专栏文章
题解:P5399 [Ynoi2018] 駄作
P5399题解参与者 6已保存评论 5
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 5 条
- 当前快照
- 1 份
- 快照标识符
- @mio2mptf
- 此快照首次捕获于
- 2025/12/02 12:21 3 个月前
- 此快照最后确认于
- 2025/12/02 12:21 3 个月前
参考资料:周欣《浅谈一类树分块的构建算法及其应用》。
花了一天多的时间才过了这个题,写篇题解纪念一下。
前置知识: Top cluster 树分块
熟知 Top cluster 树分块的可以跳过这一个部分。
我们希望将一整棵树划分成若干个树簇,树簇是树上的一个连通块,并且一个簇内最多只有两个点与外界相连,我们称这两个点为界点。在实际运用中,我们要求其中一个界点是这个簇中深度最浅的点,称为上界点;剩下一个节点称为下界点。特别注意:一个界点可以属于若干个簇,但它最多是一个簇的下界点。
我们先考虑什么时候一个点 可以是界点,在深搜过程中, 是界点当且仅当满足下面三个条件中的至少一个:
- 是根节点。
- 有超过两个子树内有界点(如果 不是界点则违背了一个簇中最多有两个界点的限制)。
- 删去 子树中的界点以及界点的子树后,剩下点的数量超过了 。
通过如上的构造方式,我们可以使得界点的数量不超过 ,理由如下:第三种情况最多只会出现不超过 次,第二种情况的 的至少有两棵子树含有因为第三种情况而产生的界点,因此第二种情况发生数量一定小于第三种情况,因此总共界点数量不超过 。
