专栏文章
Day 03
算法·理论参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @miqeobm7
- 此快照首次捕获于
- 2025/12/04 03:34 3 个月前
- 此快照最后确认于
- 2025/12/04 03:34 3 个月前
树状数组
树状数组基本上是线段树的弱化但又快又好写版本。
维护一个比线段树更快的数据结构,支持对序列:
- 单点加
- 查询前缀和 前缀最大值。
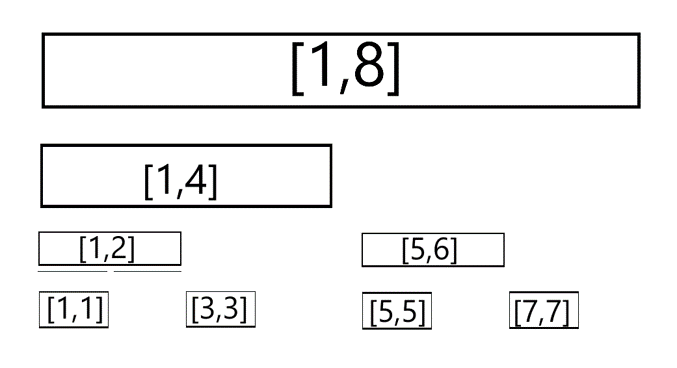
我们魔改一下线段树的结构,删掉每个结点的右儿子。
得到的这个结构仍然保留树的形态,不过我们发现每个位置只会成为唯一一个区间的右端点,因此我们实际上只有线性的 个区间。
因此我们管这种数据结构叫做“树状数组”。
lowbit
观察:如果我们记 表示数 二进制表示从右往前最低位的 与它之前的所有 构成的数,例如 ,那么 。
利用二进制补码的性质,我们可以得到 & 。
我们发现,树状数组的位置i刚好维护了 这个长度为 的区间。
因此我们只需要一个 循环就可以轻松维护出树状数组。
二叉搜索树
维护一个数据结构,它是一个集合,支持:
-
加入一个数
-
删除一个数
-
查询一个数的排名 ,即比它小的数个数
-
查询第 小数 ,即从小到大排序后第 个位置上的数
-
查询一个数的前驱 pre
-
查询一个数的后继 suc
你只需要一个平均复杂度 的算法,不需要保证最坏复杂度。
我们依然使用一棵二叉树去维护这个集合。
这棵二叉树需要满足:一个结点的权值,大于它左儿子的权值,小于它右儿子的权值,如果有相同权值,那么在这个结点的 上 。
那么这个二叉树看上去就像是把一个排好序的数组“提起来”(换句话说,这个二叉树的中序遍历有序)
那么它为什么叫做“二叉搜索树”呢,因为这棵树可以非常方便地替我们完成“搜素一个值”这个任务。
从树根出发, 每次检查这个值与当前结点的权值的大小关系,如果相等那么找到了,否则如果值比当前结点小,那么向左走,不然向右走。复杂度 树高 。
接下来我们开始分别实现这 个功能:
-
插入,从根开始,如果能搜素到这个值那么直接 ,不然在搜素到的那个空位置新建一个结点存放这个值。
-
删除,我们最好使用惰性删除,也就是把这个点删了但是这个空点还留在树上。
-
查询一个数的排名,我们在二叉搜索树上查找这个数,如果下一步递归到右儿子,那么将排名增加 左儿子 当前点 ,最后如果找到了,还需要加上 左儿子 。
-
查询第 小,我们同样在二叉搜索树上从根开始搜素,不过这次变成了:从根开始,如果 左儿子 ,那么向左儿子递归。如果 左儿子 当前点 ,那么当前点就是答案,否则把 减去 左儿子 当前点 ,然后向右递归。
-
查询前驱,其实就是
-
查询后继,其实就是
二叉搜索树和线段树
其实二叉搜索树可以看成某种意义上的线段树,这意味着它可以承担一些区间操作的任务,也可以打懒标记。 比如 和 可以做的区间
同理,线段树也可以视作一种二叉搜索树,这让它也可以维护一个集合。 动态开点权值线段树
平衡树
二叉搜索树最坏时间复杂度显然是 的,其原因在于这棵搜索树可以长得很不“平衡”,最平衡的二叉树就是完全二叉树
