专栏文章
NFLSHC集训Day2
算法·理论参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @mioucrs9
- 此快照首次捕获于
- 2025/12/03 01:17 3 个月前
- 此快照最后确认于
- 2025/12/03 01:17 3 个月前
安排
额,跟昨天一样,这个就不废话了,早八讲课下午答疑,中午睡一下,唯一的不同点是我今天戴了手表
今日大纲
- 学习Trie树及应用
学习Trie树及应用
Trie树的思想和基本模型
Trie树,又称字典树,长得就跟字典似的,是一种树形的数据结构,跟字典的使用方式也差不多,常用以解决字符串匹配问题,但是正常人都会觉得,一个母串和一个文本串的匹配自然有别的方法做,Trie多难啊?但是看到这个你就沉默了,助手小李给个图例:

这个时候就不得不请出Trie了,而Trie的实现分两步构成:
第一步,建造Trie树
Trie树的建造理念比较简单,但要注意的是,根节点是空的,小李给个图例:
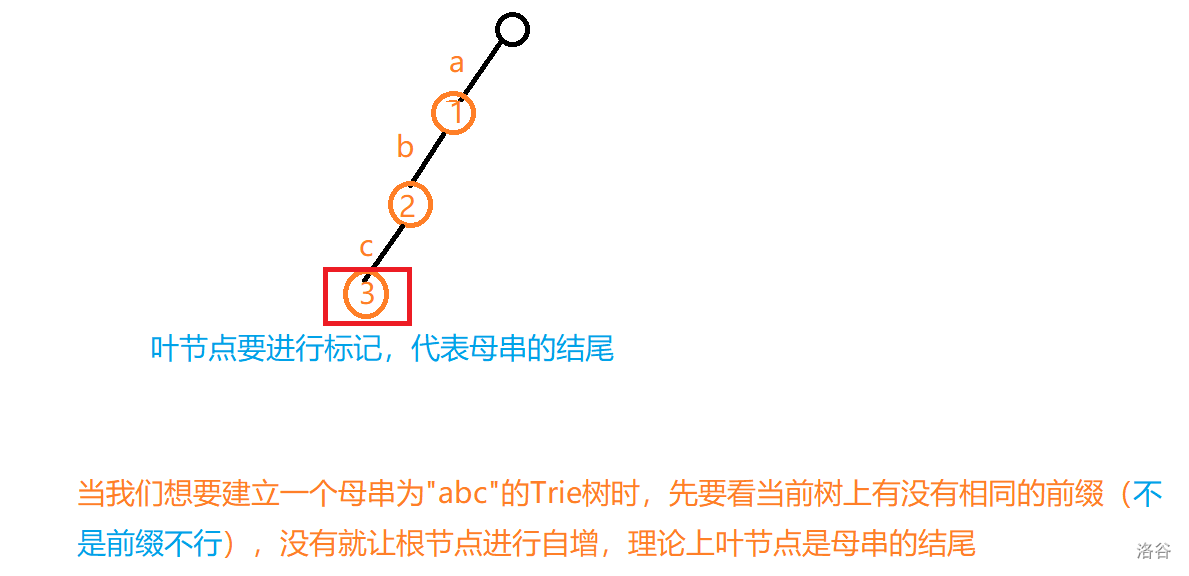
既然Trie树如此珍惜前缀,那么不难发现,Trie树的优点就是可以使用前缀来减少不必要的查找,大大提高了效率
那么一个完全遵从此理念的漂亮的Trie树长什么样呢?我自己在OI WIKI上找了图,能看:

这么好看的Trie树怎么不能写代码呢?但是应该如何插入并增加效率呢?常见有两种做法:
1.暴力拆解,比较适合线段树,但是如果这棵树已经退化成线状,那么才建6层就要用32个位置了!效率低下
2.前文讲过的,看前缀进行自增,高效
来看看如何进行正确的插入吧:
CPPint root = 0, tot = 0;
int ch[N][26];
vector<int> ans[N];
void insert(string s, int num)
{
int p = root, len = s.size();
for(int i = 0; i < len; i++)
{
int x = s[i] - 'a';
if(!ch[p][x]) ch[p][x] = ++tot;
p = ch[p][x];
}
ans[p].push_back(num);
}
第二步,遍历Trie
这个就简单多了,只要记住是从根节点往下找就行,不多赘述了
Trie树的应用
纯Trie应用,当板子题做,但唯一要注意的是有些单词可能会被插入两次及以上,所以要记得去重,看看我写的:
CPP#include<bits/stdc++.h>
using namespace std;
const int N = 5001000;
int root = 0, tot = 0;
int ch[N][26];
vector<int> ans[N];
void insert(string s, int num)
{
int p = root, len = s.size();
for(int i = 0; i < len; i++)
{
int x = s[i] - 'a';
if(!ch[p][x]) ch[p][x] = ++tot;
p = ch[p][x];
}
ans[p].push_back(num);
}
void getans(string s)
{
int p = root, len = s.size();
for(int i = 0; i < len; i++)
{
int x = s[i] - 'a';
if(!ch[p][x])
{
cout <<endl;
return ;
}
p = ch[p][x];
}
if(ans[p].size() > 0)
{
cout << ans[p][0] << " ";
for(int i = 1; i < ans[p].size(); i++)
{
if(ans[p][i] != ans[p][i - 1]) cout << ans[p][i] << " ";
}
}
cout <<endl;
return ;
}
int main()
{
int n, m;
string s;
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> m;
while(m--)
{
cin >> s;
insert(s, i);
}
}
cin >> m;
while(m--)
{
cin >> s;
getans(s);
}
return 0;
}
这题是Trie树的经典应用,查找一个字符串是否在母串中出现过,老师都没讲
其实我还做了一个思考,将 从普通的布尔型转为整型,就可以清晰的发现次数:没出现过为0,说明有错;为1说明正确;大于1说明点名多次,这样更便捷
看看我写的:
CPP#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N = 500005;
int n, m, ch[N][30], fl[N], tot;
string s;
void insert(string s)
{
int r = 0, len = s.size();
for(int i = 0; i < len; i++)
{
if(!ch[r][s[i] - 'a']) ch[r][s[i] - 'a'] = ++tot;
r = ch[r][s[i] - 'a'];
}
fl[r] = 1;
}
int fd(string s)
{
int r = 0, len = s.size();
for(int i = 0; i < len; i++)
{
if(!ch[r][s[i] - 'a']) return 0;
r = ch[r][s[i] - 'a'];
}
return fl[r]++;
}
signed main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> s;
