。我们先写一个更改并下传的函数操作:
void pushdown(int u){
int l=tree[u].l,r=tree[u].r;
tree[lson].tag+=tree[u].tag;
tree[rson].tag+=tree[u].tag;
tree[lson].sum+=tree[u].tag*(mid-l+1);
tree[rson].sum+=tree[u].tag*(r-mid);
tree[u].tag=0;
}
然后就是区间修改操作的代码:
CPPvoid update(int u,int L,int R,int x){
int l=tree[u].l,r=tree[u].r;
if(l>R||r<L)return;
if(L<=l&&r<=R){
tree[u].sum+=x*(r-l+1);
tree[u].tag+=x;
return;
}
pushdown(u);//下传标记
update(lson,L,R,x);
update(rson,L,R,x);
pushup(u);
}
这一段和区间查询十分的类似,只是修改的时候要注意修改懒标记和值,而且 update 之前的 pushdown 也是为了更新节点儿子的信息。
所以同理,我们也需要对 query 操作做类似的操作以更新节点信息。
CPP所以同理,我们也需要对 query 操作做类似的操作以更新节点信息。
int query(int u,int L,int R){
int l=tree[u].l,r=tree[u].r;
if(l>R||r<L>)return 0;
pushdown(u);//下传标记
if(L<=l&&r<=R){
return tree[u].sum;
}
return query(lson,L,R)+query(rson,L,R);
}
通过这样的操作,我们就可以做到高效地维护区间修改。
顺便说一下,区间修改才需呀懒标记下传,如果是单点修改,那么懒标记就没有必要。
顺便说一下,区间修改才需呀懒标记下传,如果是单点修改,那么懒标记就没有必要。
总结
总而言之,线段树的操作就是自下往上传递区间和,自上往下传递标记,高效地维护区间操作。
其每次操作复杂度很容易证明是 的,因为通过观察不难发现线段树的层数刚好就是 ,而且每一次操作最多上传或者下传的次数就是层数,所以总体而言其复杂度是 。
其每次操作复杂度很容易证明是 的,因为通过观察不难发现线段树的层数刚好就是 ,而且每一次操作最多上传或者下传的次数就是层数,所以总体而言其复杂度是 。
代码(华丽封装)
CPP#include<bits/stdc++.h>
#define lson (u<<1)
#define rson (u<<1|1)
#define mid ((l+r)>>1)
#define int long long
using namespace std;
const int maxn=1e5+5;
int n,q;
int a[maxn];
struct segtree{
struct treenode{
int l,r,sum,tag;
}tree[maxn<<2];
void pushup(int u){
tree[u].sum=tree[lson].sum+tree[rson].sum;
}
void build(int u,int l,int r){
tree[u].l=l,tree[u].r=r;
if(l==r){
tree[u].sum=a[l];
return;
}
build(lson,l,mid),build(rson,mid+1,r);
pushup(u);
}
void pushdown(int u){
int l=tree[u].l,r=tree[u].r,tag=tree[u].tag;
tree[lson].tag+=tag;
tree[rson].tag+=tag;
tree[lson].sum+=tag*(mid-l+1);
tree[rson].sum+=tag*(r-mid);
tree[u].tag=0;
}
void update(int u,int L,int R,int x){
int l=tree[u].l,r=tree[u].r;
if(l>R||r<L)return;
if(L<=l&&r<=R){
tree[u].sum+=x*(r-l+1);
tree[u].tag+=x;
return;
}
pushdown(u);
update(lson,L,R,x);
update(rson,L,R,x);
pushup(u);
}
int query(int u,int L,int R){
int l=tree[u].l,r=tree[u].r;
if(l>R||r<L)return 0;
pushdown(u);
if(L<=l&&r<=R){
return tree[u].sum;
}
return query(lson,L,R)+query(rson,L,R);
}
}seg;
signed main(){
cin>>n>>q;
for(int i=1;i<=n;i++){
cin>>a[i];
}
seg.build(1,1,n);
while(q--){
int op;
cin>>op;
if(op==1){
int l,r,x;
cin>>l>>r>>x;
seg.update(1,l,r,x);
}else{
int l,r;
cin>>l>>r;
cout<<seg.query(1,l,r)<<endl;
}
}
return 0;
}
线段树进阶
到了这里,你应该已经明白了线段树的基本结构和运行方式了,但如果你认为线段树只能用来做区间和,那就大错特错了,线段树实际上可以解决一切满足结合律的区间问题,比如最值、乘积、最大公因数等等。那么,假如说我我们看到一道题,我们该如何判断它是否能用线段树完成呢?
