专栏文章
【抽象】2025 CSP 前的sm模拟赛 第四篇
题解参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @minhyhm2
- 此快照首次捕获于
- 2025/12/02 02:42 3 个月前
- 此快照最后确认于
- 2025/12/02 02:42 3 个月前
R28 T4
题意
给定 ,有 次询问,每次询问给定一个 ,则有 ,求长度为 的序列 ,在当前这个 下,删去若干个数(可以不删或删全部),最后获得本质不同的序列有多少。
。
思路
首先想一个dp。
设 表示考虑到第 个数时的方案数,那么考虑往后加一个数 。贪心地想,这个数 一定是距离当前这个位置后面最近的,这个时候组成的序列才不会重复。
考虑 种数的放置,那么 可以贡献给 。转化一下,变为考虑 可以接受谁的贡献,于是我们有dp转移式 。前缀和优化后可做到 一次回答。于是我们获得了60pts。
设 ,那么根据转移性质,我们有 。我们要求的答案是 。
我们考虑另一种方式对 的表示:假设我们要从 恰好走到 ,有一个初始值 。假设我们现在位于 我们有以下两种移动方式:
- 令 ,此时 。
- 令 ,此时 。
所有不同移动方式到达 的 的总和就是 。
那么 的值只会被移动方式影响。我们发现第二种移动很容易被限制,于是考虑枚举第二种方式移动的步数,有
其中第一种移动有 次。
然后我们就可以预处理出所有 的答案了。时间复杂度 。
代码
CPP#include<bits/stdc++.h>
#define ll long long
using namespace std;
template<typename T> inline void read(T &x){
T w=1;
x=0;
char c=getchar();
while(!isdigit(c)){
if(c=='-') w=-1;
c=getchar();
}
while(isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
x*=w;
}
template<typename T> inline void write(T x){
if(x<0) putchar('-'),x=(~x)+1;
if(x>9) write(x/10);
putchar(x%10^48);
}
const ll N=1e6+10,mod=1e9+7;
ll f[N],n,m,q;
ll _2[N],fac[N],inv[N];
ll C(ll x,ll y){
if(x<y||x<0||y<0) return 0;
return fac[x]*inv[y]%mod*inv[x-y]%mod;
}
ll ans[N];
void init(){
inv[0]=fac[0]=inv[1]=fac[1]=1;
_2[0]=1;
for(int i=1;i<=n;i++) _2[i]=_2[i-1]*2ll%mod;
for(int i=2;i<=n;i++) fac[i]=fac[i-1]*i*1ll%mod,inv[i]=(mod-mod/i)*inv[mod%i]%mod;
for(int i=2;i<=n;i++) inv[i]=inv[i]*inv[i-1]%mod;
for(int i=1;i<=n;i++){
for(int j=0;j<=n/(i+1);j++){
ans[i]=((ans[i]+((j&1) ? -1 : 1)*_2[n-(i+1)*j]*C(n-i*j,j)%mod+mod)%mod+mod)%mod;
}
}
// cout<<C(5,3)<<"\n";
}
int main(){
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
read(n),read(q);
init();
while(q--){
read(m);
write(ans[m]);
putchar('\n');
}
return 0;
}
/*
10 6
1 1 4 5 1 4
*/
R28 T3
喵喵思维题!
题意
给定一个DAG,不一定连通,每条边的长度都为 。求删掉一个点后最长路径的最短长度。
。
思路
首先设 表示以点 为终点 起点的最长路径。分别在原图和反图上跑一遍拓扑求出。
那么经过边 的最长路为 。
假设我们删去了一个拓扑序为 的点,那么设拓扑序 的点集为 , 的为 ,那么显然最长路只有这三种可能:。
于是我们考虑在删掉拓扑序为 的节点时的影响。
设这个点为 ,那么这个时候 一定在 中,如果将其删去,那么可能会影响的路径为 和 内的,即 以及 。将这些路径删去后,剩下路径中的最大值就是删去点 时的答案。
每次统计答案后, 应从 转移到 集,可能会影响 和另一些 的路径。具体地,即我们需要加入 和 。
初始时所有点理应在 中,因此加入 。
可以用 multiset 维护。
这样我们对于每个点和每条边会遍历两次,复杂度是 的。
需要卡卡常。反正要卡。
代码
CPP#include<bits/stdc++.h>
#define ll long long
#define min(a,b) (a<b?a:b)
using namespace std;
template<typename T> inline void read(T &x){
T w=1;
x=0;
char c=getchar();
while(!isdigit(c)){
if(c=='-') w=-1;
c=getchar();
}
while(isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
x*=w;
}
template<typename T> inline void write(T x){
if(x<0) putchar('-'),x=(~x)+1;
if(x>9) write(x/10);
putchar(x%10^48);
}
const int N=5e5+10,inf=1e9;
multiset<int>s;
int n,m;
struct edge{
int v,next;
}e[2][N<<1];
int head[2][N],id[2];
void add(int u,int v,int p){
e[p][++id[p]]=(edge){v,head[p][u]},head[p][u]=id[p];
}
int dis[2][N],in[N];//终点最长,起点最长
int dfn[N],ip,pt[N];
void tops(int type){
for(int i=1;i<=n;++i) in[i]=0,dis[type][i]=-inf;
for(int i=1;i<=n;++i){
for(int j=head[type][i];j;j=e[type][j].next){
in[e[type][j].v]++;
}
}
queue<int>q;
for(int i=1;i<=n;++i) if(!in[i]) q.push(i),dis[type][i]=0;
while(!q.empty()){
int u=q.front();
q.pop();
// cout<<u<<"\n";
if(type==0) dfn[u]=++ip;
for(int i=head[type][u];i;i=e[type][i].next){
int v=e[type][i].v;
dis[type][v]=max(dis[type][v],dis[type][u]+1);
in[v]--;
if(!in[v]) q.push(v);
}
}
}
int main(){
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
read(n),read(m);
for(int i=1;i<=m;++i){
int x,y;
read(x),read(y);
add(x,y,0),add(y,x,1);
}
