专栏文章
支配树详解
算法·理论参与者 24已保存评论 29
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 29 条
- 当前快照
- 1 份
- 快照标识符
- @mhz5syf8
- 此快照首次捕获于
- 2025/11/15 01:56 4 个月前
- 此快照最后确认于
- 2025/11/29 05:24 3 个月前
2019.3.3 update:修改了证明的格式,给模板代码加上注释
2019.3.3 update:加上了一道例题讲解
2019.3.3 update:加上了latex
支配树概念
给定一个有向图,给定起点S,终点T,要求在所有从S到T的路径中,必须经过的点有哪些(即各条路径上点集的交集),称为支配点。简而言之,如果删去某个点(即支配点),则不存在一条路径能够使S到达T。由支配点构成的树叫做支配树
假设下图为给定的有向图
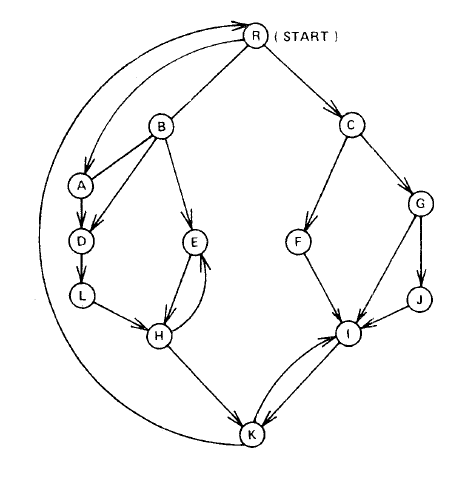
支配树的性质
支配树是一颗由起点S为根的树,根到树上任意一点路径经过的点都是它的支配点。
对于每颗子树,都符合上述性质(即子树内一点到该子树的根路径经过的点都是该子树的根的支配点)
支配树的算法——Lengauer Tarjan
前置知识
学会构建dfs树,对于dfn序有简单的了解
对于树上两点路径有初步的认识,知道LCA的概念
知道带权并查集的合并方法(合并子树时需要使用)
主要变量
1:,表示x的dfs序(若没有说明,下文文中节点大小比较默认为比较两个点的dfn大小)
2:,表示x的半支配点
3:,表示x的最近支配点
4:完全祖先:不包含自身的祖先节点
5:完全后代:不包含自身的子节点
关于 树,此处存在一个定理
若 是 树上的任意两个节点,那么从u到v的路径上必然存在某个点为这两个点的 (最近公共祖先)
证明:对于树上两点的路径,必然存在一个深度最小的点,使得两点路径必然经过该点。可以形象理解为一个爬树的过程,即从一个点出发,慢慢向上爬,必然访问到一个最高点后再慢慢向下走,最终访问到另外一个节点,那么那个最高点就可以形象地理解为这两个点的LCA。
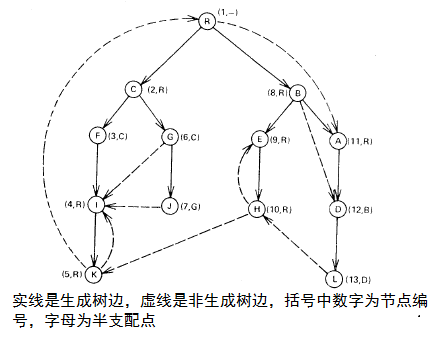
关于半支配点
定义
对于一个节点U,存在V能够通过许多点(不包含V和U)到达点U
且对于任意i都有,对于所有满足条件的V中能使dfn[V]最小的V称为半支配点 即
简而言之 {存在路径使得对成立}.