我们先思考一下对于线段树的进阶理解方式。
线段树本质来说就是两种东西的结合:信息与标记。
一道题能否用线段树完成,取决于它是否能够在 的时间复杂度下完成以下3种操作:
我们先思考一下对于线段树的进阶理解方式。
线段树本质来说就是两种东西的结合:信息与标记。
一道题能否用线段树完成,取决于它是否能够在 的时间复杂度下完成以下3种操作:
- 信息与信息的结合,即 操作
- 信息与标记的结合,即修改操作
- 标记与标记的结合,即 操作
只要能够高效地完成这3种操作,这道题就可以用线段树完成。
比如说,刚刚的那道模板题,信息是区间和,标记是区间加,区间和与区间和的合并加起来就是了,区间加与区间加的合并也是加起来就是了,区间和与区间加照样加起来,所以这就是非常简单的线段树模板题目,而且三种操作都在 内完成了。
我们再举几个例子,看看能不能用线段树完成。
比如说,刚刚的那道模板题,信息是区间和,标记是区间加,区间和与区间和的合并加起来就是了,区间加与区间加的合并也是加起来就是了,区间和与区间加照样加起来,所以这就是非常简单的线段树模板题目,而且三种操作都在 内完成了。
我们再举几个例子,看看能不能用线段树完成。
对于这道题,我们考虑能够否使用线段树完成。
首先,如果使用线段树,那么我们维护的信息就是区间的 和,维护的标记就是加的标记。
信息的合并显然就是两个区间 和相加,标记的合并也很显然就是两个区间的加标记相加。
问题就出在信息与标记的合并上。
加和怎么跟 和合并呢?
我们有 的和角公式:
首先,如果使用线段树,那么我们维护的信息就是区间的 和,维护的标记就是加的标记。
信息的合并显然就是两个区间 和相加,标记的合并也很显然就是两个区间的加标记相加。
问题就出在信息与标记的合并上。
加和怎么跟 和合并呢?
我们有 的和角公式:
将这个公式扩展到区间上,可以得到:
于是我们发现,要维护区间 和的修改,我们还需要维护多一个信息,那就是 值的和。
很显然, 信息间的合并也是直接加起来,那么问题就来了, 的区间信息和加和标记又怎么结合呢?
我们有的和角公式:
很显然, 信息间的合并也是直接加起来,那么问题就来了, 的区间信息和加和标记又怎么结合呢?
我们有的和角公式:
同样把公式扩展到区间上:
我们发现,只要维护了区间 的和,我们就可以高效维护这两个的加操作,直接套模板即可。
- 将 修改成
- 将 接改成
- 给定区间 ,求出
好消息是,这题是单点修改,不需要使用标记,只需要维护信息和信息的合并就行了。