tops(0),tops(1);
for(int i=1;i<=n;++i) s.insert(dis[1][i]),pt[dfn[i]]=i;
int ans=(*s.rbegin()),pos=0;
for(int i=1;i<=n;++i){
s.erase(s.find(dis[1][pt[i]]));
for(int j=head[1][pt[i]];j;j=e[1][j].next){
int v=e[1][j].v;
s.erase(s.find(dis[1][pt[i]]+dis[0][v]+1));
}
if(ans>(*s.rbegin())||ans==(*s.rbegin())&&pos>pt[i]) ans=(*s.rbegin()),pos=pt[i];
// ans=min(ans,(*s.rbegin()));
s.insert(dis[0][pt[i]]);
for(int j=head[0][pt[i]];j;j=e[0][j].next){
int v=e[0][j].v;
s.insert(dis[0][pt[i]]+dis[1][v]+1);
}
}
write(pos),putchar(' '),write(min(*s.rbegin(),ans));
// for(int i=1;i<=n;++i){
// cout<<dis[0][i]<<" "<<dis[1][i]<<"\n";
// }
return 0;
}
好题啊。
R29 T2
很好地贪心,使我虚空调试2h。
题意
给定 ,并给定 个整数 ,其中 它们的含义如下:
我们一共有 个站,有三种列车:
- 普通列车:速度最慢,从第 个站到第 个站需要 个单位时间,且每个站都可以停站。
- 高速列车:速度最快,从第 个站到第 个站需要 个单位时间,且只有 可以停站。
- 准高速列车:速度中等,从第 个站到第 个站需要 个单位时间,并且需要我们自己选择恰好 个新建站点让其可以停站,并且这 个站点中必须完全包含 个高速站点。
只有在停站时才可以选择换乘列车类型。
求在合理安排这 个准高速车站后,最多有多少个站点可以在 个单位时间内到达并停站。
。
严格递增。
思路
显然,我们最多多放 个准高速站点。
首先对于一个车站的最优到达方案一定是首先从开始搭乘高速列车一直到距离它最近的高速站点,再跑一段我们(可能会)安排的准高速列车,最后走一段普通列车到达。
因此,所有两个高速站点之间的站点段是互不影响的,影响它们的只有是否在段内放置准高速站点。
考虑准高速站点放置的最优方式。显然,若一段内最早超时的位置为 ,则在 上放置是最好的。
-
证明:假设放在 更优,当且仅当放在 时可以使后面的更多车站不超时。当放在 会令 不超时,若放在 ,会让 依旧超时,同时我们只能让后面的所有车站再多快 。但我们想再让比原来多一个车站进来,那么至少要再多快一个 ,因此放在 至多等效,不会更优。当放在 依旧不能使 不超时,不管放在后面什么位置都不会再让后面的车站不超时,也可以理解为等效。综上,放在位置 最优。
既然有了这样一个贪心,我们只需要将所有有超时位置的段记录下它们的超时位置,以及在这个超时位置放置准高速车站会使多少个新车站不超时,用优先队列维护,每次取能够使新车站变得不超时的数量最多的(即答案增量最多),然后更新放在对应超时位置后的下一个最早超时位置,以及答案增量,判断是否还会对答案有贡献或者是否还能这一段内放置准高速车站,可以的话就重新扔进优先队列,放置 次准高速车站即可。
这个维护方法是对的,这是因为答案增量一定随着超时位置越后会越来越少,那么若有多个相同的最大增量,我们一定是先选了它们再选它们更新的下一次答案增量,因此这样维护是最优的。
时间复杂度 。
细节很多,要细调。
具体求超时位置可以用剩余时间除以 ,增量类似。
代码
CPP//#pragma GCC optimize(1,2,3,"Ofast","inline")
#include<bits/stdc++.h>
#define ll long long
using namespace std;
template<typename T> inline void read(T &x){
x=0;
T w=1;
char c=getchar();
while(!isdigit(c)){
if(c=='-') w=-1;
c=getchar();
}
while(isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
x*=w;
}
template<typename T> inline void write(T x){
if(x<0) putchar('-'),x=(~x)+1;
if(x>9) write(x/10);
putchar(x%10^48);
}
const ll N=3e3+10;
ll n,m,k,a,b,c,T;
ll s[N];
ll A,B,C;
struct h{
ll dis,lst,pos,up;//答案增量,最近高速站,应该可能放准高速位置的当前,上限
bool friend operator < (h a,h b){
return a.dis<b.dis;
}
};
priority_queue<h>q;
int main(){
// freopen("express.in","r",stdin);
// freopen("express.out","w",stdout);
read(n),read(m),read(k),read(A),read(B),read(C),read(T);
for(int i=1;i<=m;i++) read(s[i]);
ll ans=0;
k-=m;
for(int i=1;i<m;i++){
if((s[i]-1)*B>T) break;
if(s[i]!=1) ans++;
ll ti=(s[i]-1)*B+(s[i+1]-1-s[i])*A,sum=s[i+1]-1-s[i];
if(ti<=T) ans+=sum;
else{
ll st=T-(s[i]-1)*B;
ll ps=st/A+1;
ans+=ps-1;
ll z=min((st-ps*C)/A+1,(s[i+1]-1-s[i])-ps+1);
if(z>0&&st-ps*C>=0) q.push({z,i,s[i]+ps,s[i+1]});
// cout<<i<<" "<<ss<<" "<<s[i]+1<<" "<<s[i]+ps<<" "<<s[i+1]<<"\n";
}
}
if((n-1)*B<=T) ans++;
// cout<<ans<<"\n";
while(k>0&&q.size()){
h u=q.top();
q.pop();
k--;
// cout<<u.dis<<" "<<u.npos<<" "<<u.pos<<" "<<u.up<<"\n";
// cout<<u.dis<<"\n";
ans+=u.dis;
u.pos=u.pos+u.dis;
ll st=T-(s[u.lst]-1)*B;
ll z=min((st-(u.pos-s[u.lst])*C)/A+1,(s[u.lst+1]-1)-u.pos+1);
u.dis=z;
if(u.pos<u.up&&u.dis>0&&(st-(u.pos-s[u.lst])*C)>=0) q.push(u);
// cout<<u.dis<<"\n";
}
write(ans);
return 0;
}
/*
准高速列车会多停K-M个点
想要到某一个点,那么一定是先搭乘高速到达距离这个点最近的高速点,再考虑怎么去放准高速点
然后发现一个很神奇的东西:若这个点不是高速点,那么它到达的最快时间和前一个高速点之前的所有点都没有关系,包括放了准高速列车的点
因此直接考虑两段中间点
考虑超时段。
超时段直接放即可,否则放后面不一定弄到,不优
并且准高速放得越前越好
每个点都会减去一定时间
每段的超时段是可以算的
如果碰到全超时段即全跑B都会超时
直接退出即可
可以贪心?