性质
1:半支配点是唯一的(但是支配点可以有多个)
证明:根据半支配点的定义,因为是路径中节点的最小值,所以只有一个
2:对于任意点w,它的半支配点必定是它在上的祖先
证明:假设w在dfs树上的父亲节点为,根据dfs树的定理可知,必然有。
且存在一条路径 ,使得对成立。}
又根据dfs树的性质,存在某一节点。
但因为,所以,且是的一个完全祖先,结论得证
3:对于任意节点(w不等于起点s)的支配点必然是该节点的半支配点的祖先节点
证明:根据上述性质,我们可以证明和是节点的完全祖先。
假设我们已经得到了一条从起点到的链,根据半支配点的定义,这条路径中必定不包含w的完全祖先和的完全后代,那么必然是的祖先节点,结论得证
4:假设 存在且是的祖先,那么不为v的后代就为的祖先
证明: 设存在某一x是的任意一个完全后代,且同时是v的完全祖先。
则必然存在一条从s到v且不经过x的路径。我们再找到一条从v到w的路径,将这两条路径连接起来,我们就得到了一条从s到w不经过x的路径。
因此要么是v的后代,要么是的祖先。
求取方法
对于任意点,若点U和点V之间存在路径
=({v|(v,u)∈E且v<u}∪{sdom[k]|k>u}且存在边(v,u)满足k是v的祖先})
简而言之
CPPif(dfn[u]>dfn[v]) sdom[u]=min(v);
else sdom[u]=min{sdom[k]}
//对于∀k满足dfn[k]>dfn[U]且k能到达U
证明(本段证明翻译于tarjan的本人思路):
设x等于上式右端。我们首先证明。
如果x使得x能到达w且,那么有。
另一种情况,,,且存在边满足u是v的祖先节点。
存在一条路径{,使得对成立。}
而树上路径满足对成立。
因此路径满足对成立。所以。
我们还需要证明。
假设存在一条路径={,使得对成立。}
若k=1,那么存在一条路径从到w。而根据上述引理,却有。于是。
对k>1的另一种情况,设j是使得并且是的祖先的最小值。这样的j一定存在,因为j可以等于k-1.
我们断言:对于,成立。
否则,我们选取所有满足且的i中使得v_i最小的那个。
由上述性质,是祖先,和j的选择矛盾。这证明了结论。
根据上述证明, >=x。因此无论k=1还是k>1,都有,定理得证.
虽然看起来很复杂,但是仔细理解一下还是容易看懂的(我自己实在想不出能够比这个更合理更正确的证明方法,就直接引用原文了)
关于最近支配点
定义
如果图中存在节点v,w,且v支配w,并且w的其他支配点均支配v,我们就称v是w的最近支配点,记作
应用
通过已知推导得
令集合P={到路径上的点集}
令元素
CPPif(sdom[k]==sdom[x]) idom[x]=sdom[x]
else idom[x]=iodm[z]
证明(不好意思又是来自tarjan老爷子的论文,我努力简化了一下,尽量不违背原文意思,毕竟不能误人子弟):
若需要证明上述结论,只需要分别证明两个结论
考虑支配了w。
考虑任意一条从s到w的路径p。设x为这条路径上最后一个满足的点。若无此x,则一定支配w。
否则,设y是路径上x之后,满足是y的完全祖先,而y又是w的完全祖先的第一个点。
设路径是路径p中从x到y的一部分。对于,有。
否则如果有,那么存在某个满足的是y的祖先。由于x的选择方式,一定有,这意味着和y的选择矛盾。从而证明了上述观点
这一观点加上半支配点的定义,成功得到了.根据定理的假设,y不可能是的完全后代。这意味着,且位于路径p上。由于路径p是任意的,支配了w。证毕。
关于算法实现
1:先对这张图进行一遍dfs,求出dfn
2:求出sdom
根据sdom的上述性质,我们可以通过根据dfn大小从大到小遍历,那么我们查询的都是祖先链,根据定义我们可以很轻松地求出sdom
3:保留dfs tree 上的节点和边,那么显然,原图变为了一个DAG
然后再将点丢到支配树中,在做这个操作之前,我们需要先求出该点祖先链中sdom的最小值,然后这个点会成为一颗子树的根,通过带权并查集维护各个子树并连接。最后通过sdom求出idom,算法就完成了
代码实现
题意:给定一张有向图,求从1号点出发,每个点能支配的点的个数(包括自己)
CPP#include<bits/stdc++.h>
using namespace std;
using namespace std;
inline int read()
{
int x=0;
char c=getchar();
bool flag=0;
while(c<'0'||c>'9') {if(c=='-')flag=1;c=getchar();}
while(c>='0'&&c<='9'){x=(x+(x<<2)<<1)+ c-'0';c=getchar();}
return flag?-x:x;
}
const int N=2e5+10;
int n,m,ans[N],dfn[N],id[N],tot,dep[N];