坏消息是,就算只有信息我们也不知道怎么合并。
这真的很复杂,我们可能需要好好模拟一下。
首先,假设线段树上有这么一个节点,叫做 ,它的两个儿子叫做 和
我们定义 表示在 维护的区间 内的
我们思考 如何从两个儿子 和 上传
首先,如果 都在儿子 或者儿子 中 ,我们可以发现, 可以从 和 中得到。
然后我们考虑 在左儿子, 在右儿子上的情况。
这个时候,假如 在左儿子上, 的最佳情况显然是选择 最大的那个,如果 在右儿子上, 的最佳情况显然是选择 最大的那个,所以对于每一个区间,我们还要维护 的最大值,令 。
所以接下来问题变成了维护以下两个值:
定义
然后我们再考虑 和 怎么从 和 节点上传。
可以分为以下两种情况:
首先考虑 同时在 上或者同时在 上,这个时候直接由 和 上传得到。
然后考虑 在 上, 在 上时,这种情况 的最优解显然是 中 的最大值,也就是 ,而 的最优解则是 中 的最小值,我们新维护一个值 。 值就可以从 和 中得到。
接下来思考 的维护。
同理,可以从 和 中得到,再思考两个区间各占一个的情况,也能够推出可以从 和 中得到。
然后你就会发现一切都闭环了,我们对于每一个节点维护以下几个值:
坏消息是,就算只有信息我们也不知道怎么合并。
这真的很复杂,我们可能需要好好模拟一下。
首先,假设线段树上有这么一个节点,叫做 ,它的两个儿子叫做 和
我们定义 表示在 维护的区间 内的
我们思考 如何从两个儿子 和 上传
首先,如果 都在儿子 或者儿子 中 ,我们可以发现, 可以从 和 中得到。
然后我们考虑 在左儿子, 在右儿子上的情况。
这个时候,假如 在左儿子上, 的最佳情况显然是选择 最大的那个,如果 在右儿子上, 的最佳情况显然是选择 最大的那个,所以对于每一个区间,我们还要维护 的最大值,令 。
所以接下来问题变成了维护以下两个值:
定义
然后我们再考虑 和 怎么从 和 节点上传。
可以分为以下两种情况:
首先考虑 同时在 上或者同时在 上,这个时候直接由 和 上传得到。
然后考虑 在 上, 在 上时,这种情况 的最优解显然是 中 的最大值,也就是 ,而 的最优解则是 中 的最小值,我们新维护一个值 。 值就可以从 和 中得到。
接下来思考 的维护。
同理,可以从 和 中得到,再思考两个区间各占一个的情况,也能够推出可以从 和 中得到。
然后你就会发现一切都闭环了,我们对于每一个节点维护以下几个值:
上面这坨东西就是我们 的过程,那是相当的繁琐复杂,这道题的区间信息维护也就是这样,把它们代入原来的板子即可。由于是单点修改,不需要考虑标记。
觉得复杂了?觉得难以承受了?没关系,接下来的题目会让你觉得这个其实还挺温柔的
觉得复杂了?觉得难以承受了?没关系,接下来的题目会让你觉得这个其实还挺温柔的
- 将 修改为
- 询问区间 的最大子段和
看见这道题,我们第一反应就是毫无反应,因为我们十分清楚最大子段和的维护是 的,而且 的范围甚至无法让我们使用 的时间复杂度,所以每一次上传下传只能用 复杂度。
这似乎很困难,实际上,是非常困难,因为最大子段和的合并显然不能用单纯的方法。
我们必须想出一种办法让一个区间 通过维护几个值让它可以从 和 两个区间的那几个值得到。
考虑到合并的问题,认为我们有必要处理边界的最大子段和,所以对于每一个节点,我们维护以下几个值:
:区间和
:最大子段和
:以区间左边界为边界的最大子段和
:以区间右边界为边界的最大子段和
什么意思呢?我来解释一下:
和 很好理解, 指的是在这个区间内包含区间左边界的子段中和最大的那个子段的和, 则指这个区间内包含区间右边界的子段中和最大的子段的和。
我们如何通过这四个值来进行合并区间呢?
首先, 的上传很简单,相加即可。
至于其它几个值的转化,可能比较复杂,为了方便,我们依旧认为有这么一个节点 ,它左儿子叫 ,右儿子叫 。
然后思考 如何转化。
这有两种情况,这个区间贴左边界的最大子段和,可能是左儿子的贴左边界的最大子段和,也可能是左儿子的区间和加上右儿子的贴左边界的最大子段和。
看图:
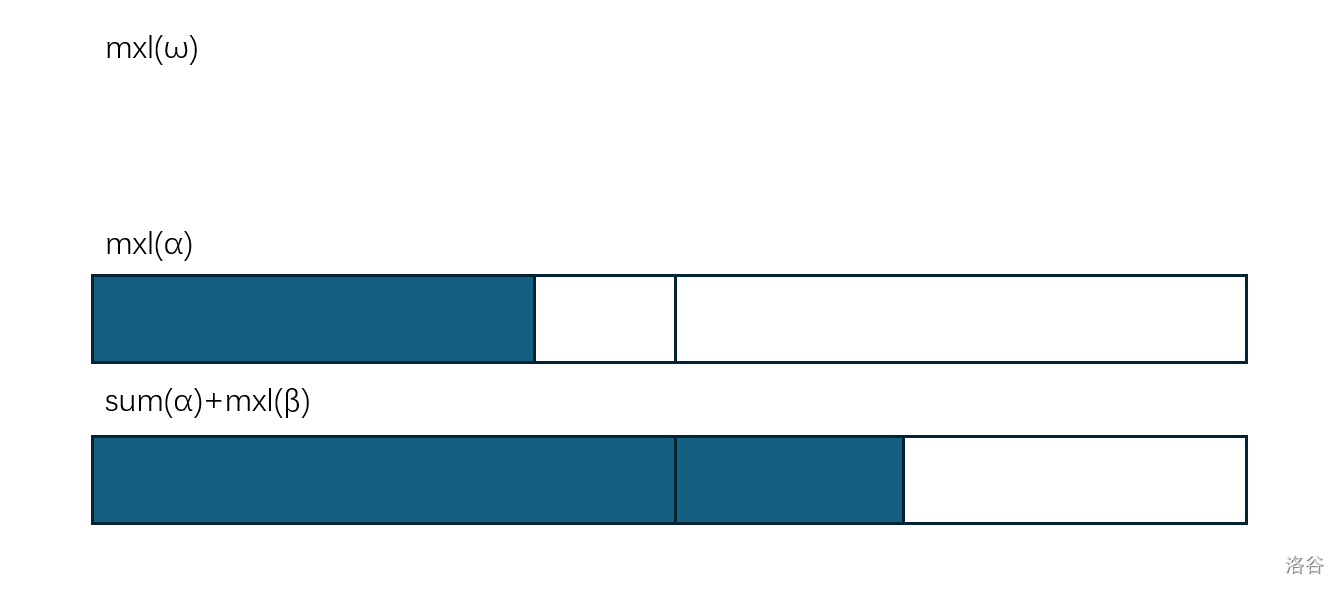
同理, 的转化也类似:
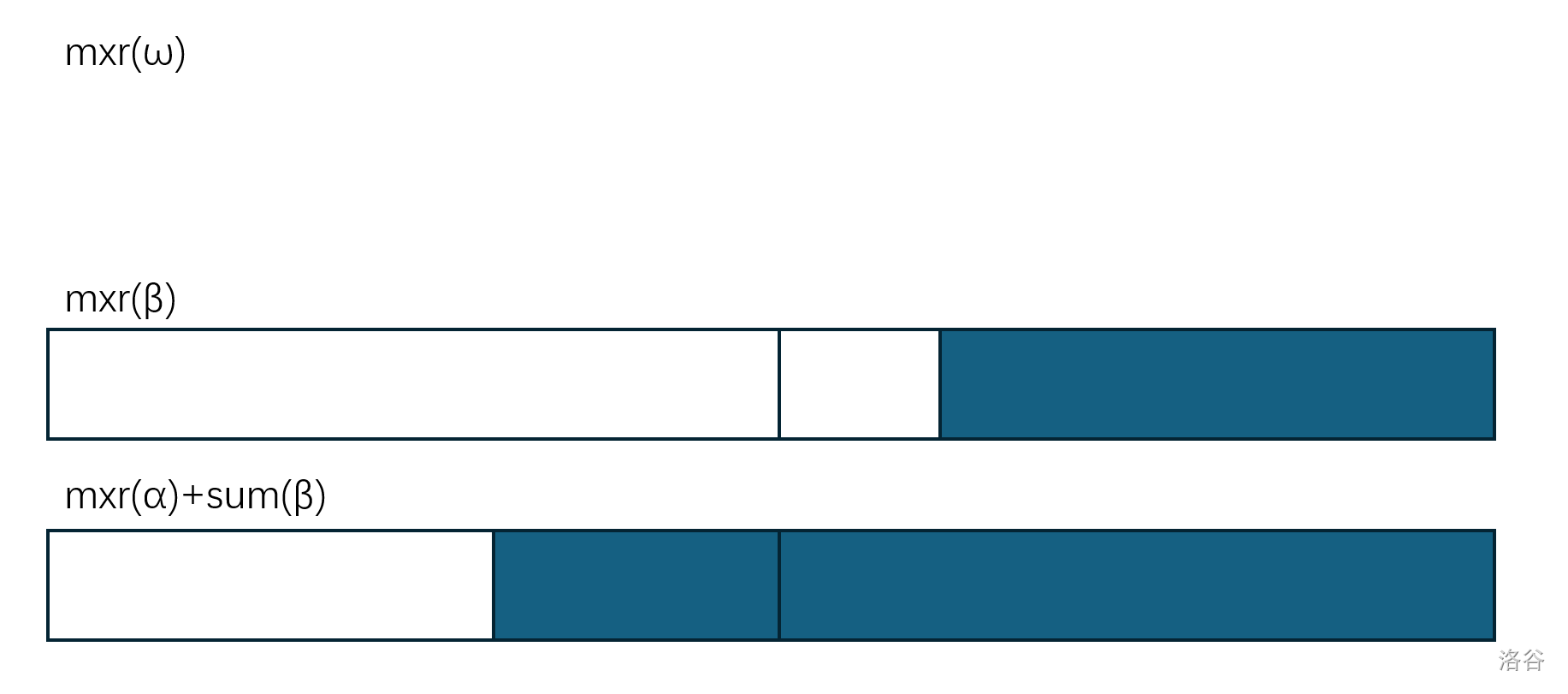
最后考虑 的转移。
的最大子段和有以下几种情况:
这似乎很困难,实际上,是非常困难,因为最大子段和的合并显然不能用单纯的方法。
我们必须想出一种办法让一个区间 通过维护几个值让它可以从 和 两个区间的那几个值得到。
考虑到合并的问题,认为我们有必要处理边界的最大子段和,所以对于每一个节点,我们维护以下几个值:
:区间和
:最大子段和
:以区间左边界为边界的最大子段和
:以区间右边界为边界的最大子段和
什么意思呢?我来解释一下:
和 很好理解, 指的是在这个区间内包含区间左边界的子段中和最大的那个子段的和, 则指这个区间内包含区间右边界的子段中和最大的子段的和。
我们如何通过这四个值来进行合并区间呢?