怎么最优化选取
用二分可以知道有几个站可以跑
同时,我每使用一个准高速至多能使一个新车站被获得
要是超了恰好A,那么改为放C是不一定优的
用优先队列
10 3 5
10 3 5
25
1 6 10
0 5 27
怎么建准高速??
它可以优化连续一段前缀的时间
换种思路
由i->i+1,实际上我最多只能再多一个。那么不如建在不合法的i上,使其合法
如果i放了也不合法
*/
R29 T3
啥阴 2-SAT 题。
图论就是构式。
题意
给定一棵 个点的无向树。现在要求给边定向,给定 个限制 ,要求定向后对于所有 至少要存在一条 或 的简单路径。
求给边定向的方案数。
。
思路
因为一个限制是可以给一条链上或两条链上的边限制定向方案的,并且每个限制的路径上若有一条边定向了,则其他边都可以定向。并且每条边状态只有上或下两种,于是我们考虑2-SAT。
具体地,我们把每条边当作一个点,再拆成两个点,为了方便,我们定义 表示编号为 的边向下 向上代表的点。
-
情况 :如果对于一个限制的 再同一条链上,那么这条链上的所有边只能同向,于是将这条链上的所有边两两的 相连, 相连。
-
情况 :如果 不在同一条链上,那么设其 lca 为 ,则链 和 和上述连边方式一样,然后对于任意边 在 上与任意边 在 上,我们连边 和 ,表示这两条链上的边只能异向。
记有向图缩点后连通块个数为 ,则答案为 。除以 是因为上向边和下向边都算了一遍。
但是这样连边的复杂度太高了,考虑优化建图。
发现我们每次连的实际上是双向边,因此只要一连边,两条边就属于同一个连通块了,于是考虑并查集。
最后求连通块个数然后求答案就行了。
判无解也很简单,只要看看是否存在边 有 在同一个连通块内即可。
不算并查集的常数复杂度后是 的, 是求 lca 带来的。
代码
CPP//#pragma GCC optimize(1,2,3,"Ofast","inline")
#include<bits/stdc++.h>
#define ll long long
using namespace std;
template<typename T> inline void read(T &x){
x=0;
T w=1;
char c=getchar();
while(!isdigit(c)){
if(c=='-') w=-1;
c=getchar();
}
while(isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
x*=w;
}
template<typename T> inline void write(T x){
if(x<0) putchar('-'),x=(~x)+1;
if(x>9) write(x/10);
putchar(x%10^48);
}
const ll N=6e5+10,mod=1e9+7;
struct edge{
ll v,next;
}e[N<<1];
ll head[N],id;
void add(ll u,ll v){
e[++id]=(edge){v,head[u]},head[u]=id;
}
vector<ll>v[N<<1];
ll n,m;
struct ques{
ll x,y;
}q[N];
ll fe[N],ip;
void dfs(ll u,ll fa,ll num){
fe[u]=++ip;
if(~num) v[num].emplace_back(fe[u]),v[fe[u]].emplace_back(num),v[num+n].emplace_back(fe[u]+n),v[fe[u]+n].emplace_back(num+n);
for(int i=head[u];i;i=e[i].next){
ll v=e[i].v;
if(v==fa) continue;
dfs(v,u,fe[u]);
}
}
ll dep[N<<1],f[N<<1][22],ff[N<<1];//边点深度,LCA,向下/向上 并查集
void dfs2(ll u,ll fa){
dep[u]=dep[fa]+1;
f[u][0]=fa;
for(int i=1;i<=20;i++) f[u][i]=f[f[u][i-1]][i-1];
ff[u]=u;
for(auto vt : v[u]){
if(vt==fa) continue;
dfs2(vt,u);
}
}
ll Min(ll x,ll y){
return dep[x]<dep[y] ? x : y;
}
void dfs3(ll u,ll fa){
for(auto vt : v[u]){
if(vt==fa) continue;
dfs3(vt,u);
ff[u]=Min(ff[u],ff[vt]);
}
}
ll lca(ll x,ll y){
if(dep[x]<dep[y]) swap(x,y);
for(int i=20;i>=0;i--) if(dep[f[x][i]]>=dep[y]) x=f[x][i];
if(x==y) return x;
for(int i=20;i>=0;i--) if(f[x][i]!=f[y][i]) x=f[x][i],y=f[y][i];
return f[x][0];
}
ll fin(ll x,ll gd){
for(int i=20;i>=0;i--) if(dep[f[x][i]]>=gd) x=f[x][i];
return x;
}
ll fif(ll x){
return ff[x]==x ? x : ff[x]=fif(ff[x]);
}
void uni(ll x,ll y){
ll xx=0,yy=0;
xx=fif(x),yy=fif(y);
if(xx!=yy) ff[xx]=yy;
}
ll ksm(ll x,ll y){
ll res=1;
while(y){
if(y&1) res=res*x%mod;
x=x*x%mod,y>>=1;
}
return res;
}
int main(){
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
read(n),read(m);
for(int i=1;i<n;i++){
ll x,y;
read(x),read(y);
add(x,y),add(y,x);
}
dfs(1,0,-1);
dfs2(1,0);
dfs2(n+1,0);
for(int i=1;i<=(n<<1);i++) ff[i]=i;
ll cnt=0;
for(int i=1;i<=m;i++){
ll x,y;
read(x),read(y);
x=fe[x],y=fe[y];
if(dep[x]<dep[y]) swap(x,y);
ll l=lca(x,y);
if(l==y){
y=fin(x,dep[l]+1);
ff[x]=Min(ff[x],y),ff[x+n]=Min(ff[x+n],y+n);
}
else{
ll xx=fin(x,dep[l]+1),yy=fin(y,dep[l]+1);
ff[x]=Min(ff[x],xx),ff[x+n]=Min(ff[x+n],xx+n),ff[y]=Min(ff[y],yy),ff[y+n]=Min(ff[y+n],yy+n);
q[++cnt]={x,y};
}
}
dfs3(1,0);
dfs3(n+1,0);
// cout<<'\n';
for(int i=1;i<=cnt;i++){
