专栏文章
[模版]并查集
P3367题解参与者 11已保存评论 10
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 10 条
- 当前快照
- 1 份
- 快照标识符
- @mipw7rf9
- 此快照首次捕获于
- 2025/12/03 18:57 3 个月前
- 此快照最后确认于
- 2025/12/03 18:57 3 个月前
题目分析
题面要你资瓷 个操作:
-
合并两个集合
-
判断两个集合是不是在一个集合里
算法介绍
你可能需要知道的前置知识:树,时间复杂度的表示。
先来看看第一个操作怎么实现,否则实现第二个操作就是天方夜谭。
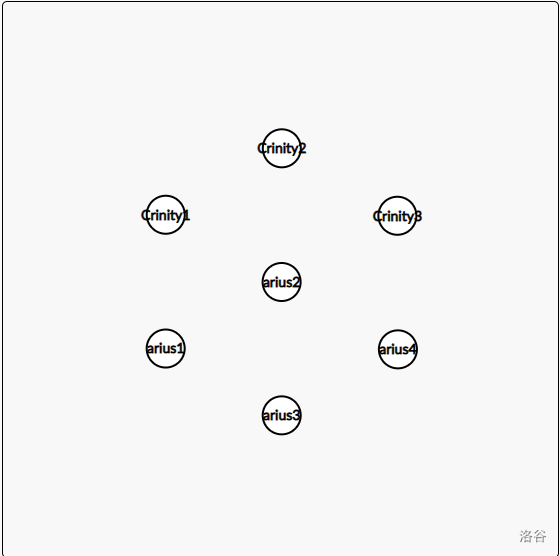
如图,这里有两个集合 Crinity(简称 c)和 arius(简称 a),我们要把这几个点塞到一起去。
注:你当然不用担心怎么存集合的名字,因为用不着。大不了用 , 这些数字代替就是了。
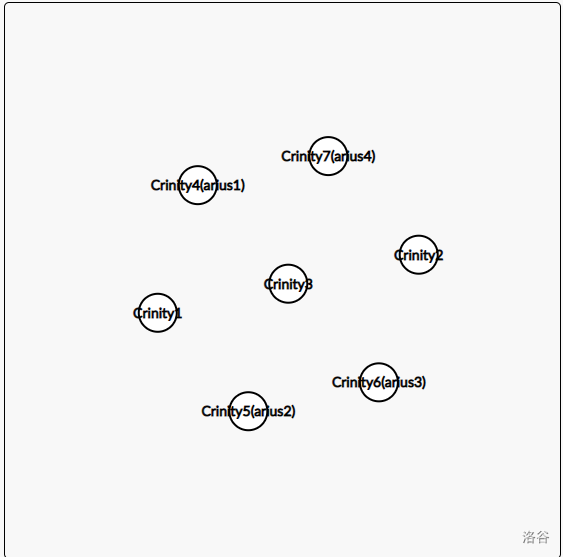
一个比较简单的想法是:我用一个数组存下所有点是哪个集合的。然后每次遍历一遍数组,把 这个集合里的元素全部标记成属于集合 ,就像这样:
但是我们会发现,假如几乎全都是操作 ,这样做的复杂度将会被卡到 ,但看一眼数据范围,那显然爆炸了。怎么办呢?
其实,这并不意味着这个想法完全是错的。如果我们能找出几个固定的点来代替整个集合,那我只要改这几个点就好了。
那我要拿什么去维护它呢?
答案简直就是呼之欲出了——树。
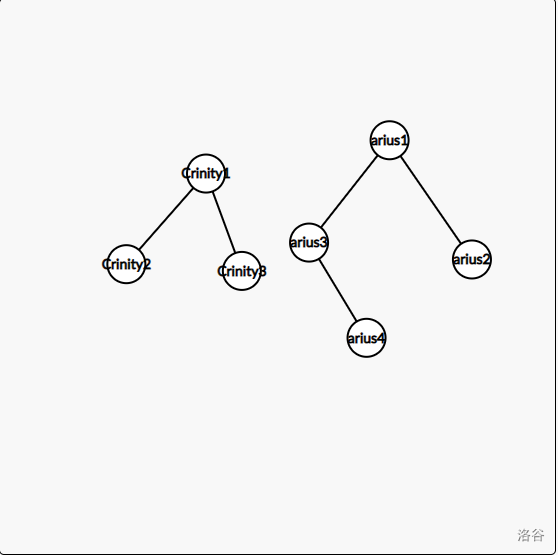
树就是像这样的东西。然后我们有一个很好的性质,就是我把这个 c1 和 a1 一连,就 的把两棵树,也就是两个集合合并了。
但这样一个行为,又带来几个问题:
1. 怎么去存这些树啊?
