专栏文章
(11.3)OI 考场易错点&卡常整合
算法·理论参与者 158已保存评论 183
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 183 条
- 当前快照
- 1 份
- 快照标识符
- @minio8p7
- 此快照首次捕获于
- 2025/12/02 03:02 3 个月前
- 此快照最后确认于
- 2025/12/02 03:02 3 个月前
本文尝试对初次参与 CSP 的选手在复赛赛场中一些容易遇到的问题进行汇总,并对一些较高概率派上用场的卡常技巧进行总结。由于本人水平与时间均有限,只能在复赛前一周匆匆发表,本文仍待勘误与补充,欢迎各位阅后进行指正。
本文接受投稿。如果你认为文中有什么介绍不够完全的地方,或应有的内容未得加入本文,可以带有依据地联系我,可以要求我在更新后的内容中署上你的用户名。
易错点汇总
这是对 OI 比赛中初学者易犯错误的整合。
文件名字
如果你使用 Windows 系统,请务必把文件查看中的“显示文件扩展名”打开,不然可能出现如下情况:
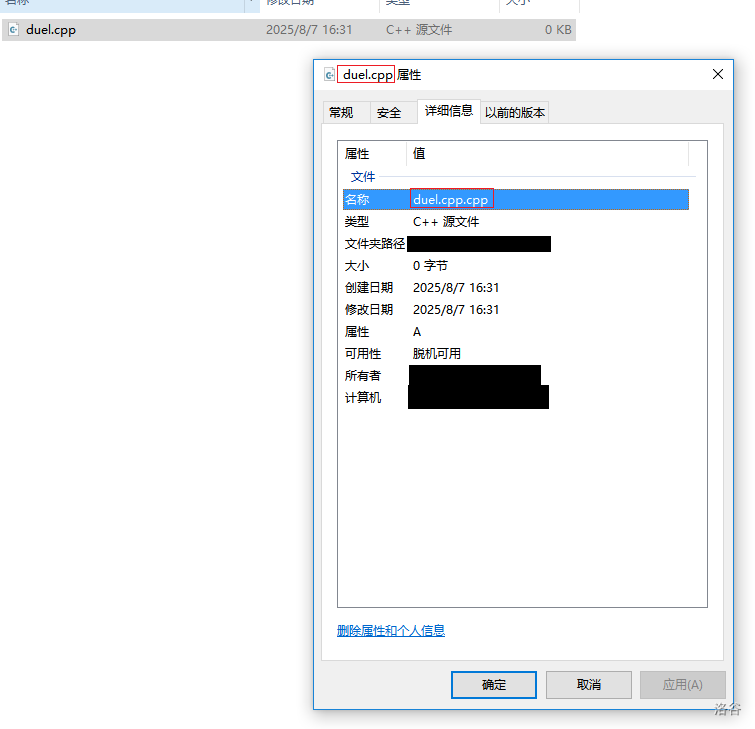
你以为的文件名字:
实际上的文件名字:
duel.cpp实际上的文件名字:
duel.cpp.cpp请务必检查此问题。
#include<bits/stdc++.h>
在部分编译环境中,错把
#include<bits/stdc++.h> 打成 #include<bits\stdc++.h> 可以通过编译。但是此错误会在 CCF 标准的评测环境中暴露出来,没注意到就会爆零。
压行导致错判缩进
众所周知,循环、判断等语句在后面只有一个语句的时候可以不打大括号。
CPPif(v == fa)
continue;
也可以写成这样,达到压行的效果:
CPPif(v == fa) continue;
但是要注意了,这里的一个语句是指严格的一个用分号作结的语句,把两个语句放在一行并不能使它们都被前面的判断/循环语句识别到。例如:
CPPif(v == fa) printf("ring found\n");continue;
实际会被编译成:
CPPif(v == fa){
printf("ring found\n");
}
continue;
注意逗号隔开的两个子句实际上是算一个语句的,但是像 break 这种语句是不能用逗号与其他语句连接的,致使上面这种问题产生。
另外:一个 if 和与其配对的 else 将被视作一个语句。例如:
CPPif(nai_long) for(auto i : a) if(i == "nailong") printf("woshinailong");
else printf("wocaishinailong");
实际上编译出来是:
CPPif(nai_long){
for(auto i : a){
if(i == "nailong"){
printf("woshinailong");
}
else{//你以为这个 else 是和外层的 if 配对的?
