upd on 5.25 - 修改了三处笔误
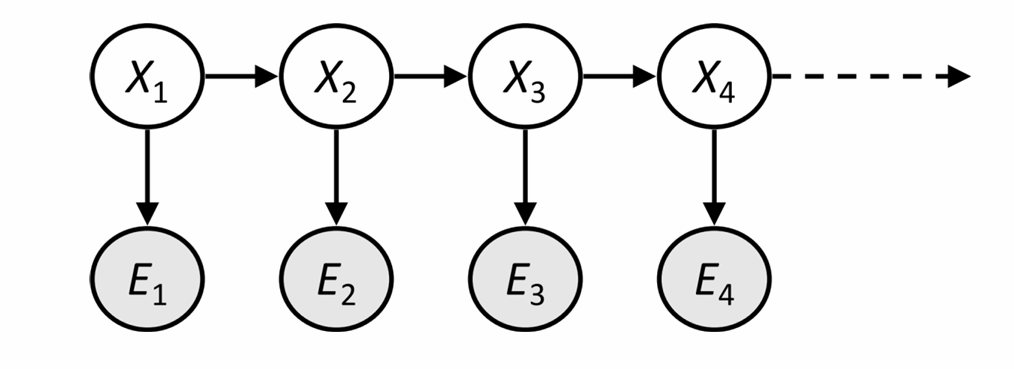
隐马尔可夫模型
一. 隐马尔可夫模型的性质
-
具有马尔可夫性的状态序列
X,但这个序列是不可被直接观测的,故称之为
隐状态序列,我们假设隐状态共有
N 种取值。
-
还具有一个
证据状态序列 E。对于所有时刻
t,可观测到与隐状态
Xt 有关的输出
Et。
-
独立性假设
1 :对于所有时刻
t,给定前一个时刻的隐状态
Xt−1,则当前时刻的隐状态
Xt 独立于过去所有隐状态和证据状态,即
Xt 只依赖于
Xt−1(
Xt−1 给定的条件下)。
-
独立性假设
2 :对于所有时刻
t,给定当前时刻的隐状态
Xt,则当前时刻的证据状态
Et 独立于过去所有隐状态和证据状态,即
Et 只依赖于
Xt(
Xt 给定的条件下)。
二. 隐马尔可夫模型的概率推理
0. 一些符号说明
- 隐状态序列 X:将 t 时刻的隐藏状态记为 Xt。
- 证据状态序列 E:将 t 时刻的证据状态记为 Et。
- 初始概率 π:隐状态 X 的先验概率分布,πi=P(X1=i)。
- 转移概率 A:描述前一状态转移到后一状态的概率,Ai,j=P(Xt+1=j∣Xt=i)。
- 发射概率 B:描述从隐状态到证据状态的概率,Bi(ej)=P(Et=ej∣Xt=i)。
1. 滤波任务
- 目标:根据截至当前时刻 t 的所有观测信息构成的证据状态 e1:t=(e1,e2,⋯,et),推断当前时刻 t 的隐藏状态 Xt 的概率分布 γt(i)=P(Xt=i∣e1:t)。这个分布也被称为状态置信分布或滤波概率。
至于这个任务为什么叫“滤波”,我个人的理解是——这个任务要根据当前已经观测到的状态实时反馈当前的隐藏状态的概率分布,相当于边听边翻译,这跟滤波很像,所以我们这么叫也很合理,接下来我们开始推导。
根据条件概率的公式可以比较容易地得到
P(Xt=j∣e1:t−1)=i=1∑NP(Xt=j∣Xt−1=i)P(Xt−1=i∣e1:t−1) (1)
由贝叶斯公式可知
P(A∣BC)=P(BC)P(ABC)=P(BC)P(B∣AC)P(A∣C)P(C)=P(B∣C)P(B∣AC)P(A∣C)
所以有
P(Xt=j∣e1:t)=P(Xt=j∣(et,e1:t−1))=P(et∣e1:t−1)P(et∣(Xt=j,e1:t−1))P(Xt=j∣e1:t−1) (2)
P(et∣(Xt=j,e1:t−1))=P(et∣Xt=j) (3)
将
(1),(3) 两式带入
(2) 式即可得到
令常数
α=P(et∣e1:t−1)1,则
即
γt(j)=αBj(et)i=1∑NAi,jγt−1(i)
如果我们定义两个
N 维向量到一个
N 维向量的运算
(a∘b)i=aibi,将
γt=[γt(1),⋯,γt(N)]⊤ 和
B(et)=[B1(et),⋯,BN(et)]⊤ 看作
N 维列向量,转移写成矩阵形式就是
由于常数
α 不好计算,我们可以忽略这个常数,直接计算得到
γt 然后概率归一化即可。
2. 预测任务
- 目标:根据截至当前时刻 t 的所有观测信息构成的证据状态 e1:t=(e1,e2,⋯,et),预测未来时刻 t+k(k>0) 的隐藏状态 Xt+k 的概率分布 γt+k∣t(i)=P(Xt+k=i∣e1:t)。
这个任务的目标非常明确,那就让我们直接推式子吧。
首先,我们先使用滤波任务中的方法推出
γt(i)=P(Xt=i∣e1:t)。
先考虑单步预测,即如何得到
P(Xt+1=j∣e1:t) 的预测值。通过条件概率的公式,我们也可以比较容易地得到
写成矩阵形式就是
γt+1∣t⊤=γt⊤A
于是可以得到
γt+k∣t⊤=γt⊤Ak
3. 平滑任务
假如你正在听英语听力,判断说话的人在每个时间点的情绪(隐状态),那么以下是使用滤波概率推理和平滑概率推理的区别。
