专栏文章
浅析sort
科技·工程参与者 114已保存评论 126
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 126 条
- 当前快照
- 1 份
- 快照标识符
- @mhz5sq6b
- 此快照首次捕获于
- 2025/11/15 01:56 4 个月前
- 此快照最后确认于
- 2025/11/29 05:24 3 个月前
0.前言
相信每个入门的同学都见过这样一个题目:
给定一些整数,将它们从小到大排序后输出
同学们常常会写这样的代码:
CPP#include<bits/stdc++.h>
using namespace std;
int n,a[1000010];
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;++i)scanf("%d",&a[i]);
sort(a+1,a+1+n);
for(int i=1;i<n;++i)printf("%d ",a[i]);
printf("%d\n",a[n]);
return 0;
}
这里的
sort就是我们今天的主角别看它语句短小,但却无比精悍
更新部分,增添了"还是//3"一项
1.观察
首先,观察
sort的来源(我这里使用了VSCode的速览定义功能)观察到它包含在
stl_algo.h文件中(这一文件包含在algorithm头文件中)找到其定义为
CPP template<typename _RandomAccessIterator>
inline void
sort(_RandomAccessIterator __first, _RandomAccessIterator __last)
{
typedef typename iterator_traits<_RandomAccessIterator>::value_type
_ValueType;
// concept requirements
__glibcxx_function_requires(_Mutable_RandomAccessIteratorConcept<
_RandomAccessIterator>)
__glibcxx_function_requires(_LessThanComparableConcept<_ValueType>)
__glibcxx_requires_valid_range(__first, __last);
//start
if (__first != __last)
{
std::__introsort_loop(__first, __last,
std::__lg(__last - __first) * 2);
std::__final_insertion_sort(__first, __last);
}
//end
}//这里吐槽一下C++ STL编写者的码风
看到变量是
_RandomAccessIterator(即随机迭代器)这是个什么东西鸭?其实就是数组、
vector、deque这类东西的实现方法接下来观察到其主体代码是从
//start到//end的部分,前面可以不管2.深入分析
2.1 __introsort_loop
这是个什么玩意?

template<typename _RandomAccessIterator, typename _Size, typename _Compare>
void
__introsort_loop(_RandomAccessIterator __first,
_RandomAccessIterator __last,
_Size __depth_limit, _Compare __comp)
{
while (__last - __first > int(_S_threshold))//5
{
if (__depth_limit == 0)
{
_GLIBCXX_STD_A::partial_sort(__first, __last, __last, __comp);//4
return;
}
//1
--__depth_limit;
_RandomAccessIterator __cut =
std::__unguarded_partition_pivot(__first, __last, __comp);//3
std::__introsort_loop(__cut, __last, __depth_limit, __comp);
__last = __cut;
//2
}
}
如上是其源码,发现它是一个递归结构
2.1.1 //1到//2
不难看出
//1与//2之间正是快速排序实现然而……貌似它只处理了右区间部分?左区间怎么办呢?
