专栏文章
Day01
算法·理论参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @miqf61wd
- 此快照首次捕获于
- 2025/12/04 03:48 3 个月前
- 此快照最后确认于
- 2025/12/04 03:48 3 个月前
基础算法:
枚举与搜索:
DFS与BFS:
相信大家已经学过这两种搜索算法了,我们简单回顾一下。
-
DFS:用递归实现,“一条路走到黑”,好写。
-
BFS:用队列+循环实现,“大水漫灌”,适合一部分“最小化”问题,例如大家都熟悉的最短路问题。
搜索过程其实就是状态转移。
可行性剪枝:
观察:朴素搜索太蠢了!一些明显会使得接下来不合法的策略可以舍弃。也就是在搜索树上“回头”,避开了一些无用的分支,“剪枝”因此得名。
简单来说,如果你一眼望过去全都不合法,那就不要继续走下去了。
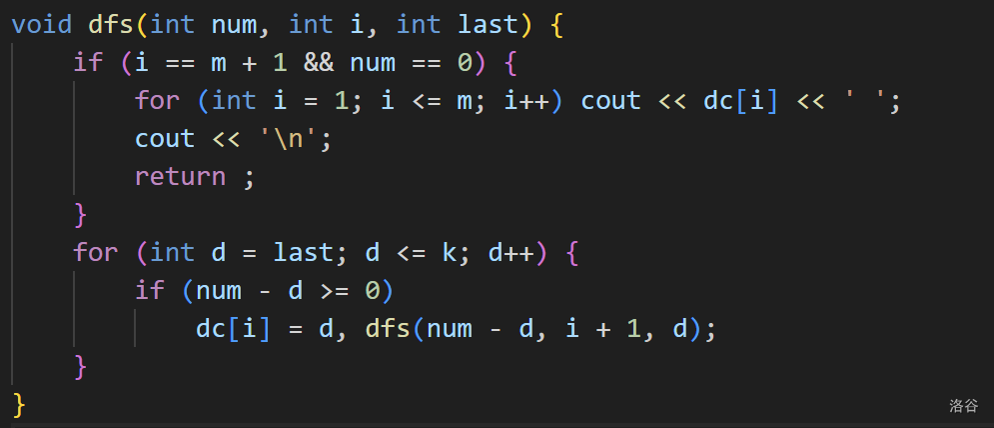
例子:把一个正整数 拆分为 个 的正整数相加,求所有方案。例如 就是把 拆分为 个数相加。(要求数字从小到大排序)
solution:
朴素的搜索:
考虑去掉“一眼望过去”
显然不合法的状态。

枚举与搜索
-
枚举:框定一个范围,遍历其中的所有东西。比如枚举左右端点成为一个区间。
-
搜索:从一个初始状态出发,一步一步走到相邻的状态,遍历能走到的所有东西。比如走迷宫。
可以发现,无论是搜索还是枚举,实际上都是在用各种各样的策略去找东西。
例题:
- 的序列, 代表颜色, , 求所有区间颜色的数量并求和
枚举优化:
- 改变枚举对象:比如说从枚举左右端点改成枚举最值,从枚举因数改成枚举倍数。
- 改变枚举顺序:比如说倒着枚举。
- 减少枚举量:比如说通过观察发现有东西是不需要枚举的。
启发式搜索与A*:
观察2:一些状态比另一些状态“更容易”到达最优解。如果我们能给每一个状态评一个价值,就能够优先走那些“更好”的状态。
具体来说,使用一个数 去代表当前这个状态到达最终状态的理论最优秀代价。那么它目前的代价 加上这个理论最优代价 就得到了这个点的估计价值 。 有了这个 我们能干点啥?
具体来说,使用一个数 去代表当前这个状态到达最终状态的理论最优秀代价。那么它目前的代价 加上这个理论最优代价 就得到了这个点的估计价值 。 有了这个 我们能干点啥?