printf("wocaishinailong");
}//实际上因为没有大括号的 for 会抓取下面的一整个语句,这个 else 和后面的 if 被 for 抓起来硬凑一对了
}
}
未定义行为
未定义行为,简称 UB,C++ 的语言标准并没有对所有可能的代码进行特判,因此当你写出了一些语言标准没有预料到的代码时,你的代码被解读的方式,或者说,运行的结果,就全权由编译环境和编译器决定了。
当你下载数据后发现本地运行和 OJ 评测结果不一样时,就该意识到 UB 发力了。NOIP 及更下层的比赛通常不提供自测程序,故使用其他环境进行代码编写时一定要避免 UB 埋雷。
下面给出一些典型 UB。
大部分导致 RE 的情形
是的,数组越界访问是未定义行为。这就是为什么有的时候你的数组越界后评测结果是 WA 而非 RE。(原理可能是这个越界的下标对应计算的内存刚好是另外一块已经存放数据的内存)
类似地,vector 下标越界访问,vector、deque、stack 等为空时进行 pop,set、map、vector 等解引用 begin 左侧的、end 及 end 右侧的、已失效的迭代器,使用野指针均为未定义行为。
整形数值除以零或对零取余是未定义行为。
在单个语句内对一个对象做多次修改
cout << cnt ++ + ++ cnt;编译器可以先执行
cnt ++,再执行 ++ cnt,相当于 cout << 2 * cnt + 2,cnt += 2;反之相当于 cout << 2 * cnt + 3,cnt += 2。ans[++ a] = a;先执行
++ a,则效果相当于 ans[a + 1] = a + 1,a ++;;先执行后面的 a 获取要赋的值,则效果相当于 ans[a + 1] = a,a ++。x = x ++;先执行赋值再进行自增,相当于
x = x,x ++;;先执行自增再赋值,相当于 int temp = x,x ++,x = temp;。none-void 函数未进行返回
在 CCF 的评测环境中,此类函数被运行会导致 RE、TLE、MLE 或其他未知的可能结果;在 Dev-C++ 等编译器的环境下,此类行为默认不被报出,即你的函数可能会返回一些未知值并使程序继续运行。
我对这个问题影响深刻是因为我的一名同学在 CSP-S2024 中因为少了一行
return true; 导致超速检测一题 RE 爆零,而他的代码在 Windows 环境下可以正常跑过样例。解决方法是使用与 CCF 评测环境相同的编译器(考场上的 VSCode 等),或编译时使用 -Wall 指令。
举例:
CPP#include<bits/stdc++.h>
using namespace std;
int add(int a,int b){
int sum = a + b;
}
int main(){
int a,b;
cin >> a >> b;
printf("%d\n",add(a,b));
return 0;
}
将此代码提交至 P1001 A+B Problem,评测结果是 MLE 而非 WA。
有符号整数溢出
有符号整数溢出是未定义行为。
无符号整数溢出是定义行为。
printf 确认格式说明符与数据类型不一致
用
%d 输出 long long 类型的值,用 %lld 输出 int 类型的值,用 %LF 输出 long double 类型的值等均为未定义行为。例如:
CPP#include<bits/stdc++.h>
using namespace std;
int a,b;
int main(){
scanf("%d%d",&a,&b);
printf("%lld\n",a + b);
return 0;
}
#define int long long
根据 C++ 语言标准,重新定义关键字的行为被禁止,因此
#define int long long 属于未定义行为。但是现在主流编译器的环境对此类未定义行为的反应已经统一了。以此为例展示一类在考场中不会造成爆零危害/几乎不会使程序执行结果变得不可预测的未定义行为。