- 滤波:在听完前 k 秒的录音时,立即对第 k 秒的情绪做出判断。
- 平滑:在听完完整录音后,重新利用所有信息,评估第 k 秒的情绪。
我们先定义前向信息
αt(i)=P(Xk=i,e1:k)
注意区别
α 与滤波任务里的
γ,这里的
α 是联合概率,之前的
γ 是条件概率。
首先,我们先确定递推的初值
α1(i)=P(X1=i,e1)=P(X1=i)P(e1∣X1=i)=πiBi(e1)
考虑递推
αt(j)=P(Xt=j,e1:t−1,et)=P(et∣(Xt=j,e1:t−1))P(Xt=j,e1:t−1)
P(et∣(Xt=j,e1:t−1))=P(et∣Xt=j)
所以
αt(j)=P(et∣Xt=j)i=1∑NP(Xt−1=i,e1:t−1)P(Xt=j,Xt−1=i)=Bj(et)i=1∑Nαt−1(i)Ai,j
我们定义后向信息
βk(i)=P(ek+1:T∣Xk=i)
这表示在时刻
k 处于状态
i 的条件下,观测到从时刻
k+1 到
T 的后续观测序列
ek+1:T 的概率。
首先,由于
T 时刻之后没有观测序列,所以我们定义
考虑递推
βt(j)=P(et+1:T∣Xt=j)=i=1∑NP((et+1:T,Xt+1=i)∣Xt=j)=i=1∑NP((et+1,et+2:T,Xt+1=i)∣Xt=j)
由贝叶斯公式可知
P(ABC∣D)=P(D)P(ABCD)=P(BCD)P(ABCD)⋅P(CD)P(BCD)⋅P(D)P(CD)=P(A∣BCD)P(B∣CD)P(C∣D)
所以
βt(j)=i=1∑NP(et+1∣(et+2:T,Xt+1=i,Xt=j))P(et+2:T∣(Xt+1=i,Xt=j))P(Xt+1=i∣Xt=j)
βt(j)=i=1∑NP(et+1∣Xt+1=i)P(et+2:T∣Xt+1=i)P(Xt+1=i,Xt=j)=i=1∑NBi(et+1)Aj,iβt+1(i)
现在我们要求平滑概率
P(Xk=i∣e1:T)=P(e1:T)P(Xk=i,e1:T)
对于分子有
P(Xk=i,e1:T)=P(Xk=i,e1:k,ek+1:T)=P(Xk=i,e1:k)P(ek+1:T∣(Xk=i,e1:k))
P(ek+1:T∣(Xk=i,e1:k))=P(ek+1:T∣Xk=i)=βk(i)
所以
P(Xk=i,e1:T)=αk(i)βk(i)
对于分母有
P(e1:T)=j=1∑NP(Xk=j,e1:T)=j=1∑Nαk(j)βk(j)
所以平滑概率
P(Xk=i∣e1:T)=j=1∑Nαk(j)βk(j)αk(i)βk(i)
4. 解释任务
假如你正在听一段录音(观测到的证据序列),我们想知道的是最有可能的整个句子是什么,而不是每个时间点最有可能的单词的简单拼接。
- 目标:这个任务不是计算某个时刻的状态概率分布,而是找到最有可能产生整个观测序列 e1:T 的那个,即求 argmaxX1:TP(X1:T∣e1:T),由于 P(e1:T) 对于所有路径来说都是常数,所以等价于求 X1:T∗=argmaxX1:TP(X1:T,e1:T)。
考虑使用动态规划的思想,设
mt(i) 为已经观测到
e1:t,且到达当前隐状态
Xt=i 的所有可能路径中概率最大的路径的概率,即
mt(i)=X1,⋯,Xt−1maxP(X1,⋯,Xt−1,Xt=i,e1:t)。
考虑初始状态
m1(i)=P(X1=i,e1)=πiBi(e1)。
考虑枚举时刻
t−1 的状态,根据前面三种推导的方法,可以比较显然地得到状态转移式
为了记录最优路径,我们还需要开一个数组
a 来储存转移信息
整个观测序列的最可能路径的概率
P∗=maxi=1NmT(i),最优路径的最后一个状态
XT∗=argmaxi=1NmT(i),之后可以通过
a 数组反向回溯出整个最优路径
Xt∗=at(Xt+1∗)。