要是你用二维数组存,不说别的,空间都开不下。要是硬开的话,直接不给你编译了!
于是,有一个很好的想法,就是说,我新开一个数组 ,每个点都存那个图里跟它连线,而且在它上面的那个点(按照术语来说,就是它的父亲)不就好了么?反正那个所谓“父亲”也是唯一的!而对于每棵树最上面那个点(按照术语来说,就是树的根节点),直接让它的父亲是自己得了~
其实这样,我们不就会写操作 了吗,判一判是不是拥有同一个根节点不就好了~
2. 你要合并的时候,我给的不一定是树的根节点啊?万一不是根节点怎么办?直接连这两个点不就乱套了?
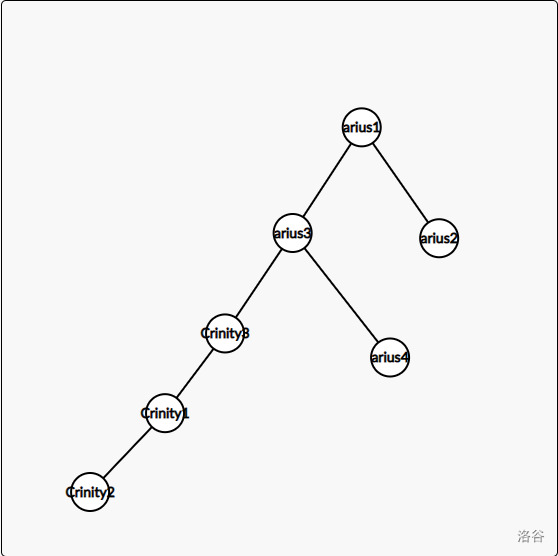
这里说明一下,之所以不能直接连,是因为这样:比如说给的点是 c3 和 a3。那我把 c3 连 a3 身上,就像这张图一样,那 c 这棵树就倒过来了。不然,你 有两个父亲,一棵树有两个根节点,那还行?复杂度先不说,你连维护这棵树倒过来都很难做到!其实你真写出来也是TLE
所以,我肯定得找到祖先。那祖先怎么判定呢?显然,假设 是祖先,那肯定有 嘛!
那我只要发现,我的父亲不是根节点,那就把这个问题丢给父亲,让它去判断我的祖父是不是根节点嘛!就这样,我们可以递归的解决这个问题:
CPPint find(int k){ //返回的值就是根节点的编号
if(f[k]==k) return k; //现在这个点就是根节点
else{
int ans=find(f[k]); //把问题丢给父亲解决~
return ans;
}
}
所以合并和判断也就好解决啦:
CPPvoid Union(int a,int b){ //操作1
f[find(a)]=f[find(b)]; //根节点连线,简单粗暴
}
bool check(int a,int b){ //操作2
if(find(a)==find(b)) return true;//让我看看根节点一不一样!
return false;
}
于是就能就能轻松写出代码啦~
完结撒花 了吗?
如果你实现完了,你交上去,发现你获得了 分的好成绩!
冷静下来,考虑这个图:

我每次让你查 ,你就得遍历一遍,数据一大,又变回 了!
那怎么办呢?
其实也很简单:使用路径压缩。
那么,什么是路径压缩呢?