int ffa[N],fa[N],semi[N],val[N],du[N],ff[25][N];
queue<int>q,q1;
vector<int>cg[N];
struct node
{
vector<int>edge[N];
inline void add(int u,int v){edge[u].push_back(v);}
}a,b,c,d;
inline void dfs(int x,int f)
{
dfn[x]=++tot,id[tot]=x,ffa[x]=f,c.add(f,x);
for(int i=0;i<a.edge[x].size();++i) if(!dfn[a.edge[x][i]]) dfs(a.edge[x][i],x);
}
inline void dfs_ans(int x)
{
ans[x]=1;
for(int i=0;i<d.edge[x].size();++i) dfs_ans(d.edge[x][i]),ans[x]+=ans[d.edge[x][i]];
}
inline int find(int x)
{
if(x==fa[x]) return x;
int tmp=fa[x];fa[x]=find(fa[x]);
if(dfn[semi[val[tmp]]]<dfn[semi[val[x]]]) val[x]=val[tmp];
return fa[x];
}
inline int LCA(int x,int y)
{
if(dep[x]<dep[y]) swap(x,y);
int d=dep[x]-dep[y];
for(int i=20;i>=0;i--) if(d&(1<<i)) x=ff[i][x];
for(int i=20;i>=0;i--) if(ff[i][x]^ff[i][y]) x=ff[i][x],y=ff[i][y];
return x==y?x:ff[0][x];
}
inline void tarjan()
{
for(int i=n;i>=2;--i)
{
if(!id[i]) continue;
int x=id[i],res=n;
for(int j=0;j<b.edge[x].size();++j)
{
int v=b.edge[x][j];
if(!dfn[v]) continue;
if(dfn[v]<dfn[x]) res=min(res,dfn[v]);
else find(v),res=min(res,dfn[semi[val[v]]]);
}
semi[x]=id[res],fa[x]=ffa[x],c.add(semi[x],x);
}
for(int x=1;x<=n;x++) for(int i=0;i<c.edge[x].size();++i) du[c.edge[x][i]]++,cg[c.edge[x][i]].push_back(x);
for(int x=1;x<=n;x++) if(!du[x]) q.push(x);
while(!q.empty())
{
int x=q.front();q.pop();q1.push(x);
for(int i=0;i<c.edge[x].size();++i) if(!--du[c.edge[x][i]]) q.push(c.edge[x][i]);
}
while(!q1.empty())
{
int x=q1.front(),f=0,len=cg[x].size();q1.pop();
if(len) f=cg[x][0];
for(int j=1;j<len;j++) f=LCA(f,cg[x][j]);
ff[0][x]=f,dep[x]=dep[f]+1,d.add(f,x);
for(int p=1;p<=20;p++) ff[p][x]=ff[p-1][ff[p-1][x]];
}
}
int main()
{
n=read(),m=read();
for(int i=1;i<=n;i++) fa[i]=val[i]=semi[i]=i;
for(int i=1;i<=m;i++)
{
int u=n-read()+1,v=n-read()+1;
a.add(u,v),b.add(v,u);
}
dfs(n,0);tarjan();dfs_ans(n);
for(int i=n;i>=1;i--) printf("%d ",ans[i]);
}
题意:给定一个DAG,求如果删去一个点有多少个点会被影响(即灭绝)
分析:其实看明白了就是一道支配树板子题。因为每个点之间都存在依赖关系,如果删去某个点,对于任意一个原先有入度的点说,如果因此没有入度,那么它就死了,并且删除与它相连的边,然后重复迭代以上步骤直到没有点死去
然后我们把边反向然后观察可以发现:如果说删除了一个点后某个点无法连向原图中无入度的点(注意是原图中的入度,反图中就是出度),那么它就死了