我们再考虑如何划分簇,我们考虑以任意顺序遍历 的子树并维护一个集合 存储应该放到一个簇中去的所有未划分点。我们考虑什么时候应该清空 ,并将子树中的未划分点分到新的簇中去:
- 加入新子树的未划分点后, 的大小将会大于 。
- 加入新子树的未划分点后, 将会有多于 个下界点,违背了条件。
- 在先前我们没有处理 的任意子树。
我们可以发现,这样划分的每一个簇的大小都不会超过 ,而且簇的数量不会超过 (应该到不了这个上界),证明如下:第一类情况将当前子树和它的邻居进行配对,每一个组合的大小超过了 ,因此块数不超过 ,第二类情况相当于“消耗”了一个下界点,第三类情况“消耗”了一个上界点,因此总共不会超过 个块。
上述内容大部分来源于论文,但是我们应该注意到这样的划分方式有以下性质:
- 一个簇中最多有两个界点,一个簇外的点到达簇内的点必须经过这两个点的其中一个。
- 一个簇的上界点是这个簇中深度最小的点,这极大地简化了某些计算问题。
- 由于(2)的特性,我们可以建立一棵收缩树,将每一个簇的上界点和下界点连边,这一棵树的大小是 的,很适合我们进行计算。
Solution
我们可以将题目中一个点的邻域拆分成每一个簇的邻域,并且由于 Top Cluster 的特殊性质,大部分的簇的邻域中心都是界点,只有 个不满足条件。
因此,我们可以将贡献分成簇间贡献和簇内贡献分别处理,考虑计算所有的贡献:
-
不同簇之间的贡献。由于两个簇中的点之间的路径经过固定的点,我们可以在收缩树上进行树形DP来统计贡献,考虑当前点是 :
- 点 和点 的贡献:我们可以预处理出点 到 所属簇下界点的距离 ,因此 到 的距离可以写成 。
- 点 和点 的贡献:可以写成 。