- 如果 当前 ,那么你还愣着干什么,赶快回头!(最优性剪枝)
- 如果我能走到好多个状态,那肯定是优先走 更大的那个啊!(A*)
solution:
首先设计一个最朴素的搜索:先枚举从下往上数第一层的半径,然后一层一层向上搜索。
接下来开始剪枝:
可行性剪枝:从上往下第 层的高和半径至少为 。体积的最小值和最大值都可以计算。 最优性剪枝:将 设置为尽可能小地放蛋糕,不考虑体积为 这一限制的情况下,得到的代价。
加入这两个剪枝之后足以通过本题。
接下来开始剪枝:
可行性剪枝:从上往下第 层的高和半径至少为 。体积的最小值和最大值都可以计算。 最优性剪枝:将 设置为尽可能小地放蛋糕,不考虑体积为 这一限制的情况下,得到的代价。
加入这两个剪枝之后足以通过本题。
记忆化搜索:
如果你走迷宫,走进一个屋子,经历了一番波折(dfs)后终于返回这个屋子,在墙上写下“从这里走到终点至少需要100步”,那么等你下次走到相同的屋子时,你大可不必再走一遍,而是直接掉头走人。
这便是“记忆化搜索”在干的事情,我们开一个数组 ,记录 这个状态出发到达最终状态的代价。那么我们走到每个点的次数就会大大减少了。
但是另一方面,如果你拿着一把钥匙重新走进了这个房间,你可能就不能根据房间上的字去做判断了——手中的钥匙改变了之后有可能作出的判断,也就是动态规划里提到的“后效性”。
solution:
记忆化搜索模板题,我们以每一个位置为起点开始搜索。
记 表示以 为起点,最长的滑雪路径。
双向BFS*:
观察3:对一张图的广搜而言,单向搜索不如“双向奔赴”。因此我们不妨从起点和终点同时或者分别开始广搜,接着检查是否到达了相同的点。
稍微分析一下这样做的复杂度:假设搜索树分叉为 ,从起点到终点要 步,那么双向广搜实际上将一个 的朴素广搜变成了一个 的搜索,复杂度直接开方!
与这个搜索类似的算法叫做meet in middle,大家有兴趣可以了解一下。
因为这个东西例题大多比较困难,大家现阶段明白这是怎么一回事即可。
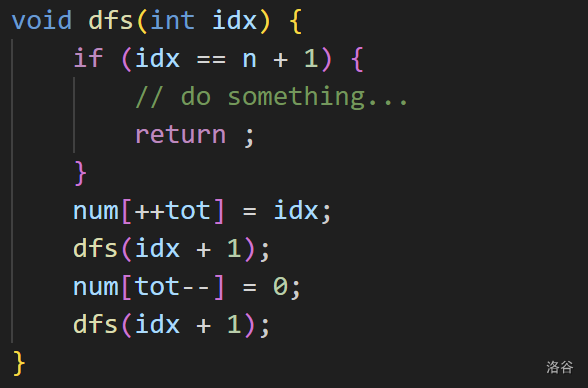
枚举子集:
有些时候我们写搜索其实就是为了枚举所有可能的情况,此时如果一个for循环就能解决我们的问题,那么会极大地提高代码书写与运行的效率。
枚举子集就是这样的一个情况。
考虑一个集合 ,我们需要枚举这个集合的所有子集,怎么办?
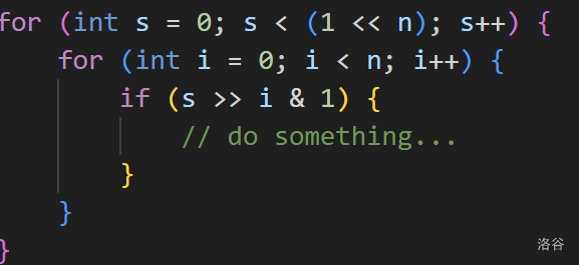
将一个数视为一个二进制串,0表示没选1表示选了,那么一个 范围内的数,就会唯一对应一个长度为 的二进制串,也就唯一对应一个选择方案。
使用位运算 获取这个二进制串从小到大的第 位。
复习一下位运算:两个选法并起来,交起来,把第 位设置为0/1,让第 位从0变1,从1变0。判断子集 是否包含子集 。
另外还有一个操作是枚举子集的子集。
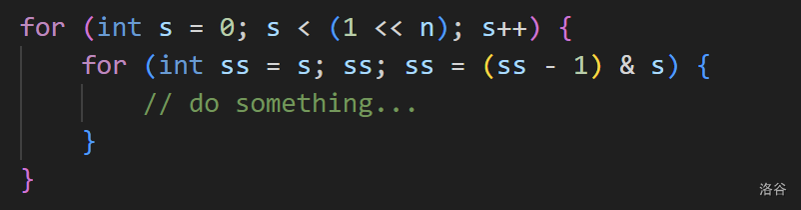
CPPint S; // 一个集合
int ans;
cin >> S;
// 需要特判空集
for(int S_ = S; S_; S_ < (S_ - 1 & S)) { // 枚举了所有的S_包含于S
if((S_ & S) == S_) { // 这一行保证S_是S的子集
int sum = 0;
for(int i = 0; i < n; ++ i)
if(S_ >> i & 1) // 这一行保证i属于S
sum += a[i];
ans ^= sum; // 异或和
}
}
最后,想想复杂度?