但是对于原图中,存在某些点没有入度(即生产者,不依赖任何东西),那么我们只需要建一个超级源点把这些没有入度的点连接起来,然后跑网络流,那么那个点则为我们的起点,而题目也转换为模板题了
代码
CPP#include<bits/stdc++.h>
using namespace std;
inline int read() { int x=0; char c=getchar(); bool flag=0;
while(c<'0'||c>'9') {if(c=='-')flag=1;c=getchar();}
while(c>='0'&&c<='9') {x=(x+(x<<2)<<1)+ c-'0';c=getchar();} return flag?-x:x;
}
const int N=2e5+5;
int n,m;
struct node {
vector<int>edge[N];
inline void add(int u,int v) {
edge[u].push_back(v);
}
} a,b,c,d;
int dfn[N],id[N],fa[N],cnt;
//dfn表示dfs序,id表示序号所对应的点,fa记录点u的父亲节点
void dfs(int u)
{
dfn[u]=++cnt;id[cnt]=u;
int len=a.edge[u].size();
for(int i=0; i<len; ++i)
{
int v=a.edge[u][i];
if(dfn[v])continue;
fa[v]=u;
dfs(v);
}
}
int sdom[N],idom[N],bel[N],val[N];
//sdom表示半支配点,idom表示支配点
//val[x]表示从x到其已经被搜过的祖先的dfn的最小值val[x]
//bel[x]表示并查集中的fa
inline int find(int x)
{
if(x==bel[x])return x;
int tmp=find(bel[x]);
if(dfn[sdom[val[bel[x]]]]<dfn[sdom[val[x]]]) val[x]=val[bel[x]];
//用sdom[val[x]]更新sdom[x]
return bel[x]=tmp;
}
inline void tarjan()
{
for(int i=cnt; i>1; --i)//在dfs树上遍历,从大到小
{
int u=id[i],len=b.edge[u].size();
for(int i=0; i<len; ++i)
{
int v=b.edge[u][i];
if(!dfn[v])continue;//不在dfs树上
find(v);
if(dfn[sdom[val[v]]]<dfn[sdom[u]]) sdom[u]=sdom[val[v]];
}
c.add(sdom[u],u);
bel[u]=fa[u],u=fa[u];
len=c.edge[u].size();
for(int i=0;i<len;++i)
{
int v=c.edge[u][i];
find(v);
if(sdom[val[v]]==u) idom[v]=u;
else idom[v]=val[v];
}
}
for(int i=2;i<=cnt;++i)
{
int u=id[i];
if(idom[u]!=sdom[u]) idom[u]=idom[idom[u]];
}
}
int ans[N];
void dfs_ans(int u)
{
ans[u]=1;
int len=d.edge[u].size();
for(int i=0;i<len;++i)
{
int v=d.edge[u][i];
dfs_ans(v);
ans[u]+=ans[v];
}
}
int du[N];
int main()
{
n=read();
for(int i=1;i<=n;++i)
for(int k=read();k;k=read(),++du[i])
a.add(k,i),b.add(i,k);
for(int i=1;i<=n;++i) sdom[i]=bel[i]=val[i]=i;
for(int i=1;i<=n;++i) if(du[i]==0) a.add(0,i),b.add(i,0);
dfs(0);
tarjan();
for(int i=1;i<=n;++i) d.add(idom[i],i);
dfs_ans(0);
for(int i=1;i<=n;++i) printf("%d\n",ans[i]-1);
}
这个算法的时间复杂度是O(()())或者O(()),空间复杂度是O(n)。
图片以及主要思路来源于tarjan的论文
(提取码:wnvy )
相关推荐
评论
共 29 条评论,欢迎与作者交流。
正在加载评论...