我们发现,在图中,如果我们发现 的父亲是 ,那我直接把他的父亲更改为 ,那么下次遇到 ,我就不用再搜一整条链了。
同理,搜索过程中,把 到 的父亲改一下,我们就不用再搜一遍了。
那么图就会变成这样了:
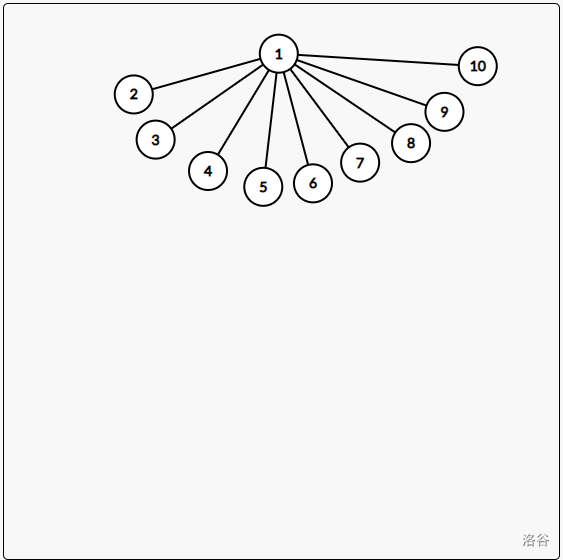
路径压缩的代码:
CPP//其他一样啦~
int find(int k){
if(f[k]==k) return k;
else{
f[k]=find(f[k]); //修改父亲,即路径压缩
return f[k];
}
}
但是我们当然不能只局限于通过此题,带来一个看起来很玄学的优化。也可以说是一种优化思想。
启发式合并
思考一下,并查集的复杂度当然是与树的高度息息相关。
比如说这张图:
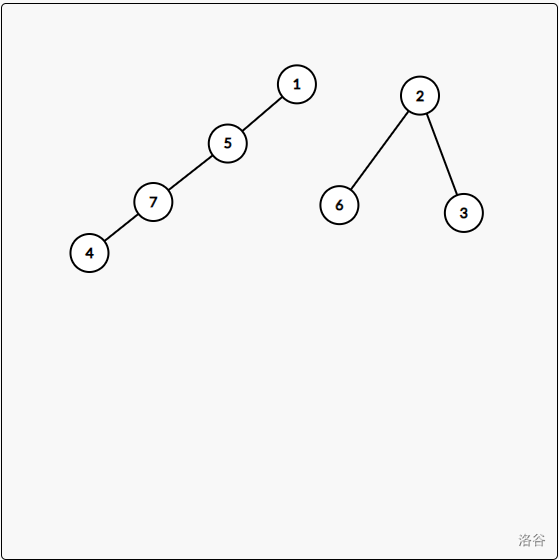
我把 连 上,树就有 层。但反过来做,我就只有 层了。既然有要操作这么多次,那么它总是有作用的。
那每次合并时,我总把矮的树合并到高的上面,就能有效加速了。
代码如下:
CPPvoid Union(int a,int b){
//ht是树的高度(只管根节点的就好了)
a=find(a),b=find(b);
if(ht[a]<ht[b]) swap(a,b);//启发式合并
ht[b]=max(ht[b],ht[a]+1);
f[a]=f[b];
}
初始树的高度都是 。
时间复杂度与正确性证明
Tarjan 大神曾经证明过,其复杂度不会超过 (只使用路径压缩)。而其均摊复杂度,姚期智大神曾证明为 。
其中 是反阿克曼函数。可以视为一个常数。因为如果它不能视为常数的时候神威太湖之光都得跑到天荒地老具体的说,在 的时候,都有 ,当成常数没有不妥。
使用启发式合并后,最低复杂度稳定为
,不会被卡。对于这些复杂度的证明,由于其过于繁杂,这里略去。具体证明可以看此处:
https://oi-wiki.org//ds/dsu-complexity/ 。
代码实现
CPP#include<bits/stdc++.h>
using namespace std;
int f[2000010],ht[2000010];
int a,b,c,n,m;
int find(int k){
if(f[k]==k) return k;
else{
f[k]=find(f[k]);
return f[k];
}
}
void Union(int a,int b){
a=find(a),b=find(b);
if(ht[a]>ht[b]) swap(a,b);
ht[b]=max(ht[b],ht[a]+1);
f[a]=b;
}
bool check(int a,int b){
if(find(a)==find(b)) return true;
return false;
}
int main(){
scanf("%d %d",&n,&m);
for(int i=1;i<=n;i++) f[i]=i,ht[i]=1;
for(int i=1;i<=m;i++){
scanf("%d %d %d",&a,&b,&c);
if(a==1) Union(b,c);
else{
if(check(b,c)==true) printf("Y\n");
else printf("N\n");
}
}
return 0;
}
并查集的进阶用法
*:该拓展中,路径压缩毫无意义。
完结撒花。
相关推荐
评论
共 10 条评论,欢迎与作者交流。
正在加载评论...