因此,我们可以处理对于每一个块,两个点对应的邻域的大小,深度和,到下界点的距离和就可以转移了,这里总共的时间复杂度是 。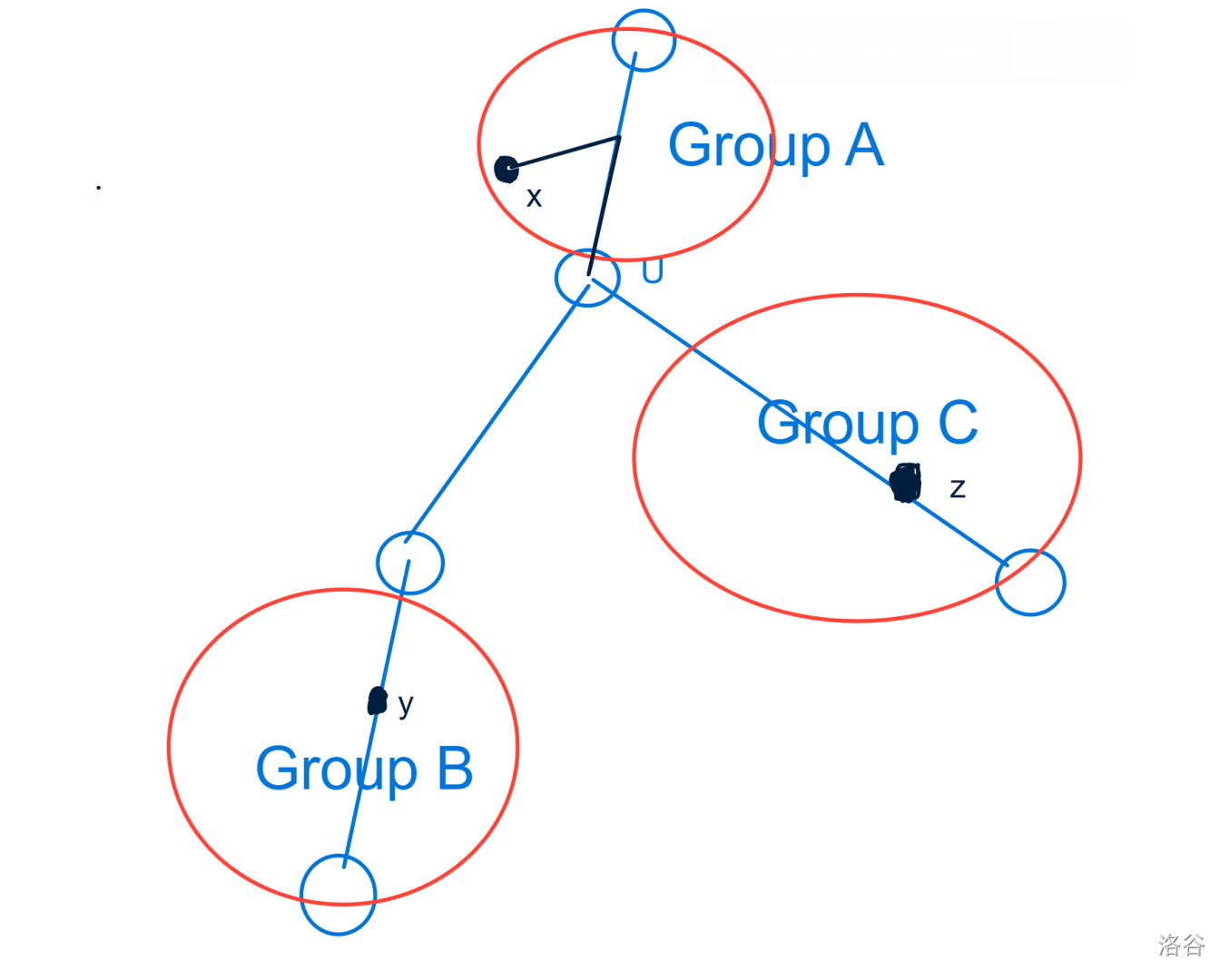
-
一个簇内两个邻域之间的贡献,并且两个邻域的中心都是界点,考虑对于每一个块预处理所有的答案, 表示第一个邻域是以上/下界点为中心,半径为 ,第二个邻域是以上/下界点为中心,半径为 ,暴力统计即可,每一块的时间复杂度是 ,需要做二维前缀和,这里的时间复杂度为
-
一个簇内两个邻域之间的贡献,两个邻域的中心至少一个不是界点,对于对于每一个询问只会有 个块会这样,因此 地计算,考虑拆贡献 ,前两项统计是容易的,后一项可以对于第一个邻域每个点到根(这里是上界点)的路径 ,查询第二个每一个点到上界点的路径和,可以较为轻松的做到 处理。这里的时间复杂度是 。
不妨设 和 同阶,取 ,时间复杂度可以做到 。
Optimization
- 块长取 比较优秀。
- 合理调整多维数组的顺序。
- 这里需要 求 ,这个东西很慢,我们可以考虑预处理出每一个簇内的点到上下界点的距离,减少调用 的次数。
- 避免使用 DFS,改成循环效率更高。
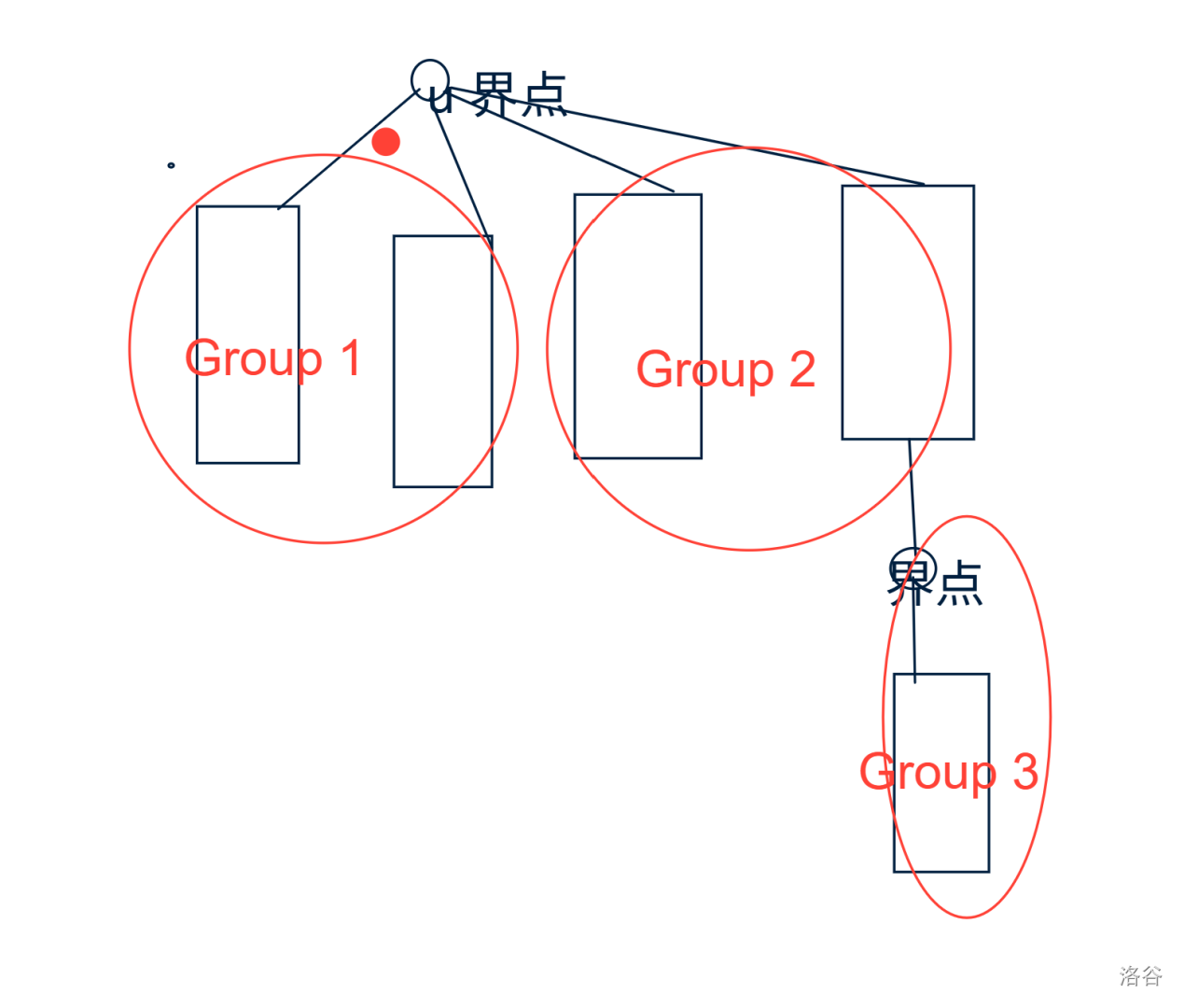
- 尝试找到一种顺序,使其是原树的dfs序,并且每一个簇的访问是连续的,这可以考虑在做 Top Cluster 的时候“以任意顺序遍历子树”改成先遍历没有界点的子树,后遍历有界点的子树,这样就可以了,可以看图理解一下。
Code
代码常数较大,极限卡过仅供参考 查看代码。
相关推荐
评论
共 5 条评论,欢迎与作者交流。
正在加载评论...