首先, 的上传很简单,相加即可。
至于其它几个值的转化,可能比较复杂,为了方便,我们依旧认为有这么一个节点 ,它左儿子叫 ,右儿子叫 。
然后思考 如何转化。
这有两种情况,这个区间贴左边界的最大子段和,可能是左儿子的贴左边界的最大子段和,也可能是左儿子的区间和加上右儿子的贴左边界的最大子段和。
看图:
同理, 的转化也类似:
最后考虑 的转移。
的最大子段和有以下几种情况:
- 或者 的最大子段和
- 的贴左最大子段和或者 的贴右最大子段和
- 的贴右最大子段和加上 的贴左最大子段和
如果难以理解,请看图:
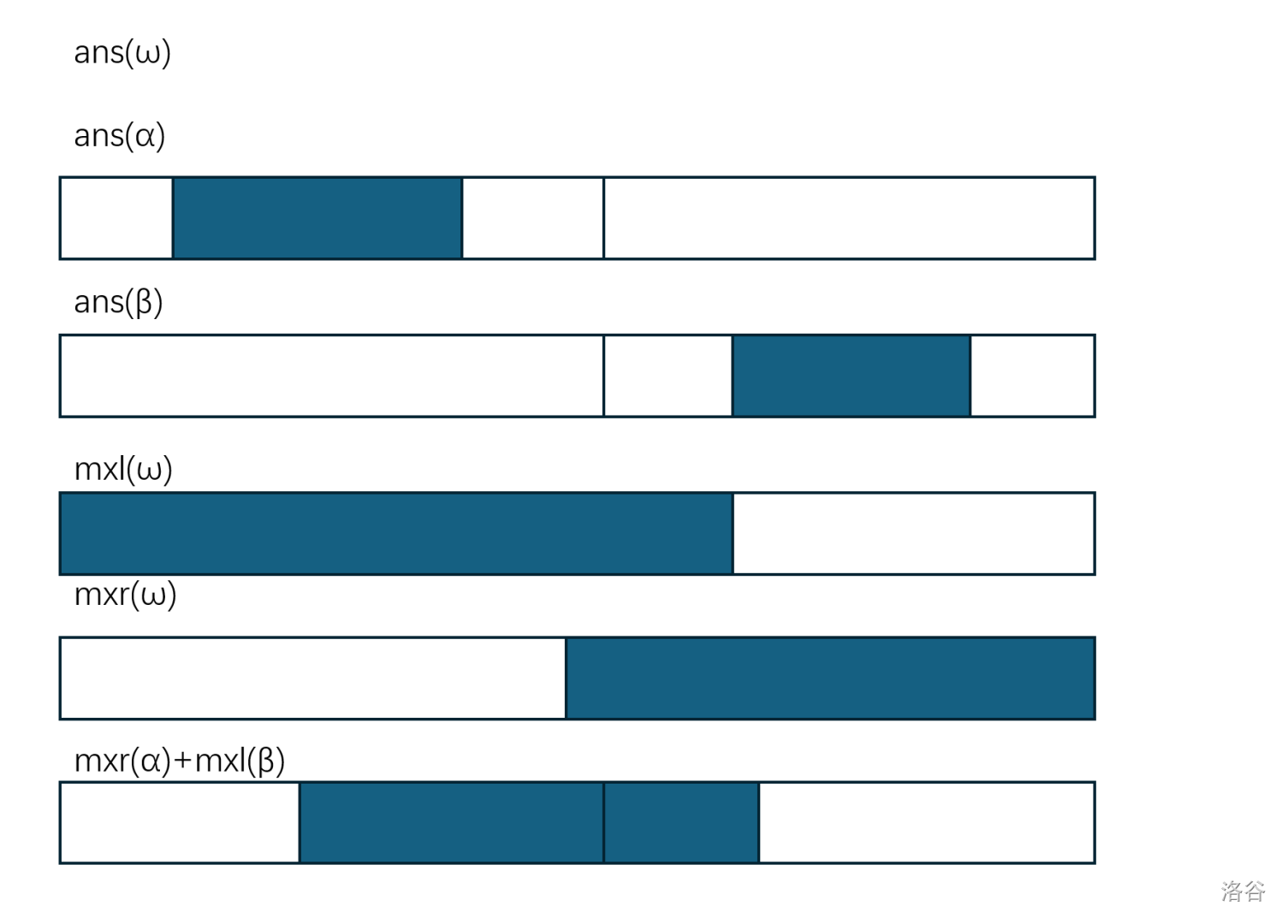
到了这里,我们就轻松完成了信息的上传合并的操作。
这个时候你可能要问了,我们询问的时候怎么确定答案呢?