但是,为了代码的可读性以及避免一些输出时的问题,建议用
#define ll long long 代替 #define int long long。变量名与函数重载冲突
一些变量名被头文件所使用,将其作为全局变量将会在 CCF 的评测系统中产生 CE。可以尝试此段代码:
CPP#include<bits/stdc++.h>
using namespace std;
int y0;
int main(){
cin >> y0;
cout << y0 << '\n';
}
这段代码甚至在我本地的 VSCode 中都可以运行。但是打开洛谷 IDE 进行测试就会产生 CE。
类似的变量名很多不一一列举。防范的方法有:
- 使用 CCF 评测系统相同的编辑器。
- 据观察类似违禁变量名中大写字母出现较少,可以尝试在变量名中使用大写字母。
- 避免在变量名中使用完整的英文单词。否则可能会撞
next、end、time等。 - 避免使用英文加数字的组合,如
y0、j0等。 - 在不确定是否会冲突的情况下,将全局变量改为局部变量。
撞重载就是你定义的函数、命名空间 std 的函数、头文件的函数之间产生了冲突,例如
using namespace std; 后调用 abs() 后可能产生的问题。本人知识有限就不加以介绍原理了。由于各种问题的可能存在,建议不使用虚拟机参赛的选手赛前学会在自己的编辑器上使用
-Wall 指令,可以排查出一部分的包括 non-void 函数无返回值的问题。size_t 与无符号相关
在 C++ 中表示容器大小的类型是 size_t,在大部分编译环境(包括 CCF 官方环境)中基本等效于 unsigned long long。因此直接调用一个容器的大小进行运算可能会存在向下溢出至极大值处的问题。
CPPvector<int> v;
/*部分程序*/
for(int i = 0;i <= v.size() - 1;i ++) printf("%d ",v[i]);
这样的代码是存在风险的。当 v 为空时,
v.size() 值为 ,因为其为无符号类型减一后会溢出至 ,也即此循环会从 一直遍历到 。类似地,由于大部分基本数据类型与 unsigned long long 进行运算时都会被转为后者,所以不要使用负数与 size 进行比较。例如
-1 >= v.size() 这个表达式结果恒为 true,因为 是 int 类型量,运算时转为了 unsigned long long 向下溢出为 。结合在使用 printf 输出内容时可能存在的问题,建议使用 printf 输出 size_t 类型时强制转为 int 类型后输出。
也有例外,貌似 CF 的某个评测环境中表示大小的类型等效于 int。
size_t 不完全等效于 unsigned long long,例如 C++14(GCC 9)中没有关于
max(size_t,unsigned long long) 的重载,写出 max(v.size(),1ull) 这样的东西将会编译失败。结构化绑定
C++14(GCC 9)允许使用 auto,允许使用 auto 遍历 vector、map、set 等,允许对 pair、tuple 进行结构化绑定,允许对结构体进行结构化绑定。
signed main
CCF 历年考场下发 pdf 文件及一些条例中提到:主函数类型只能是 int。因此一些人对能否使用 signed main 产生疑问。
如果你较为熟悉 C++ 语言,你应该清楚几乎一切基本类型变量(bool 除外)都有有符号和无符号之分,对应前缀 signed 和 unsigned。我们可以不写这个前缀,是因为这些类型存在默认的前缀,除 char 外其他类型默认具有前缀 signed。另外,当你使用 signed 或 unsigned 表述一个类型时,编译器将默认其为 int。char 在不同环境下的默认前缀可能不同。
省流:signed=int=signed int。就是完全一样的东西嘛。
如果你还有疑虑:
众所周知,