uni(q[i].x,q[i].y+n),uni(q[i].x+n,q[i].y);
// cout<<q[i].x<<" "<<q[i].y<<"\n";
}
ll sum=0;
bool fl=0;
for(int i=1;i<=n;i++) fl|=(fif(i)==fif(i+n));
if(fl){
write(0);
return 0;
}
for(int i=1;i<=(n<<1);i++){
if(i!=1&&i!=(n+1)&&fif(i)==i) sum++;
}
write(ksm(2,(sum>>1)));
return 0;
}
/*
处于同一连通块方向只能相同
跨链异向
同链同向
考虑染色+并查集
然后就可以通过 size 搞定
不同链时考虑以dfn序更小的弄
以dfn序更小的位置为祖先
同链点可以缓着连,但是跨链点直接连
*/
R30 T3
题意
现在有 个州,每个州有两个阈值 。若在这个州的总演讲时间达到 ,则可以获得该州一张选票,若达到 ,则可以获得一位该州的协作者,他可以在该州以外发表演讲。若一个州没有协作者,则 ,否则满足 。可以有多个人同时在一个州发表演讲,若有 个人在一个州演讲,则每个单位时间该州的总演讲时间增加 。
初始时有一个人发表演讲。现在给定 ,求获得 张选票所需要的最短时间。
。
思路
由于我们有不等式
因此不存在将协作者分去别的州演讲的情况,只有可能所有人一起在一个州完成演讲目标后再去别的州。
假设我们钦定了最后一定要有 名新加入的协作者,那么显然我们肯定是先考虑在我们选中的 个州中获得所有协作者,同时这些州的选票也会被获得。再在剩下的 个州中选取 个 最小的州去获取选票。贪心地想,既然要先取 ,那么选的时候一定是按 升序选协作者的,因此我们将州按 升序排序后,可以进行dp。
设 表示前 个州选了 个州获取选票并且这 个州中选取了 个州获取协作者的最短时间。枚举最后会多选取 个协作者,那么考虑一个州不选、只选选票、选选票和协作者三种情况进行转移,我们有
f_{i,j,k}=\min(f_{i-1,j,k},f_{i-1,j-1,k}+\frac{A_i}{t+1},f_{i-1,j-1,k-1}+\frac{B_i}{(k-1)+1})
\end{aligned}$$
最后的答案就是所有 $t$ 的情况的 $f_{i,K,t}$ 取 $\min$。
可以使用滚动数组优化空间。
这样,一次dp是 $\Omicron(n^3)$ 的,加上枚举 $t$,我们的复杂度会达到 $\Omicron(n^4)$。考虑优化。
我们发现一个贪心:对于两个相邻的选取了协作者的州之间,在最优方案下一定是所有州都是选了选票的。若没有,那么我们可以把后面的协作者州移到这个州上,这样在选取协作者数量相等的情况下,我们使获取这个协作者的时间更少了,因此会更优。这个贪心包括第一个协作者州。
于是我们就可以用这个贪心优化dp了。设 $f_{i,j}$ 表示前 $i$ 个州选了 $j$ 个协作者,转移时只考虑当前州选择选票或是选协作者,转移类似上面。
那么对于一个 $t$,它的答案为 $\forall i\in[K,n],f_{i,t}$ 与所有在 $[t,K-1]$ 范围内的 $i$ 的 $f_{i,t}$ 加上剩下的 $n-i$ 个州中 $A$ 前 $K-i$ 小的州的 $A$ 的增加时间。所有 $t$ 的答案取 $\min$ 即可。
时间复杂度 $\Omicron(n^3)$。
## 代码
```cpp
#pragma GCC optimize(1,2,3,"Ofast","inline")
#include<bits/stdc++.h>
#define ll long long
using namespace std;
template<typename T> inline void read(T &x){
x=0;
T w=1;
char c=getchar();
while(!isdigit(c)){
if(c=='-') w=-1;
c=getchar();
}
while(isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
x*=w;
}
template<typename T> inline void write(T x){
if(x<0) putchar('-'),x=(~x)+1;
if(x>9) write(x/10);
putchar(x%10^48);
}
const ll N=5e2+10;
const double inf=1e15;
struct h{
ll a,b;
}p[N];
bool cmp(h x,h y){
return (x.b!=-1&&y.b!=-1) ? x.b<y.b : x.b>y.b;
}
ll n,K;
double f[N][N];//前i个选了j个选票并且k协作(j>=k)
ll na[N];
double calc(ll sum){
for(int i=1;i<=n;i++) na[i]=p[i].a;
for(int i=0;i<=n;i++){
for(int j=0;j<=sum;j++){
f[i][j]=inf;
}
}
f[0][0]=0;
for(int i=1;i<=n;i++){
for(int j=0;j<=min(sum,i*1ll);j++){
f[i][j]=min(f[i][j],f[i-1][j]+(double)p[i].a/((double)sum+1.0));
if(j&&(~p[i].b)) f[i][j]=min(f[i][j],f[i-1][j-1]+(double)p[i].b/((double)j));
}
}
double res=inf;
for(int i=K;i<=n;i++) res=min(res,f[i][sum]);
for(int i=K-1;i>=sum;i--){
stable_sort(na+i+1,na+n+1);
double s=0;
for(int j=1;j<=K-i;j++) s+=(double)na[i+j]/((double)sum+1.0);
res=min(res,s+f[i][sum]);
}
return res;
}
int main(){
freopen("election.in","r",stdin);
freopen("election.out","w",stdout);
read(n),read(K);
for(int i=1;i<=n;i++) read(p[i].a),read(p[i].b);
sort(p+1,p+n+1,cmp);
double ans=inf;
for(int i=0;i<=K;i++){
double t=calc(i);
// printf("%.8lf\n",t);
ans=min(ans,t);
}
printf("%.10lf",ans);
return 0;
}
/*
没有协作者的州一定是时间越少越先拿
考虑有协作者的
我们赢得一个州的选票后考虑是否选择这个州的协作者
首先选择B更小的一定最优
考虑协作者分配
假设有x,y
x/(t-s)+(y-x/(t-s)*s)/t
=x/(t-s)-x/(t-s)*s/t+y/t
=x(1/(t-s)-1/(t-s)*(s/t))+y/t
(1/(t-s)*(1-(s/t)))->s越大越好
也就是在可行范围内,分割分配越大越好(满足 x先比y 拿完)
但换句话说,我们直接令s=t?