因此我们想出了各种奇奇怪怪的方法让二叉搜索树保持平衡,来让它能够真正达到 的时间复杂度。
这里给大家介绍一个非常简单但不是很实用的平衡树:替罪羊树。
它的思路很简单暴力:我们不平衡,那么我们每当整棵树不平衡到一个程度了,就把它整个推平重构成一棵完全二叉树。
这个所谓“不平衡到一个程度”,我们认为:其左或右儿子的大小 整个子树大小的 倍,或者删除的点的数量占整棵树的 倍。
因为这个操作支持删除不是很容易,因此我们直接采用懒惰的方法,如果一个结点的 为 就把它留在那里不动它。
可以通过一些深刻的复杂度证明它的复杂度是 的。
字符串
字符串当然就是由若干字符拼成的串。
关于字符串,我们讨论的其中一个就是字符串的“匹配”问题,也就是说,我给出两个字符串,你怎么知道其中一个串是另一个串的子串?它在多少地方出现了?这也是我们本次课研究的问题。其它的问题,我们会放到今后学习各种子串黑科技 后缀数组,后缀自动机,基本子串结构 的时候。
概念:
- 字符集:就是字符串里所有字符构成的集合。
- 子串:就是字符串的一个区间。
- 前缀 后缀:就是字符串一个从 开始的区间和一个以 结尾的区间。
哈希
什么是哈希?哈希是一种容易被卡的算法。
哈希是一种不能保证正确性的算法,但是这不代表你使用哈希会被随机扣分。
它的运作思路是:我们把一个字符串不一一对应地对应到一个数上,然后比较这两个数就可以得到这两个字符串的关系了。
那么,怎么对应呢?
字符串哈希
我们使用这样一种哈希方法:
将整个字符串视为一个 进制的数字对一个大质数 取模得到的数字。
譬如,对于字符串 ,这种哈希值对应的结果就是 。
其中 和 的值可以随便取,一般 取 或者 , 取 或者 。
那么,两个相同字符串的哈希值显然是相同的。
更进一步地,我们可以轻松地求出这个字符串所有子串的哈希值。
哈希冲突
一个 长度的字符串,子串的个数将近 ,可是你的模数只有 ,这就意味着这个字符串几乎一定会出现两个不同的子串具有相同的哈希值,那么如果你比较这两个子串,就会得到错误的结果,也就是我们所说的“哈希冲突”。
某种意义上,哈希冲突是无法规避的。然而,这种冲突发生的概率非常微小(你不可能把所有 个子串两两比较)。因此,我们期望它不会在自然状态下出现这种情况。
如果你不想让 比赛的出题人人为地卡掉你的哈希,那么一个办法是使用不太常见的模数比如 ,不过通常不会有毒瘤出题人会专门设计卡某一个特定哈希值的数据。如果你遇到了,就狠狠地喷会遭世人唾骂的出题人
不过,一个更保险的方法是使用双值哈希。顾名思义,就是同时用两套 和 去计算哈希值,这样相当于有了一个双重保险。就几乎不可能出错了,被卡也很难。
哈希表
维护一个数据结构,是一个集合,支持:
- 插入一个 对
- 删除一个 对
- 查询一个 对应的数是什么。
要求总共接近 地做完这些事情。
我们采取一个极端措施:给插入的值对一个 左右的数取模 。把得到的数当作 的数组下标。
但是因为这个数很小,所以很容易出现哈希冲突,怎么办呢?
答案是把这个 数组拓展成一个链表。每次插入一个数,如果发现这个数与其它的数哈希冲突了,就把它挂在先前的这个数后面。
这样就可以做到一个几乎线性的查询复杂度,显著优于同台竞争的线段树和平衡树。
Trie树
我们现在有很多字符串,怎么判断哪些字符串出现过,哪些字符串没有出现过呢?