别急,我们来重新浏览一下:
它在排完序之后把
cut的值付给了last然后由于它是循环,所以……下一次就是处理左区间了
所以它相比于我们所写的排序优点正是此处
巧妙地将递归换成了循环,虽然复杂度不变,但常数就是大幅提升了
这似乎从一方面解释了
sort比手写排序快的原因(借用一个图):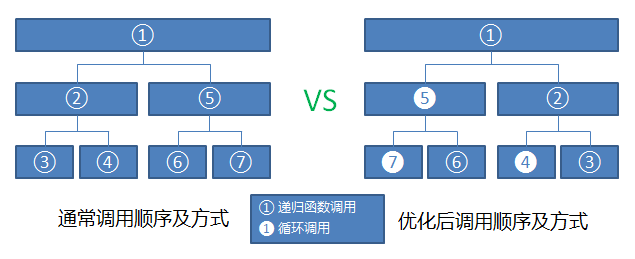
2.1.2 //3
不过这并不能让快排避免退化的危机,只能解决常数问题
然而
sort似乎基本没有退化过,这是为什么呢?首先注意
//3处(pivot就是常说的哨兵)这里的哨兵并没有使用
start,last,中部中的任何一个通过持续跟踪,发现哨兵使用的是三者的中值
这就从一定程度上优化了算法
2.1.3 还是//3
老样子,直接上这一部分的源码:
CPPtemplate<typename _RandomAccessIterator, typename _Compare>
inline _RandomAccessIterator
__unguarded_partition_pivot(_RandomAccessIterator __first,
_RandomAccessIterator __last, _Compare __comp)
{
_RandomAccessIterator __mid = __first + (__last - __first) / 2;
std::__move_median_first(__first, __mid, (__last - 1), __comp);
return std::__unguarded_partition(__first + 1, __last, *__first, __comp);
}
__move_median_first是用来将三者从小到大排序__unguarded_partition而不断去交换位置错误的元素,直到first和last指针无有效区域为止它并不会去做任何一次比较运算(这一点在下文中也有提及)
那么,为什么能不比较呢?
它由于的保证(即使用三者的中值),可以得出一定会在超出有效区域之前中止
也就是说,它可以保证不需要比较,可以自动操作,不必考虑越界问题
不比较,又可以进行一定的常数优化
减少常数、运算次数,就是(所以连码风都不管了)
STL编写者的唯一目的 这一算法被称之为分割算法(即原版本说的没看懂的部分,也是对的一些补充)
2.1.4 //4
这个
partial_sort是什么?为什么要用它?通过调查源码,发现这个
partial_sort就是堆排:
那么
depth_limit是什么?有何作用?回到
sort本体,发现depth_limit即(亦即)如果递归次数到达会怎么样?
退化,在退化之际使用堆排来弥补,可以基本解决退化
这也正是
sort不退化的奥秘所在2.2 __final_insertion_sort
这……终极插入排序?(雾)
前面不是排好了么?要它何用?
等等,回到的
//5处,这个_S_threshold是?查阅定义得,
_S_threshold为,一个常数?所以说……快排剩了最前面个不排,交给插入排序?
理论上就算退化复杂度也才相当于插入排序啊,为什么呢?
这时就需要复习一下插排的概念了
2.2.1 插排复习
插排原理:每一个元素通过比较,找到应插入位置
其特点:最好情况(基本有序)复杂度
这样就可以理解了,快排保证了前个元素基本有序,但非完全有序
所以,这样只要就可以排好最左边个
2.2.2 分析
以为这就结束了?想的太简单了

观察
CPP__final_insertion_sort源码:template<typename _RandomAccessIterator, typename _Compare>
void
__final_insertion_sort(_RandomAccessIterator __first,
_RandomAccessIterator __last, _Compare __comp)
{
if (__last - __first > int(_S_threshold))
{
std::__insertion_sort(__first, __first + int(_S_threshold), __comp);
std::__unguarded_insertion_sort(__first + int(_S_threshold), __last,
__comp);
}
else
std::__insertion_sort(__first, __last, __comp);
}
可以看到,又调用了两个插入排序,它们分别的代码:
CPPtemplate<typename _RandomAccessIterator, typename _Compare>
void
__insertion_sort(_RandomAccessIterator __first,
_RandomAccessIterator __last, _Compare __comp)
{
if (__first == __last) return;
for (_RandomAccessIterator __i = __first + 1; __i != __last; ++__i)
{
if (__comp(*__i, *__first))
{
typename iterator_traits<_RandomAccessIterator>::value_type
__val = _GLIBCXX_MOVE(*__i);
_GLIBCXX_MOVE_BACKWARD3(__first, __i, __i + 1);
*__first = _GLIBCXX_MOVE(__val);
}
else
std::__unguarded_linear_insert(__i, __comp);
}
}
template<typename _RandomAccessIterator, typename _Compare>
inline void
__unguarded_insertion_sort(_RandomAccessIterator __first,
_RandomAccessIterator __last, _Compare __comp)
{
typedef typename iterator_traits<_RandomAccessIterator>::value_type
_ValueType;
for (_RandomAccessIterator __i = __first; __i != __last; ++__i)
std::__unguarded_linear_insert(__i, __comp);
}
这里就不贴
__unguarded_linear_insert的代码了,只需要知道其作用其作用是找到应插入的位置并插入(无底洞啊,不建议自己查看)
而如果,当前值要插在前头,直接让其他的后移
理论上和普通插排毫无区别实际也是,但是略微对常数有所优化
那
__unguarded_insertion_sort与__insertion_sort有何区别?又有什么用?貌似是省去了
if的判断句?仅此而已?!