那么结论如下:
若已经决定不选协作者,那么对于剩下的选票州,一定是所有人一起演讲最优
考虑选协作者最优的情况
(a-b)^2>=4ab
设拿了k个,判断当前这个要作为选票州/协作州
有些可以选择不选
假设是 x 先被拿完
假设我选定了x个协作者
那么剩下k-x张选票一定是用时最小的前l-x张
假设要选协作者
当我现在拥有x张选票
*/
```
# R30 T4
[P13342 [EGOI 2025] Wind Turbines / 风力涡轮机](https://www.luogu.com.cn/problem/P13342)
很好的风力,使我脑子旋转。
## 题意
给定一个 $n$ 个点 $m$ 条边的无向连通图,每条边有边权,现在给定 $q$ 次询问,每次询问给定 $l,r$,表示当编号在 $[l,r]$ 内的点都成为“有根点”,求让所有点都直接或间接和至少一个“有根点”连通的选择边的边权。
$1\le n,m\le 10^5,1\le q\le 2\times 10^5$。
## 思路
当 $l_i=r_i$ 时,显然答案为最小生成树。
接下来往下考虑 $r_i=l_i+1$ 的情况,那么就是最小生成树的总边权减去 $l_i$ 到 $r_i$ 在最小生成树路径上的最大边,这个显然可以用kruskal最小重构树做,相当于查询 $l_i$ 与 $r_i$ 在 重构树上的 lca 点权。
扩展到普遍情况,那么相当于查询区间 $[l_i,r_i]$ 内的点在重构树上两两的 lca 的并集的点权和。由于重构树上的每一个点都代表一次合并,那么区间内 $k=r_i-l_i+1$ 就恰好有 $k-1$ 个不同的 lca,于是问题转换为求这 $k-1$ 个 lca 的点权和。
考虑一个重构树上的节点什么时候会贡献。因为重构树每个非叶子节点都有两个儿子,因此若存在 $x,y(x<y)$ 分别存在于它的两个儿子的子树中,则这个点可以贡献给包含 $[x,y]$ 区间的 $[l,r]$ 贡献。同时由于每个这样的节点只能贡献一次,因此在固定了一边的 $x$ 时,对于这个节点我们选取最小的 $y$ 总是最优的。
于是我们考虑预处理出所有可能贡献的点对 $(x,y,w_u)$。我们可以维护左右儿子子树内叶子内编号的集合,对于一个集合内的点 $x$,在另一个集合内找其第一个比它大的点与最大的比它小的点构造贡献点对(前驱后继),然后每次计算完贡献点对后启发式合并。
具体地,我们可以用set去维护,计算贡献、合并时比较两个set的大小即可。
转变为在二维平面上的点,$l$ 为横轴,$r$ 为纵轴,每个询问、贡献点对都转变为一个点,那么 $(x,y)$ 可以贡献给在它左上角的所有询问点。这显然可以使用扫描线与树状数组处理,但要将 $l$ 从 $n$ 往 $1$ 扫,同时要先加贡献点再查询询问点。具体看代码。
同时我们要注意,由于一个点不可以重复贡献给一个询问,因此对于每个 $w_u$ 需要记录一个最小的 $r$,即在二维平面上最低的纵轴坐标。具体原因如下:
如图,现在我们有两个相同贡献了 $w_u$ 的点。
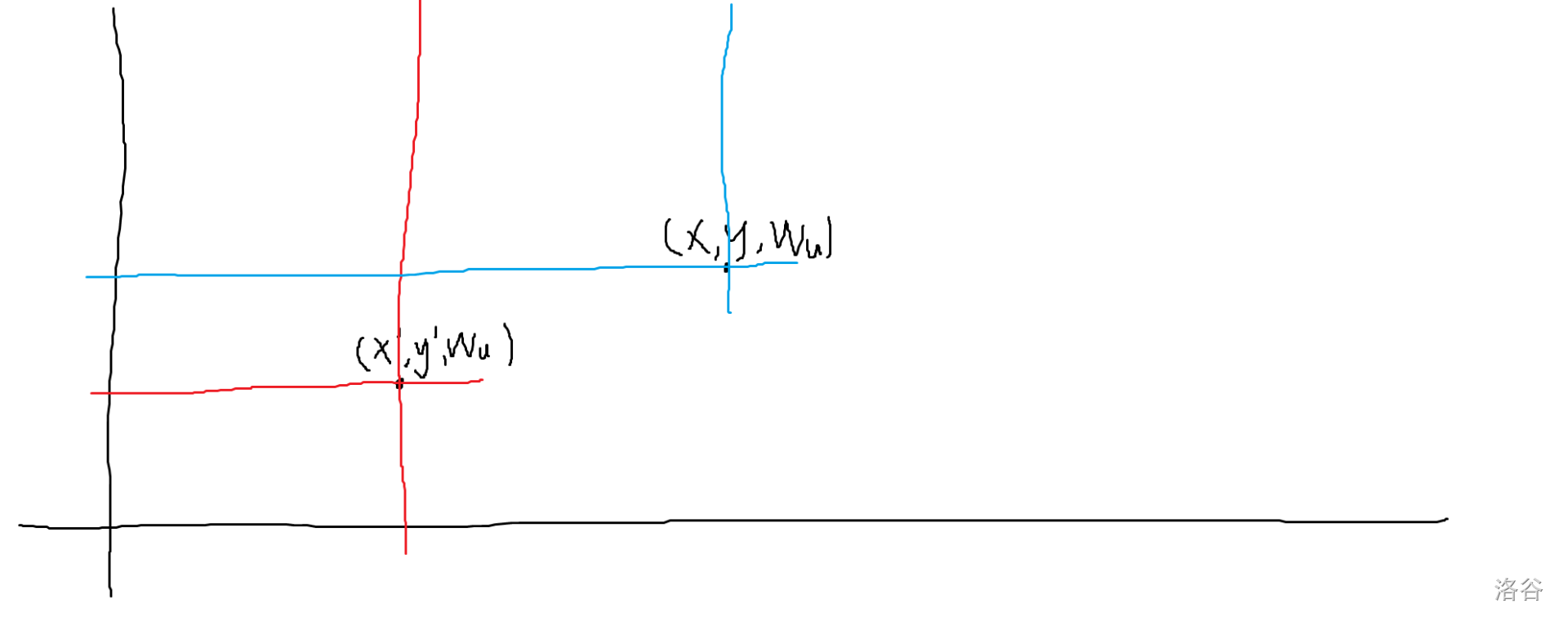
他们分别可以贡献给蓝色矩形与红色矩形,但实际上我们只能取并,因此它的实际贡献为绿色边围起来的部分。
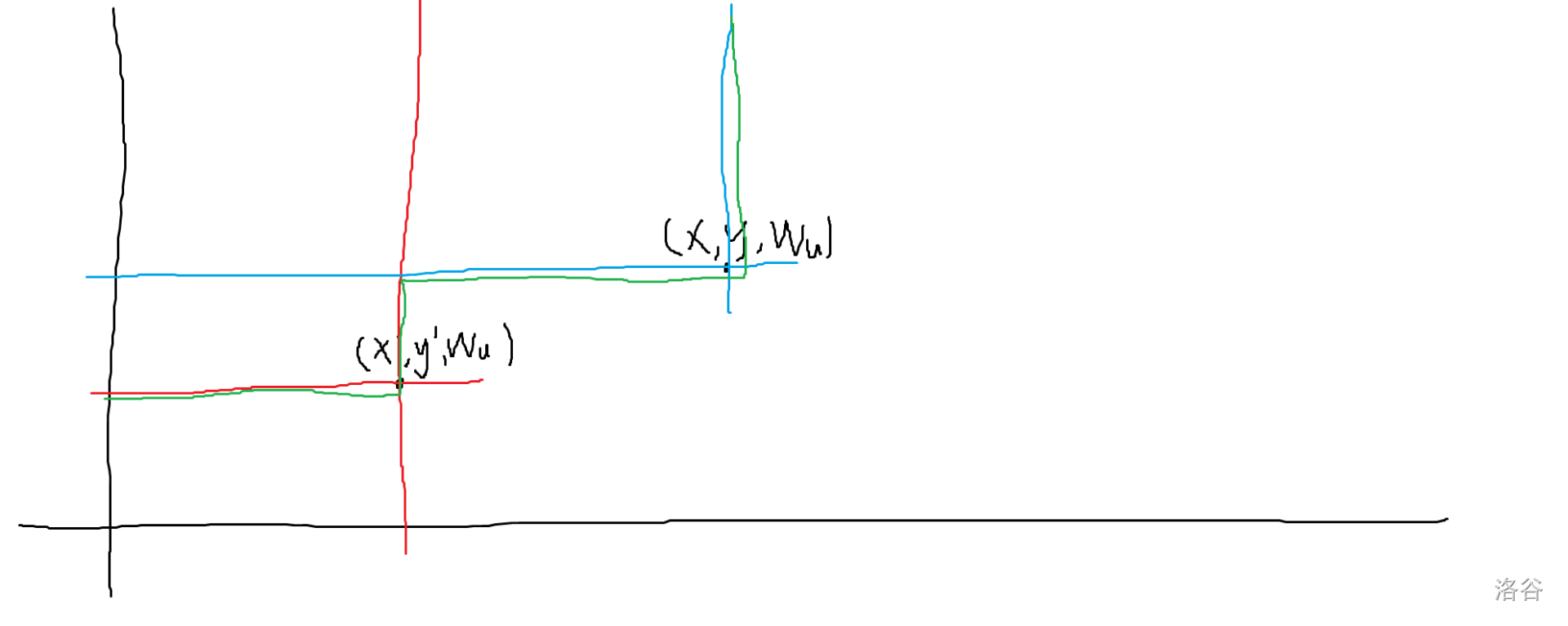
因为我们是将横轴从大往小扫,于是我们要转换成这两个橙色的矩形去贡献。
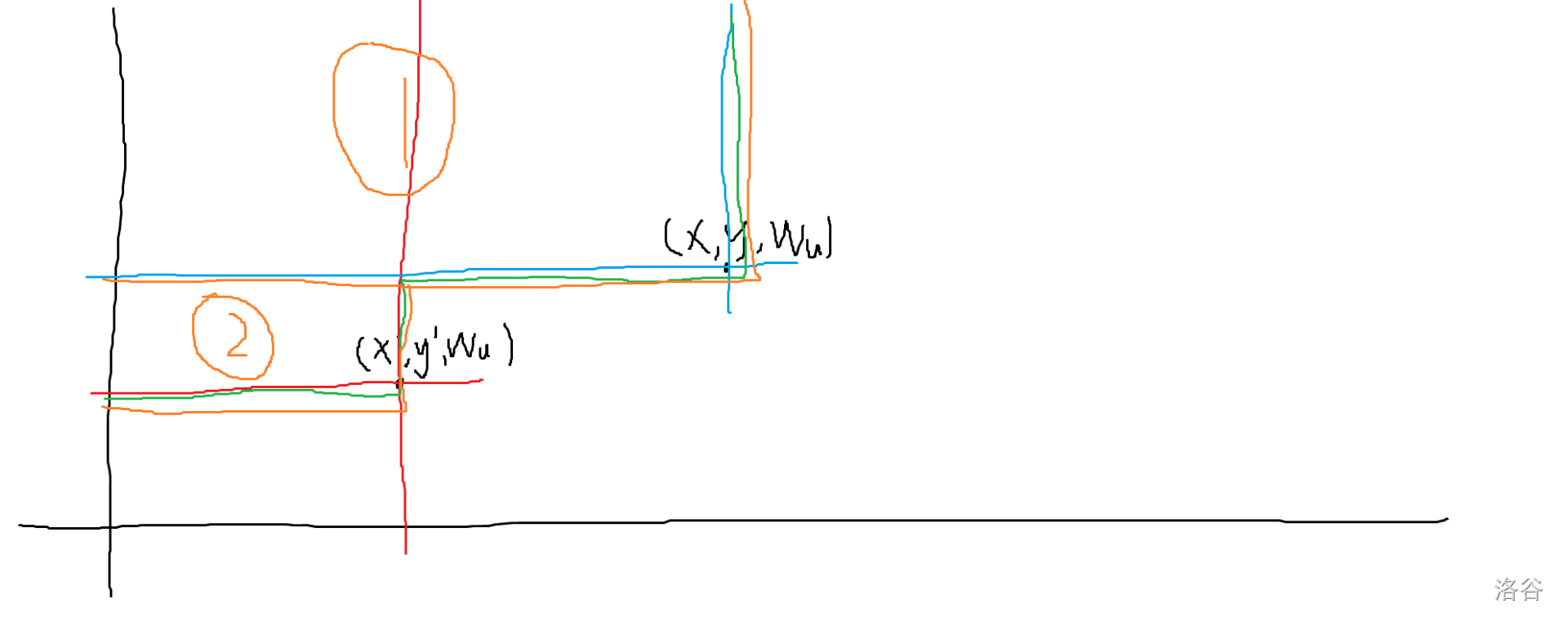
所以要记录每个相同 $w_u$ 的最小 $r$。
复杂度 $\Omicron(n\log^2n)$,视 $n,m,q$ 同阶。瓶颈还是在于启发式合并。
## 代码
```cpp
#include<bits/stdc++.h>
#define ll long long
#define rt ((n<<1)-1)
#define s(a) son[u][a]
#define si set<ll>::iterator
using namespace std;
template<typename T> inline void read(T &x){
x=0;
T w=1;
char c=getchar();
while(!isdigit(c)){
if(c=='-') w=-1;
c=getchar();
}
while(isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
x*=w;
}
template<typename T> inline void write(T x){
if(x<0) putchar('-'),x=(~x)+1;