insert(s);
}
cin >> m;
while(m--)
{
cin >> s;
int p = fd(s);
if(p == 0) cout << "WRONG" <<endl;
if(p == 1) cout << "OK" <<endl;
if(p > 1) cout << "REPEAT" <<endl;
}
return 0;
}
这题换成了二进制,有点特殊,所以我也不想写,听听看老师咋说:
第一步,Trie的建树
第二步,计算每一个节点u之后还有几个节点,当然不包括点u,当预处理做
最后一步,开始查询,本串结束或者字符不在字典树出现就退出循环
老师开小窗一起写,我把他的注释也放这了:
CPP#include <bits/stdc++.h>
using namespace std;
const int N = 500001;
int n, m, cnt = 1, ch[N][2], b[N], e[N], len, s[N];//ch数组因为只有01两种可能,所以第二维只用了2
void build()//建树,老生常谈了
{
cin >> len;//其实和一般Trie的建树差不多,只不过这里字符串的长度需要输入而已
for(int i = 0; i < len; i++)
{
cin >> s[i];
}
int u = 1;
for(int i = 0; i < len; i++)//这里是只有01的Trie,所以不用字符转数了
{
int c = s[i];
if(!ch[u][c]) ch[u][c] = ++cnt;
u = ch[u][c];
}
b[u]++;
return;
}
void search()//搜索
{
cin >> len;
for(int i = 0; i < len; i++)
{
cin >> s[i];
}
int u = 1, sum = 0;
for(int i = 0; i < len; i++)
{
int c = s[i];
if(ch[u][c]) u = ch[u][c];
else
{
cout << sum <<endl;
return;
}//这里不能+end[u],推一下会发现有可能被加两次哦
sum += b[u];
}
cout << sum + e[u] <<endl;
return;
}
int make(int u)
{
int k1 = 0, k2 = 0;
if(ch[u][0]) k1 = make(ch[u][0]);//如果左边还有节点就继续找
if(ch[u][1]) k2 = make(ch[u][1]);//如果右边还有节点就继续找
e[u] = k1 + k2; //节点u之后还有k1+k2个节点
return b[u] + e[u];
}
int main()
{
cin >> n >> m;
for(int i = 1; i <= n; i++)
{
build();//建树
}
e[1] = make(1);//找信息
for(int i = 1; i <= m; i++)
{
search();//顺题搜索
}
return 0;
}
这是Trie树的另一种应用,看看老师怎么说:
随便指定一个根 ,用 表示 和 之间的路径的边权异或和,那么 ,因为 LCA 以上的部分异或两次抵消了
那么,如果将所有 插入到一棵 trie 中,就可以对每个 快速求出和它异或和最大的 :
从 trie 的根开始,如果能向和 的当前位不同的子树走,就向那边走,否则没有选择
贪心的正确性:如果这么走,这一位为 1;如果不这么走,这一位就会为 0。而高位是需要优先尽量大的
CPP#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
const int M = 3100010;
int root = 0, tot = 0;
int ch[M][2], p[N], fa[N];
struct edge
{
int to, val;
};
vector<edge> g[N];
void dfs(int u)
{
for(edge e:g[u])
{
int v = e.to;
if(v == fa[u]) continue;
fa[v] = u;
p[v] = p[u] ^ e.val;
dfs(v);
}
}
void insert(int x)
{
int p = root;
for(int i = 30; ~i; i--)
{
int c = (x >> i) & 1;
if(!ch[p][c]) ch[p][c] = ++tot;
p = ch[p][c];
}
}
int getans(int x)
{
int p = root, res = 0;
for(int i = 30; ~i; i--)
{
int c = (x >> i) & 1;
if(ch[p][!c])
{
p = ch[p][!c];
res |= 1 << i;
}
else p = ch[p][c];
}
return res;
}
int main()
{
int n, w, v, u;
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> u >> v >> w;
g[u].push_back(edge{v, w});
g[v].push_back(edge{u, w});
}
dfs(1);
for(int i = 1; i <= n; i++)
{
insert(p[i]);
}
int ans = 0;
for(int i = 1; i <= n; i++)
{
ans = max(ans, getans(p[i]));
}
cout << ans;
return 0;
}
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...