我们考虑一本字典,如果我们想要在一个字典中找到某个单词,我们的做法是:首先找它的第一个字母,翻到指定页数后开始找第二个字母,如法炮制。
发现这个过程很像一棵树,因此我们可以模仿这个过程建一棵树,我们称为 树。
显而易见地,对于一个小写字母字符集而言, 树的每个结点需要一个 来存储它的 个儿子,但是无论是插入还是查找都是 的。
不仅仅可以用来存储字符串,也可以用二进制的形式存储数!
因此我们瞬间得到了一个树高 值域的二叉搜索树!(当然,与一般的二叉搜索树略有不同)
瞬间就变得非常厉害了!
唯一的不足是花费的空间和时间是同阶的,都是 ,但是常数要比平衡树优秀很多,可以作为一个低配的平衡树使用。
字符串匹配
给定长一点的字符串 (称为文本串)和短一点的字符串 (称为模式串),求 在 中的哪些位置出现(找T出现位置的开头位置)
要求
不能使用哈希。
KMP算法
这个名字是三个人的首字母。
它涉及到一个比较深刻的东西,叫做 。一个字符串 的 是 的一个子串 ,满足 既是 的前缀又是 的后缀,且 不是 本身。
几个 的例子:
算法的原理是:对于字符串 ,找出它所有前缀的最长 的长度。
这是
| 的前缀 | |||||
|---|---|---|---|---|---|
| 最长 | |||||
| 最长 长度 |
那么,找到 有啥用呢?
我们考虑暴力字符串匹配的过程
,
我们枚举 在 上的起点 ,然后用 一位一位地匹配。发现 的时候寄掉了。此时我们需要从 再重新匹配吗?并不需要。我们匹配了子串 ,那么下一个有可能成为 匹配位置的起点会长成这样。
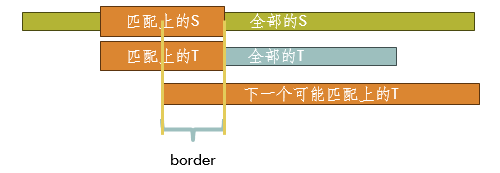
所以问题就很显然了。我们下一步并不需要从头开始,而只需要从 的 位置开始即可。
那么我们的算法流程是:失配 跳 再失配 再跳 。
这样,我们每次在 上移动一步,在 上也移动了一步, 最多增加 ,于是我们最多只会增加 次 ,那么自然也最多回跳小于 次 ,复杂度于是就是 。
因为这个跳 的操作有点像指示失配之后“下一个”位置在哪的数组,因此有人用 数组表示 。
欸,还没讲怎么求最长 呢。
说起来简单,因为我们用到的 不会超出 ,因此直接将 和自己匹配即可。
具体来讲,我们可以依次求出每个位置的 ,因为我们每次要求 的时候,只需要比较 和 是否相等即可,如果不相等,那么就是失配了,我们继续跳 。
| 的前缀 | ||||||
|---|---|---|---|---|---|---|
| 最长 | ||||||
| 最长 长度 |
STL
模板
相信大家至少用过
std::queue<int>,并都对这个 非常好奇它为啥可以这么写。实际上这个东西是 的一个语法,它的作用类似于我们学过的“通配符”,可以检测任何一种类型,甚至是你自己定义的 。
比如, 的实现是这样的。
你不用管那些吓人的语法,我们将重点落在这里。
这就是我们的那个类型名的位置。
这个 决定了 是相当泛用的。
容器
容器就是 里的数据结构,是拿来存放数据的瓶瓶罐罐。
容器分为序列容器 ,关联容器 和其它容器 。
你可以简单理解为,数组,平衡树,和 。
它们是一个个的 你可以把它们当作 来用 ,怎么用?
std:: vector <int> vec;从左到右分别是命名空间 ,容器名,模板参数,变量名。
然后你就获得了一个名叫 的,里面存放 类型的 容器。
迭代器
迭代器像是 版本的指针,用来在容器的各个元素之间移动。
首先,我们造一个 , ;
这一行从 这个类中找出它里面的一个类 ,用它定义了一个变量 。
那么这个 就可以在 上乱转了,比如
如果想要访问 指向的值,就需要使用 。
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...