if(x>9) write(x/10);
putchar(x%10^48);
}
const ll N=4e5+10;
ll n,m,q;
struct ed{
ll u,v,w;
}p[N];
bool cmp(ed a,ed b){
return a.w<b.w;
}
ll pt[N],f[N],son[N][2];
ll head[N],id,sum,siz[N];
ll fin(ll x){
return f[x]==x ? x : f[x]=fin(f[x]);
}
void rebuild(){
sort(p+1,p+m+1,cmp);
ll cnt=n;
for(int i=1;i<=(n<<1);i++) f[i]=i;
for(int i=1;i<=m;i++){
ll xx=fin(p[i].u),yy=fin(p[i].v);
if(xx!=yy){
cnt++;
son[cnt][0]=xx,son[cnt][1]=yy;
f[xx]=f[yy]=cnt;
pt[cnt]=p[i].w;
sum+=p[i].w;
}
}
}
set<ll>s[N];
ll t[N];
struct ran{
ll y,w_id;
};
vector<ran>v[N];
struct query{
ll r,id;
};
vector<query>que[N];
void dfs(ll u){
siz[u]=1;
if(u<=n) s[u].insert(u),t[u]=u;
else{
for(int i=0;i<=1;i++) dfs(s(i)),siz[u]+=siz[s(i)];
ll tag=0;
if(siz[s(0)]>siz[s(1)]) tag=1,t[u]=t[s(0)];
else tag=0,t[u]=t[s(1)];
for(si it=s[t[s(tag)]].begin();it!=s[t[s(tag)]].end();it++){
si it1=s[t[s(tag^1)]].upper_bound(*it);
if(it1!=s[t[s(tag^1)]].end()) v[*it].push_back({*it1,u});
if(it1!=s[t[s(tag^1)]].begin()){
it1--;
v[*it1].push_back({*it,u});
}
}
for(si it=s[t[s(tag)]].begin();it!=s[t[s(tag)]].end();it++) s[t[s(tag^1)]].insert(*it);
}
}
ll tr[N],mi[N],ans[N];
void add(ll i,ll z){
for(;i<=n;i+=i&-i) tr[i]+=z;
}
ll num(ll i){
ll res=0;
for(;i;i-=i&-i) res+=tr[i];
return res;
}
int main(){
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
read(n),read(m),read(q);
for(int i=1;i<=m;i++){
read(p[i].u),read(p[i].v),read(p[i].w);
p[i].u++,p[i].v++;
}
rebuild();
dfs(rt);
for(int i=1;i<=q;i++){
ll l,r;
read(l),read(r);
l++,r++;
que[l].push_back({r,i});
}
for(int i=1;i<=(n<<1);i++) mi[i]=n+1;
for(int i=n;i>=1;i--){
for(auto p : v[i]){
if(p.y>=mi[p.w_id]) continue;
add(p.y,pt[p.w_id]);
add(mi[p.w_id],-pt[p.w_id]);
mi[p.w_id]=min(mi[p.w_id],p.y);
}
for(auto p : que[i]) ans[p.id]=sum-num(p.r);
}
for(int i=1;i<=q;i++) write(ans[i]),putchar('\n');
return 0;
}
```
# R31 T2
[CF2025E Card Game](https://www.luogu.com.cn/problem/CF2025E)
不错的计数题。
## 题意
给定 $n,m$,每一个 $i\in[1,n],j\in[1,m]$ 都代表了一种牌 $(i,j)$。牌 $(x,y)$ 能打败牌 $(a,b)$ 需要满足以下两种条件之一:
- $x=1,a\ne 1$。
- $x=a,y>b$。
现在求将牌平均分为两堆 $A,B$ 后,$A$ 中的牌与 $B$ 中的牌恰好能两两匹配使得 $A$ 的牌全部都能打败与其配对的牌的平局分方案数。
保证 $m$ 为偶数。
$1\le n,m\le 500$。
## 思路
称牌 $(x,y)$ 为 $x$ 色 $y$ 点的牌。
首先我们不难发现一个性质:平均分后 $A$ 拥有的形如 $(1,x)$ 的牌一定比 $B$ 多,同时这也代表着 $B$ 拥有的非 $(1,x)$ 牌比 $A$ 多。
然后我们~~不难~~发现,若牌 $(x,y)$ 在 $x$ 不同的情况下,方案数是不会互相影响的。
于是我是可以设置一个dp:$f_{i,j}$ 表示除去 $1$ 色牌外的前 $i$ 种色 $B$ 一共比 $A$ 多 $j$ 张牌的方案数,记 $g_{i,j}$ 表示在同一种色双方分别有 $i,j(i<j)$ 张牌的能够使另一方的 $j$ 张牌都被这种颜色打败的合法分配方案数,那么有转移
f_{i,j}=\sum_{k=0}^{j} f_{i-1,k}\times g_{(m-(j-k))/2,(m-(j-k))/2+(j-k)}
注意 $k$ 每次增量为 $2$。
最终答案为
\sum_{i=0}^{m}f_{n,i}\times g_{(m-i)/2,(m-i)/2+i}
就是乘上分配 $1$ 的合法方案数。同样的,$i$ 增量为 $2$。
接下来考虑求 $g$。若视从大到小,分配给最终多牌一方表示往左走,给最终少牌一方表示往上走,发现 $g_{i,j}$ 实际上可以转化为从 $0,0$ 走到第 $i$ 行 $j$ 列并且满足任意一步的 $x$ 坐标都要不小于 $y$ 坐标的方案数。那么转移是简单的,有
g_{i,j}=g_{i-1,j}+g_{i,j-1}\times [j-1\ge i]
复杂度 $\Omicron(n^3)$。
## 代码
```cpp
#pragma GCC optimize(1,2,3,"Ofast","inline")
#include<bits/stdc++.h>
#define ll long long
using namespace std;
template<typename T> inline void read(T &x){
x=0;
T w=1;
char c=getchar();
while(!isdigit(c)){
if(c=='-') w=-1;
c=getchar();
}
while(isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
x*=w;
}
template<typename T> inline void write(T x){
if(x<0) putchar('-'),x=(~x)+1;
if(x>9) write(x/10);
putchar(x%10^48);
}
const ll N=5e2+10,mod=998244353;
ll n,m;
ll f[N][N],g[N][N];
int main(){
// freopen("card.in","r",stdin);
// freopen("card.out","w",stdout);
read(n),read(m);
g[0][0]=1;
for(int i=0;i<=m;i++){//枚举行
for(int j=(i==0 ? 1 : i);j<=m;j++){//枚举列
if(j-1>=i) g[i][j]=(g[i][j]+g[i][j-1])%mod;
g[i][j]=(g[i][j]+g[i-1][j])%mod;
}
}
f[1][0]=1;
for(int i=2;i<=n;i++){
for(int j=0;j<=m;j+=2){//当前多一共的数量
for(int k=0;k<=j;k+=2){//上一个多的数量
ll t=(j-k);//当前颜色多的
f[i][j]=(f[i][j]+f[i-1][k]*g[(m-t)/2][(m-t)/2+t]%mod)%mod;
}
}
}
ll ans=0;
for(int i=0;i<=m;i+=2) ans=(ans+f[n][i]*g[(m-i)/2][(m-i)/2+i]%mod)%mod;
write(ans);
return 0;
}
/*
1.1色打败非1色
2.同色高等级打败低等级
其余情况无法打败
1色可以当作全色
能用同色打败尽量用同色打败
假设不存在1
那么分配方案数很好求
考虑给两边如何分配1
首先B的1不能超过A的1
( 分配给A
) 分配给B
4 4->5 3 多两个。
合法括号序列?