其实很简单,线段树本质就是在线段树上找到层数最低的几个节点它们所对应的区间合并刚好可以得到你的目标区间,所以说你只要把这几个区间用上面的方法合并就可以了。
强烈建议各位在写这道题的时候为线段树的节点结构体写一个+的重载运算符,因为在之后的 函数中会更加方便。
到了这里,我们就轻松完成了信息的上传合并的操作。
这个时候你可能要问了,我们询问的时候怎么确定答案呢?
其实很简单,线段树本质就是在线段树上找到层数最低的几个节点它们所对应的区间合并刚好可以得到你的目标区间,所以说你只要把这几个区间用上面的方法合并就可以了。
强烈建议各位在写这道题的时候为线段树的节点结构体写一个+的重载运算符,因为在之后的 函数中会更加方便。
- 将 修改成
- 给定 ,询问区间 排序后能否构成一个公差为 的等差数列。
其中 都需要异或之前输出Yes的数量
经过了前两题的教训,我们现在不会再因为这道题是单点修改而感到开心了,因为我们知道,就算不需要标记只有信息的合并也可以把我们耍得团团转。
这道题真的很值得我们思考,等差数列可以推导出的性质非常多,我们需要抽取其中几个性质,使得这几个性质不但是这个序列是等差数列的充要条件,而且这几个条件可以通过线段树维护。
线段树可以维护什么具体值呢?比如最大值、最小值、 等等。
综合所有结果,如果 区间排序之后是公差为 等差数列,我们推断出可以有以下两个条件可以被维护:
这道题真的很值得我们思考,等差数列可以推导出的性质非常多,我们需要抽取其中几个性质,使得这几个性质不但是这个序列是等差数列的充要条件,而且这几个条件可以通过线段树维护。
线段树可以维护什么具体值呢?比如最大值、最小值、 等等。
综合所有结果,如果 区间排序之后是公差为 等差数列,我们推断出可以有以下两个条件可以被维护:
- 最大值与最小值之差刚好等于
- 差分数组的所有数的 刚好等于
这两个条件可以使用线段树维护,也是 区间排序之后是公差为 等差数列的必要条件。
但问题在于,不是充分条件。
要使它成为充分条件,我们恐怕还要加上一个条件:
但问题在于,不是充分条件。
要使它成为充分条件,我们恐怕还要加上一个条件:
- 区间内各数互不相同
加上这个条件之后,这三个条件就是充要条件了。
所以我们思考条件3如何使用线段树维护。
但这似乎没有容易多少,互不相同这一条件的合并似乎几乎不可能。
但是,我们有一个非常巧妙的办法来完成这个条件的维护。
对于每一个数,维护其前驱位置。
这里的前驱指的是在这个数之前最近的与它相同的数。
对于一个线段树节点的区间,维护其内部所有数的最大前驱位置。
如果一个区间内所有数的前驱都在这个区间的左边界以左,那么这个区间的数就是互不相同的。
好的,现在我们知道了这个互不相同如何转化了,那么我们该如何维护前驱呢?如果一个数发生了改变,我们该如何改变其前驱和其它会被改变的前驱呢?