对,仅此而已。
但是为什么可以去掉呢?
因为这一排序是建立在最左边永远是最小值的基础上的
不仅是
__unguarded_insertion_sort、__unguarded_partition,事实上,所有的以__unguarded开头的函数都不会考虑越界!
而众所周知,比较函数是很耗时的,因此常数会有较大提升
2.2.3 效率
我们从各种操作入手分析
首先,经典插排,次比较,次赋值,次减法,次自减。
其次,
__insertion_sort分两种情况:
每次第一分支,即
if语句执行情况,次比较,次赋值,次自减/加(注意:此处这类常数不可忽略)每次第二分支,即
else语句执行情况,次比较,次赋值,次自减那么假设二者出现概率相同,则平均为次比较,次赋值,次自减
可以看到,少了次比较,次赋值,次减法,多了次自减
而且,已知比较时间开销很大,赋值小一些,而减法、自减基本不耗时
而
__unguarded_insertion_sort则是次比较,次赋值和次自减(与每次第二分支时间复杂度基本相同)不过,在很大时,的常数也会很大,这也是一直没有省略的原因
(以上复杂度请自行证明)
2.2.4 其他
既然
__unguarded_insertion_sort的时间要小得多,那么为什么不直接用呢?不知道读者有没有注意到2.2.2最后有一行加粗的字体
这一行字解释了为什么不能直接用
__unguarded_insertion_sort排序等等,如何保证在
__insertion_sort后,全局最小值在左边呢?先回到
__introsort_loop,它在什么情况下会返回呢?一是区域小于等于16(即
_S_threshold),二是超过depth_limit,也就是而由快排定义可知,左边区间的所有数据一定比右边小(也可参考图):

所以,如果是第一种情况,就可以得出最小值在左边
如果是第二种情况,那么最左边的区间会调用堆排序,所以这段区间的最小值一定位于最左端。再加上左边区间所有的数据一定比右边小,那么最左边的数据一定是全局最小值
3.其他
至此,我们完成了对
sort的初步探究(仅是初步)那么,是不是所有容器都能使用
sort呢?并不是,主要有
vector、list、数组可以使用unordered_开头的容器只有前向迭代器,然而在1中已经说过,只有随机迭代器才能使用sort而,
map、set、priority_queue这类自带排序的当然是用不了了而
queue、stack这类则因为它们对出口和入口做了限制,无法排序那
list呢?它的迭代器是双向迭代器,也不行不过不必担心,众所周知,
list自带list::sort,虽然不能用std,但可以自己使用万万没想到啊,一个小小的
sort居然有这么多优化不得不说,
C++ STL编写者真的把编译器的效率压榨了不少,真是视效率如生命啊!试问:有多少人能够自己写出像
STL这样好的库?这正是C++优点所在(并未引战)
什么?平板电视?反正平板电视也没
sort这倒是让我想起一个东西:平方根倒数速算法
相关推荐
评论
共 126 条评论,欢迎与作者交流。
正在加载评论...