朴素dfs:
枚举子集:
枚举子集的子集:
问:现在,求所有子集的异或和之和。 过不去
答:使用dfs,或者使用 获得 的最低位。
CPP朴素dfs:
枚举子集:
枚举子集的子集:
问:现在,求所有子集的异或和之和。 过不去
答:使用dfs,或者使用 获得 的最低位。
int mem[(1 << 25) + 1];
for(int i = 0; i <= 25; ++ i) {
mem[1 << i] = i;
}
int f[(1 << 26)]; // f[s]表示s中所有数的异或和
// a[i]表示第i个数
for(int s = 0; s < (1 <<< n); ++ s) {
f[s] = f[s - lowbit(s)] ^ a[mem[lowbit(s)]];
}
分治:
序列分治:
其实所谓序列分治,就是像归并排序一样的思路:
- 合并:将分治的两边处理完之后,在本层合并,有时候就是简单相加。
- 统计:统计完分治两边的答案后,统计跨过分治中心的答案。
这一部分内容会在接下来的数据结构中有详细的拓展。
另外,之所以加上“序列”的前缀,是因为实际上还有“点分治”,“根号分治”等等更广义的分治,大家将会在以后学到。
solution:
首先,把所有点按照 坐标从小到大排序,紧接着,考虑分治。
我们将整个平面关于分治中心的横坐标竖着分成两半,然后分别对左右两边进行递归,得到答案 ,接着,考虑跨越分治中心的点对。
- 如果点 距离分治中心的距离比 大,那么它一定不会对答案造成贡献。
- 如果点 与点 对答案造成贡献,那么它们的纵坐标之差不会大于 。
- 如果两个点 和点 在同侧,那么它们的距离一定大于等于 。 于是,我们考虑把所有满足1条件的点按照纵坐标排序,紧接着对于每一个点 ,能够与它作贡献的点不会多于5个,暴力枚举即可。
把它转化成一个排列,求所有满足: 的排列数量。
我们考虑分治:每次只需要统计跨过区间中点的所有区间,那么我们只需要对于每个 ,找到所有满足条件的 即可。
将区间分为四类:最大最小值均在左侧,均在右侧,最大值在左而最小值在右,以及最大值在右而最小值在左。
如果是前两类,相当于另一个端点的前缀最大/最小值不能大于/小于某个数,这个限制是简单的。
如果是后两类,以第三类为例,我们枚举左端点,则右端点的最大值要比左端点的小,而右端点的最小值要比左端点的小,因此呈现出个区间,我们需要对于每一个 统计答案,开一个桶即可。
我们考虑分治:每次只需要统计跨过区间中点的所有区间,那么我们只需要对于每个 ,找到所有满足条件的 即可。
将区间分为四类:最大最小值均在左侧,均在右侧,最大值在左而最小值在右,以及最大值在右而最小值在左。
如果是前两类,相当于另一个端点的前缀最大/最小值不能大于/小于某个数,这个限制是简单的。
如果是后两类,以第三类为例,我们枚举左端点,则右端点的最大值要比左端点的小,而右端点的最小值要比左端点的小,因此呈现出个区间,我们需要对于每一个 统计答案,开一个桶即可。
归并排序求逆序对:
相信大家在普及组的时候已经对这个东西有着充分的了解了。
所谓归并排序,就是先递归到左边,排一下序,再递归到右边,排一下序,最后两个有序序列通过双指针合并,就得到答案。
而求逆序对,就是在每一层中考虑越过分界点的所有逆序对。
因为两边的序列已经有序了,我们只需要一个双指针就可以统计出所有逆序对了。
实现见代码。
所谓归并排序,就是先递归到左边,排一下序,再递归到右边,排一下序,最后两个有序序列通过双指针合并,就得到答案。
而求逆序对,就是在每一层中考虑越过分界点的所有逆序对。
因为两边的序列已经有序了,我们只需要一个双指针就可以统计出所有逆序对了。
实现见代码。
贪心:
所谓贪心其实就是不断地找当前的最优解,最后发现刚刚好是全局最优解!