所以,为了维护前驱,对于每一个数,维护其后继位置。
这里的后继指的是在这个数之后最近的与它相同的数。
如果一个数被改了,那么它后继的前驱就会变成它原本的前驱,它前驱的后继就会变成其原本的后继。
但是,它被改到的那个数中也会有前驱后继需要更改。
所以从一开始,我们就需要维护所有数出现的位置,直接用一个 套 存上,顺便省了离散化。
当一个数从 改成了 ,通过二分找到其在 上第一个在它位置之前的位置,也就是它的新前驱,把它的前驱改成那个前驱对应的位置,再把新前驱的后继改成它的位置,新后继的修改也是同理。(这个修改方式挺像链表的)
重要的是,更改之后,后继与新后继都需要在线段树中递归一遍,更新线段树节点中最大前驱的信息,否则更新不及时就会爆零,甚至像我一样出现 数据全过但原数据全WA的情形调了我两天
这道题最难的一点是要维护两个线段树(一个原数组,一个差分数组 ),容易搞混,再加上差分要修改两个点,而且下标会出现一些变化,再者就是这道题还有很多专门坑人的玩意,比如说 可以为0需要特殊考虑,而且 的时候也算等差数列,也需要特判,各种乱七八糟的条件和干扰项是真的难写又难调。
所以上代码吧,不然真的很难理解:
CPP所以我们思考条件3如何使用线段树维护。
但这似乎没有容易多少,互不相同这一条件的合并似乎几乎不可能。
但是,我们有一个非常巧妙的办法来完成这个条件的维护。
对于每一个数,维护其前驱位置。
这里的前驱指的是在这个数之前最近的与它相同的数。
对于一个线段树节点的区间,维护其内部所有数的最大前驱位置。
如果一个区间内所有数的前驱都在这个区间的左边界以左,那么这个区间的数就是互不相同的。
好的,现在我们知道了这个互不相同如何转化了,那么我们该如何维护前驱呢?如果一个数发生了改变,我们该如何改变其前驱和其它会被改变的前驱呢?
所以,为了维护前驱,对于每一个数,维护其后继位置。
这里的后继指的是在这个数之后最近的与它相同的数。
如果一个数被改了,那么它后继的前驱就会变成它原本的前驱,它前驱的后继就会变成其原本的后继。
但是,它被改到的那个数中也会有前驱后继需要更改。
所以从一开始,我们就需要维护所有数出现的位置,直接用一个 套 存上,顺便省了离散化。
当一个数从 改成了 ,通过二分找到其在 上第一个在它位置之前的位置,也就是它的新前驱,把它的前驱改成那个前驱对应的位置,再把新前驱的后继改成它的位置,新后继的修改也是同理。(这个修改方式挺像链表的)
重要的是,更改之后,后继与新后继都需要在线段树中递归一遍,更新线段树节点中最大前驱的信息,否则更新不及时就会爆零,甚至像我一样出现 数据全过但原数据全WA的情形
这道题最难的一点是要维护两个线段树(一个原数组,一个差分数组 ),容易搞混,再加上差分要修改两个点,而且下标会出现一些变化,再者就是这道题还有很多专门坑人的玩意,比如说 可以为0需要特殊考虑,而且 的时候也算等差数列,也需要特判,各种乱七八糟的条件和干扰项是真的难写又难调。
所以上代码吧,不然真的很难理解:
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int maxn=3e5+5;
const int inf=1e18+7;
#define lson (u<<1)
#define rson (u<<1|1)
#define mid ((l+r)>>1)
int a[maxn],d[maxn];//d是a的差分数组
int n,m,cnt;
map<int,set<int>> mp;//储存数出现的位置
int anc[maxn],suc[maxn];//前驱后继储存
void remove(int x){//把一个数x从mp[a[x]]中删去,同时更新前驱后继
auto &s=mp[a[x]];
auto it=s.find(x);
if(it==s.end())return;//没找到
if(it!=s.begin()){//确认有后继
auto pre=prev(it);
suc[*pre]=suc[x];
}
if(next(it)!=s.end()){//确认有前驱
auto nex=next(it);
anc[*nex]=anc[x];
}
s.erase(it);
if(s.empty())mp.erase(a[x]);
}
void insert(int x,int y){//把一个数x插入mp[y],同时更新前驱后继
a[x]=y;//更新a数组因为差分线段树会用到
auto &s=mp[y];
auto it=s.lower_bound(x);
if(it!=s.end()){//有后继
suc[x]=*it;
anc[*it]=x;
}else{//没有后继
suc[x]=n+1;
}
if(it!=s.begin()){//有前驱
auto pre=prev(it);
anc[x]=*pre;
suc[*pre]=x;
}else{//没有前驱
anc[x]=0;
}
s.insert(x);
}
void change(int x,int y){
if(a[x]==y)return;//这个等于没改
remove(x);
insert(x,y);
}
struct seg_tree{
struct treenode{
int l,r,mx,mn,mxanc;
/*
l,r:左右端点
mx,mn:区间最大值与最小值
mxanc:最小前驱
*/
}tree[maxn<<2];
void pushup(int u){
tree[u].mx=max(tree[lson].mx,tree[rson].mx);
tree[u].mn=min(tree[lson].mn,tree[rson].mn);
tree[u].mxanc=max(tree[lson].mxanc,tree[rson].mxanc);
}
void build(int u,int l,int r){
tree[u].l=l,tree[u].r=r;
if(l==r){
tree[u].mx=tree[u].mn=a[l];
tree[u].mxanc=anc[l];
return;
}
build(lson,l,mid);