先考虑1分配
怎么用1打败那些多出来的非1
每多造一个1去A,某个色对也会多增1
会有重复方案,如何去重?
只取前缀?
f(i,j)表示前i种颜色已经分配的j个分配对。
f(i,j)=Σf(i-1,j-k)*g(k)
ans=Σf(n,j)*g(j)
g(i) 表示选取多i,剩下双方有合法括号序列时的方案数
考虑如何求g(i)
重复的原因在于它有可能会选出来的并上内部的可能一样
6 5 4 3 2 1
6 4
5 3 2 1
(())
6 5
4 3 2 1
(())
6 1
5 4 3 2
换种枚举方式
最终综合恰好等于i且没有前缀为负数的方案数
换成在网格上处理,考虑dp
则g(i,j) 表示走到点第i列第j行的合法方案数 dp预处理即可。
*/
```
# R32 T4
[P11336 [NOISG 2020 Finals] Aesthetic](https://www.luogu.com.cn/problem/P11336)
## 题意
## 思路
## 代码
```cpp
#include<bits/stdc++.h>
//#include<windows.h>
#define ll long long
#define pll pair<ll,ll>
#define fi first
#define se second
using namespace std;
template<typename T> inline void read(T &x){
x=0;
T w=1;
char c=getchar();
while(!isdigit(c)){
if(c=='-') w=-1;
c=getchar();
}
while(isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
x*=w;
}
template<typename T> inline void write(T x){
if(x<0) putchar('-'),x=(~x)+1;
if(x>9) write(x/10);
putchar(x%10^48);
}
const ll N=3e5+10,inf=1e16;
ll n,m,x[N],y[N],z[N];
vector<pll>v[N];
vector<ll>g[N];
vector<ll>pp[N];
ll dis[N][2],vis[N][2],pre[N],suc[N];
unordered_map<ll,unordered_map<ll,ll> >mp;
struct h{
ll dis,u;
bool friend operator < (h a,h b){
return a.dis>b.dis;
}
};
void dij(ll u,ll id){
priority_queue<h>q;
for(int i=1;i<=n;i++) dis[i][id]=inf;
dis[u][id]=0;
q.push({0,u});
while(q.size()){
h p=q.top();
q.pop();
if(vis[p.u][id]) continue;
vis[p.u][id]=1;
// printf("dis[%lld][%lld]=%lld\n",p.u,id,p.dis);
ll u=p.u,d=p.dis;
for(auto vt : v[u]){
ll vv=vt.fi,w=vt.se;
if(vis[vv][id]) continue;
if(dis[vv][id]>d+w){
if(!id) pre[vv]=u;
dis[vv][id]=d+w;
q.push({dis[vv][id],vv});
}
}
}
// cout<<"\n";
}
multiset<ll>s;
ll f[N],nxt[N];
bool tag[N];
void init(ll u,ll sum){
f[u]=sum;
// cout<<u<<" ";
pp[f[u]].push_back(u);
for(auto v : g[u]) init(v,sum);
}
void dfs(ll u,ll fa){
f[u]=f[fa]+1;
pp[f[u]].push_back(u);
ll nxt=0;
// cout<<u<<" ";
for(auto v : g[u]){
if(!tag[v]) init(v,f[u]);
else nxt=v;
}
// cout<<"\n";
if(nxt) dfs(nxt,u);
}
int main(){
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
read(n),read(m);
for(int i=1;i<=m;i++){
read(x[i]),read(y[i]),read(z[i]);
v[x[i]].push_back({y[i],z[i]});
v[y[i]].push_back({x[i],z[i]});
mp[x[i]][y[i]]=mp[y[i]][x[i]]=i;
}
dij(1,0),dij(n,1);
for(int i=1;i<=n;i++){
if(pre[i]) g[pre[i]].push_back(i);
}
ll pt=n;
while(pt){
tag[pt]=1;
if(pre[pt]) nxt[pre[pt]]=pt;
// cout<<pt<<"\n";
pt=pre[pt];
}
// cout<<"step1\n";
dfs(1,0);
for(int i=m;i>=1;i--) suc[i]=max(suc[i+1],z[i]);
// cout<<"step2\n";
ll pg=1,ans=dis[n][0];
while(pg!=n){
// cout<<"ktt\n";
ll d=dis[n][0]+suc[mp[pg][nxt[pg]]+1];
for(auto t : pp[f[pg]]){
for(auto pl : v[t]){
ll ph=pl.fi;
if(pre[t]==ph||pre[ph]==t||f[t]==f[ph]) continue;
// cout<<t<<" "<<ph<<"\n";
if(f[t]>f[ph]) s.erase(s.find(dis[t][1]+dis[ph][0]+z[mp[t][ph]]));
if(f[t]<f[ph]) s.insert(dis[ph][1]+dis[t][0]+z[mp[t][ph]]);
}
}
// cout<<"\n";
// cout<<s.size()<<"\n";
if(s.size()) d=min(d,*s.begin());
ans=max(ans,d);
pg=nxt[pg];
// cout<<pg<<"\n";
// Sleep(1000);
}
write(ans);
return 0;
}
/*
*/
```相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...