#define int long long 几乎必然导致你要写出 signed main 这样的东西。我们寻找在 NOIP 中使用 #define int long long 的案例:
在 NOIP2024 ZJ 选手提交的代码中,442 个文件出现了子段
#define int long long。信不过我你还信不过真的用了这玩意的选手吗。文件读写
文件读写模板:
CPP#include<bits/stdc++.h>
using namespace std;
int main(){
freopen("xxx.in","r",stdin);
freopen("xxx.out","w",stdout);
/*程序主体*/
}
本人参赛从未在赛时代码中加入任何关闭文件的操作,在程序末尾关闭文件是不必要的。如果不对文件进行其他操作,这份模板不会与本文中介绍的所有读入方式产生冲突。
据悉关闭文件的操作可能与刷新缓冲区的操作存在冲突。即使用未解绑 cin、输出 endl、fflush 与关闭文件的操作在同一程序中时可能会导致你的代码不能正确输出以致爆零。
文件比对
如果你不会使用指令相关,考场上遇到动辄数十万行输出的大样例是否就只能肉眼比对开头几行和最后几行输出就摆烂了?这里提供一个简单的思路:我们把输出文件和答案文件忽略空格和换行视作字符串,比对它们的哈希值。
CPP#include<bits/stdc++.h>
using namespace std;
char c;
long long MOD = 1000000007,P = 998244353,ans;
int main(){
freopen("xxx.out","r",stdin);//out 和 ans 分别跑一次,比较输出的数字是否相同
// freopen("xxx.ans","r",stdin);
cin.tie(0)->sync_with_stdio(0);
while(cin >> c) ans = (ans * P + c) % MOD;//cin 自动忽略空格和换行
printf("%lld\n",ans);
return 0;
}
卡常汇总
免责声明:本人才疏学浅,并未模拟出真实的考场评测环境,因此特殊情况下部分结论可能对考场应用的实用性较低,请诸位仔细辨别,本人不对因此产生的问题负责。如果发现此类问题请尽快向我反馈,感谢理解!
出于一些原因,请通过加入洛谷代码公开计划且通过对应的题目的方式查看评测结果中的代码。
评测统一使用洛谷 C++14(GCC 9)。
读入
使用洛谷题目 P10815 【模板】快速读入 对各类读入的效率进行评测。
我们认为 300ms 以内是 OI 题目的合理读入时间。
声明:模板题测出的效率可能会比正常 OI 题目快,请不要把此题中的读入效率不加转换地当作 OI 比赛中对应输入方式的读入效率!
cin 读入
合理读入时间内可以读入大小约为 的数据,对大规模输入的程序效率存在影响。
scanf 读入
合理读入时间内可以读入大小约为 的数据,效能约是 cin 读入 的两倍,对大规模输入的程序效率仍存在一定影响。
解绑 cin 读入
合理读入时间内可以读入大小约为 的数据,效能约是 scanf 读入 的两倍,一般情况下不会对题目输入效率造成显著影响。
横向比较——返回值快读与传址快读
返回值快读
传址快读
显然传址快读更胜一筹。
getchar 快速读入
效能较 解绑 cin 读入 提升一倍,合理时间内可以处理 级别的读入。
getchar_unlocked 快速读入
此读入方式在部分环境下不可用。在 CCF 评测环境下可用。
较前版快读效能提升一半,合理时间内可以处理 级别的数据。
其他更快的也更繁琐的快读就不介绍了,考场上没有必要,卡到这个程度还不如为评测机波动祈祷。
最近公共祖先的四种求法
为了保证适用性,这里只介绍容易理解的、广为人知的、好写好调的在线算法。
使用洛谷题目 P3379 【模板】最近公共祖先(LCA)
进行测试。
树上倍增
原理:两个点向上跳到同一高度,然后上跳到最高的两点不相同的位置,此时再往上跳一步就是最近公共祖先。两个步骤都用树上倍增实现。
时间复杂度:预处理 ,单次询问 ,总时间复杂度 。