build(rson,mid+1,r);
pushup(u);
}
void update(int u,int p,int x){
int l=tree[u].l,r=tree[u].r;
if(l>p||r<p)return;
if(l==r){
change(p,x);
tree[u].mxanc=anc[p];
tree[u].mx=tree[u].mn=x;
return;
}
if(p<=mid)update(lson,p,x);
else update(rson,p,x);
pushup(u);
}
int querymn(int u,int L,int R){
int l=tree[u].l,r=tree[u].r;
if(l>R||r<L)return inf;
if(L<=l&&r<=R)return tree[u].mn;
return min(querymn(lson,L,R),querymn(rson,L,R));
}
int querymx(int u,int L,int R){
int l=tree[u].l,r=tree[u].r;
if(l>R||r<L)return -inf;
if(L<=l&&r<=R)return tree[u].mx;
return max(querymx(lson,L,R),querymx(rson,L,R));
}
int queryanc(int u,int L,int R){
int l=tree[u].l,r=tree[u].r;
if(l>R||r<L)return -1;
if(L<=l&&r<=R)return tree[u].mxanc;
return max(queryanc(lson,L,R),queryanc(rson,L,R));
}//板子,不必多说
}tree_a; //维护原数组的区间最值与最大前驱
struct segtree{
struct treenode{
int l,r;
int gcd;
}tree[maxn<<2];
void pushup(int u){
tree[u].gcd=__gcd(tree[lson].gcd,tree[rson].gcd);
}
void build(int u,int l,int r){
tree[u].l=l,tree[u].r=r;
if(l==r){
tree[u].gcd=d[l];
return;
}
build(lson,l,mid);
build(rson,mid+1,r);
pushup(u);
}
void update(int u,int p,int x){
int l=tree[u].l,r=tree[u].r;
if(l>p||r<p)return;
if(l==r){
tree[u].gcd+=x;
return;
}
update(lson,p,x);
update(rson,p,x);
pushup(u);
}
int querygcd(int u,int L,int R){
int l=tree[u].l,r=tree[u].r;
if(l>R||r<L)return 0;
if(L<=l&&r<=R)return abs(tree[u].gcd);
return __gcd(querygcd(lson,L,R),querygcd(rson,L,R));
}
}tree_d; //维护差分数组的gcd
signed main(){
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>a[i];
d[i]=a[i]-a[i-1];
insert(i,a[i]);
}
tree_a.build(1,1,n);
tree_d.build(1,1,n);
while(m--){
int op;
cin>>op;
if(op==1){
int x,y;
cin>>x>>y;
x^=cnt,y^=cnt;//强制在线
int val=a[x],oldsuc=suc[x];
tree_a.update(1,x,y);
int newsuc=suc[x];
tree_a.update(1,oldsuc,a[oldsuc]);//更新后继在线段树中最大前驱的信息
tree_a.update(1,newsuc,a[newsuc]);//更新新后继在线段树中新最大前驱的信息
//此处因为原后继和新后继的前驱都发生了改变,但是线段树内部的最大前驱却没有改完全
//所以需要把它们放进线段树中重新递归把信息上传一次
tree_d.update(1,x,y-val);//更改差分数组信息
if(x!=n)tree_d.update(1,x+1,val-y);//注意要改两个点
}else{
int l,r,k;
cin>>l>>r>>k;
l^=cnt,r^=cnt,k^=cnt;
if(l==r){//特判:l,r相等时仅有一个数,是等差数列
cout<<"Yes"<<endl;
cnt++;
continue;
}
int mn=tree_a.querymn(1,l,r);//区间最小值
int mx=tree_a.querymx(1,l,r);//区间最大值
int mxanc=tree_a.queryanc(1,l,r);//区间最大前驱
int gcd=tree_d.querygcd(1,l+1,r);//区间差值gcd
if(k==0){
if(mx==mn&&mxanc>=l){//特判:当公差为0时,所有元素相同才是等差数列
cout<<"Yes"<<endl;
cnt++;
}
else cout<<"No"<<endl;
continue;
}
if((mx-mn==(r-l)*k)&&mxanc<l&&gcd==k){//3个条件:最大最小差值为(r-l)*k,最大前驱小于l区间元素互不相同,差值gcd等于公差
cout<<"Yes"<<endl;
cnt++;
}else{
cout<<"No"<<endl;
}
}
}
return 0;
}
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...