所以贪心也是一种搜索,只不过我们每次只走眼下最好的一条路,因此如何合理地说明(众所周知,OI不需要证明,但是我们需要感受)眼下最好的路(局部最优解)一定可以带领我们走向答案(全局最优解)就是我们需要考虑的。
因此我们做贪心题的时候,做的事情是:
所以贪心也是一种搜索,只不过我们每次只走眼下最好的一条路,因此如何合理地说明(众所周知,OI不需要证明,但是我们需要感受)眼下最好的路(局部最优解)一定可以带领我们走向答案(全局最优解)就是我们需要考虑的。
因此我们做贪心题的时候,做的事情是:
- 找到一个贪心算法
- 检验它的正确性 我们可以通过例题总结一下常见的贪心套路。
solution:
贪心策略:每次放回去接下来最晚用到的玩具车。
怎么确定每个玩具车接下来第一次用是什么时间?
记数组 表示第 个位置与它相同的下一个位置是哪个位置,这个倒着扫一遍就可以预处理出来。
接下来只需要维护一个堆,不过我们需要让堆支持删除,但是这个没必要,因为有新的 在,旧的 就不会来到堆顶,因此我们让它留在那里就行,只需要 即可。
怎么确定每个玩具车接下来第一次用是什么时间?
记数组 表示第 个位置与它相同的下一个位置是哪个位置,这个倒着扫一遍就可以预处理出来。
接下来只需要维护一个堆,不过我们需要让堆支持删除,但是这个没必要,因为有新的 在,旧的 就不会来到堆顶,因此我们让它留在那里就行,只需要 即可。
我们的第一个做法是用数组 表示当前把集合s中的所有数纳入考虑后,最小的分组数量。那么转移当然是枚举 的子集,这样复杂度是 的,吸氧可以通过本题。
考虑一个简单的问题:如果我们要求物品必须是连续的若干个编号,那么这个问题是非常好做的:我们一定会加到不能再加,再去开新的一个组。
于是我们有另外一个暴力是,枚举全排列后贪心 。 那么,这个思路能不能搬到状态压缩上呢?记 表示最小分组数, 表示在最小分组数的基础上, 和最小的最后一组。转移是显然的。但是有个问题:转移之后如果这一组 和不再是最小了,我们不知道更小的是谁。不过这个完全不需要担心,因为如果不是这一组,我们在转移其他组的时候就会用更小的那一组把这一组的答案替代掉!
考虑一个简单的问题:如果我们要求物品必须是连续的若干个编号,那么这个问题是非常好做的:我们一定会加到不能再加,再去开新的一个组。
于是我们有另外一个暴力是,枚举全排列后贪心 。 那么,这个思路能不能搬到状态压缩上呢?记 表示最小分组数, 表示在最小分组数的基础上, 和最小的最后一组。转移是显然的。但是有个问题:转移之后如果这一组 和不再是最小了,我们不知道更小的是谁。不过这个完全不需要担心,因为如果不是这一组,我们在转移其他组的时候就会用更小的那一组把这一组的答案替代掉!
我们不加证明地给出一个贪心思路:每次选择带给我们收益最大的位置加速,重复 次得到的就是整体的最优解。
先跑一遍公交车,得到最初的等待时间和 。发现
我们按照公交车的滞留点分段,每一段选取第一条路并计算给这条路 ,可以节约多少时间。最后每一段取min。(按滞留点分段的原因是滞留点之后这次加速不会对答案有贡献。每次选第一条路的原因是因为上述公式告诉我们这一段路能贡献所有在滞留点之前下车的乘客)
先跑一遍公交车,得到最初的等待时间和 。发现
我们按照公交车的滞留点分段,每一段选取第一条路并计算给这条路 ,可以节约多少时间。最后每一段取min。(按滞留点分段的原因是滞留点之后这次加速不会对答案有贡献。每次选第一条路的原因是因为上述公式告诉我们这一段路能贡献所有在滞留点之前下车的乘客)
二分:
如果想要写对二分,就要认识到二分本质上是在做一个“找分界点”的事情。
举个例子,你在机房摸鱼,如果摸得时间短比赛就不会爆零,如果摸得时间长比赛就会爆零,现在,你要在比赛不爆零的前提下,让摸鱼时间尽可能长。 如果把图画出来就长这样: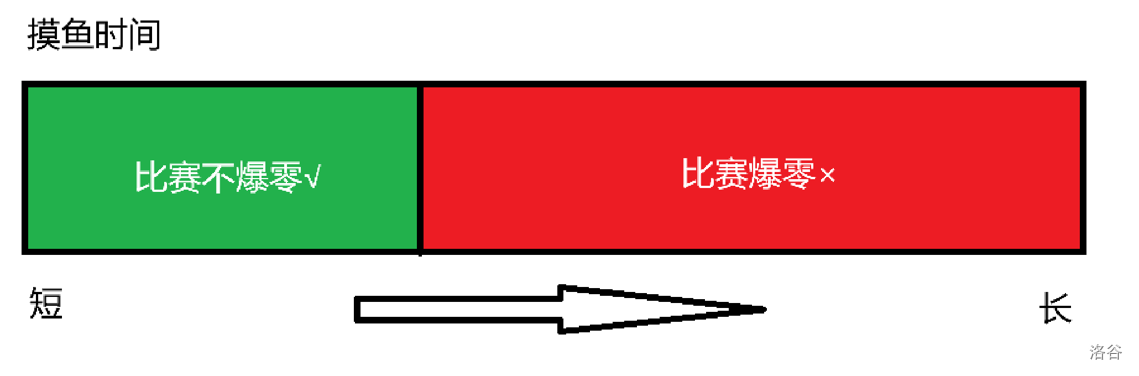 因此,我们想要找的就是这个位置。也就是“没爆零”的最后一个位置。
因此,我们想要找的就是这个位置。也就是“没爆零”的最后一个位置。
于是我们考虑在最短的摸鱼时间l和最长的摸鱼时间 之间,取一个中间点 。那么如果摸 时间的鱼没有爆零,代表它可以成为一个答案,我们就把答案更新并且让 。否则,如果它爆零了,代表它根本不能成为一个答案,因此我们直接将 而不更新答案。
很容易可以写成代码。
举个例子,你在机房摸鱼,如果摸得时间短比赛就不会爆零,如果摸得时间长比赛就会爆零,现在,你要在比赛不爆零的前提下,让摸鱼时间尽可能长。 如果把图画出来就长这样:
因此,我们想要找的就是这个位置。也就是“没爆零”的最后一个位置。于是我们考虑在最短的摸鱼时间l和最长的摸鱼时间 之间,取一个中间点 。那么如果摸 时间的鱼没有爆零,代表它可以成为一个答案,我们就把答案更新并且让 。否则,如果它爆零了,代表它根本不能成为一个答案,因此我们直接将 而不更新答案。
很容易可以写成代码。
solution:
二分从哪个申请人开始会有订单无法满足。那么绿色部分代表的是“可以满足所有订单”,红色部分代表“不能满足所有订单”。我们要找红色部分的最左边那个哥们。
确定了 作为所有申请人之后,利用差分可以得到每天的教室需求。只需要判断需求量 与 的关系即可。
确定了 作为所有申请人之后,利用差分可以得到每天的教室需求。只需要判断需求量 与 的关系即可。
第一个问题要求我们计算最长不上升子序列的长度。
开一个 数组,代表到第 个位置为止,长度为 的不上升子序列,最后一个位置最大是多少。我们从1到 依次枚举 ,考虑利用 更新 数组,即我们希望找到一个以 结尾的不上升子序列。
开一个 数组,代表到第 个位置为止,长度为 的不上升子序列,最后一个位置最大是多少。我们从1到 依次枚举 ,考虑利用 更新 数组,即我们希望找到一个以 结尾的不上升子序列。
- 数组本身应该是单调不上升的。
- 如果 ,那么它们可以与 拼成一个不上升子序列,结尾为 ,可以用来更新 。
- 如果 ,那么它们不能与 拼成一个不上升子序列。
- 如果 ,那么它们没有必要被 更新。
综上所述,我们需要找到第一个小于 的,将它的值改为 ,二分即可。
对于第二问,我们考虑一个贪心。每次选取当前能覆盖它的导弹当中,高度最低的那个。如果没有这样的导弹,那么新开一个。
也就是我们要二分找到高度 的所有导弹中,高度最低的那个,同样可以二分。
发现这样求出来的结果与最长上升子序列的求法本质相同。
对于第二问,我们考虑一个贪心。每次选取当前能覆盖它的导弹当中,高度最低的那个。如果没有这样的导弹,那么新开一个。
也就是我们要二分找到高度 的所有导弹中,高度最低的那个,同样可以二分。
发现这样求出来的结果与最长上升子序列的求法本质相同。
二分中位数的值,接下来把所有数按照小于中位数和大于等于中位数分成0和1两部分。则我们的横坐标是中位数大小,绿色部分是存在连续子序列使得1的个数大于0的个数,红色部分是不存在。我们希望找到绿色部分最靠右的那个数。
接下来就是一个简单的前缀和。
接下来就是一个简单的前缀和。
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...