可以看到效率并不是很理想,在 的数据下最慢点已经被卡出了 1s。
ST 表——欧拉序
原理:两个点在欧拉序中第一次出现的位置之间出现过的深度最小的点是为其最近公共祖先。用 ST 表实现。
时间复杂度:预处理 ,单次询问 ,总时间复杂度 。
在小点上效果平平甚至较于倍增更劣,但大点几乎快了一倍。整体上效能有提升,但是由于欧拉序长度接近 ,所以有一个大约为 的常数。
ST 表——dfs 序
原理:两个点在 dfs 序中出现的位置之间最高的点的父亲是为其最近公共祖先(还有一些简单的边界情况需要做一些归纳)。用 ST 表实现。
时间复杂度:预处理 ,单次询问 ,总时间复杂度 。
显著地变快了!此写法相当好写,可以考虑考场上用。
树链剖分
原理:进行重链剖分,求 LCA 时不断找到链顶深度较大的点,跳至链顶的父亲直至两点位于同一条重链上。由于重链剖分的性质,一次求 LCA 的复杂度是 的。
时间复杂度:预处理 ,单次询问 ,总时间复杂度 。
快于倍增和欧拉序,略慢于 DFS 序。如果你学习过树剖,学会此 LCA 求法并不需要太多时间。
结论
倍增:老牌写法,包括我在内的不少人初学 LCA 都是从这里开始的,可以作为树上倍增思想的启蒙。但是时间效率较其他做法过于低下,预处理和调用都带一个 。
欧拉序:一度风靡的写法,倍增的强势替代, 查询带来的时间优势不是一星半点。
DFS 序:
Alex_Wei:将 DFS 序求 LCA 发扬光大,让欧拉序求 LCA 成为时代的眼泪!
近几年新生的写法,脱胎于欧拉序 ST 表而时间效率严格强于后者。一度成为洛谷 LCA 模板题题解区顶部做法。
树剖:老牌做法之一。预处理少一个 且一般不会卡满,存在前置证明。
Tarjan:离线线性,不建议只学此一种,遇到如 NOIP2024 树上查询部分分中对区间 LCA 建 ST 表或线段树的情况时会因为需要离线而吃瘪。
最近还出了个斜二倍增,听说比树剖快,看情况进行测试。
存图方式
存储无边权边
使用洛谷题目 P1144 最短路计数
进行评测,均使用相同的 算法。
时间效率方面,链式前向星完胜 vector。
存储带权边
使用洛谷题目 P4779 【模板】单源最短路径(标准版)
进行评测,均使用 Dijkstra 算法。
时间效率方面,链式前向星完胜 vector。
vector 卡常优化——预申请空间
灵感来自《如何存图》。不难发现,vector 存图的主要时间开销在建图部分。这是因为 vector 需要经常地申请内存分配。
众所周知 vector 存在一个函数 reserve,可以预先为 vector 申请空间,避免多次申请内存。我们考虑先记录每个点的度数,为每个点对应的 vector 申请好空间之后再建图,看看是否存在优化。
稀疏()无向图测试结果如下:
随机生成了一个稠密()有向图跑 BFS,测试结果如下(三次取均值):
可见在稠密图中,reserve 优化还是效果显著的。
结论
稀疏图上链式前向星速度完胜 vector,但 vector 在稠密图中效果更佳(见《如何存图
》)。建议同时掌握两种存图方式的调试技巧,没准哪天用上了呢?
线段树
以下区分单点修改线段树和懒标记线段树,分递归式和非递归式的一些实现做一些讨论。
递归式对比:当前结点区间的存储
主流的两种写法中一种是把当前结点的左右区间存入结构体中,在建树时做预处理;另一种写法是在调用函数时作为参数计算下传。
用于测试的题目为 P4513 小白逛公园。
显然传参明显更优。
非递归式线段树
又名 zkw 线段树,码量略小于递归式线段树,据传常数更小,速度更快。
用于测试的题目为 P4513 小白逛公园。
非递归式线段树显著快于递归式线段树。
ull 和 ll 乘法取模
idea 来自 jucason_xu:NOI2025卡线记
你说得对我并不会做 NOID2T2。但是我们只需要测试乘法取模的效率即可。随机生成 个正整数进行乘法取模,结果如下(三次取中间值):
存在较明显的差异。如果按一道题进行 次乘法取模算,时间差异可达到 200ms。
相关推荐
评论
共 183 条评论,欢迎与作者交流。
正在加载评论...