专栏文章
强连通分量 SCC
算法·理论参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @minkrw4t
- 此快照首次捕获于
- 2025/12/02 04:01 3 个月前
- 此快照最后确认于
- 2025/12/02 04:01 3 个月前
定义
-
强连通:有向图中,如果两点可以互相到达,那么他们俩强连通。
-
强连通子图:子图中任意两点连通。
-
强连通分量(Strongly Connected Components,SCC)的定义是:极大强连通子图。
-
若一张有向图的边替换为无向边后可以得到一张连通图,则称原来这张有向图是 弱连通的。
kosaraju 算法
- 以下是下面所用的变量名及其意义:
| 变量名 | 意义 |
|---|---|
| 记录点的遍历情况 | |
| 强连通分量的数量 | |
| 号强连通分量的规模 | |
| 后序及反序 序列 | |
| 原图 | |
| 边反 | |
| 缩点后的入度 | |
| 缩点后的出度 | |
| 缩点后去重的图(可优化) |
第一次DFS
正向图中搜索得到包含所有店的后序遍历
CPP// 正向图中得到后序遍历序列
void dfs1(int u)
{
vis[u] = 1;
for(auto v : g1[u]) // 正向图
if(!vis[v]) dfs1(v);
kos.push_back(u);
}
第二次DFS
将序列反转,依次在反图中进行强连通分量标记
CPP// 把 u 所有能到的未标记点全部标记为同一个强连通分量
void dfs2(int u)
{
scc[u] = scc_cnt;
for(int v : g2[u]) // 反向图
if(scc[v] == 0) dfs2(v);
}
kosaraju 主体
CPPvoid kosaraju()
{
//第一步:遍历正向图所有点,得到后序遍历序列
for(int i=1; i<=n; i++)
if(!vis[i]) dfs1(i);
reverse(kos.begin(), kos.end()); // 反转序列
// 第二步:倒序考虑后序遍历序列,在反图中标记每一个强连通分量
// scc_cnt:强连通分量的数量,顺带作为编号进行标记
for(auto x : kos)
if(scc[x] == 0) ++scc_cnt, dfs2(x);
// 反图中搜索+标记所属强连通分量编号
}
缩点
缩点后变为 DAG,可以进行更多操作。
CPPint in[MAX], out[MAX];
set<int> edge[MAX];
void get_graph()
{
for(int u=1; u<=n; u++)
{
int x = scc[u];
scc_num += 1; // 点信息
for(auto v : g1[u])
{
int y = scc[v];
if(x != y) edge[x].insert(y), in[y] ++, out[x] ++; // 外部边信息
}
}
}
正确性证明
- 强连通的两点,无论先搜后搜,都会被标记为相同值。
- 非强连通的两点,无论先搜后搜,都会被标记为不同值。
- 在 B 搜索前,A 是否已被标记?——无论在第一次遍历时 A 先还是 A 后在第二次遍历标记时永远是 A 先开始标记,那么由于是一个反向图,因此 A 是无法标记 B 的,且后续从 B 标记开始标记的时候,A 已经被标记了,因此 A 和 B 一定不在同个强连通分量里面。
#include<bits/stdc++.h>
using namespace std;
const int MAX = 1e5+5;
vector<int> g1[MAX], g2[MAX], kos;
int vis[MAX], scc[MAX], n, m, scc_cnt=0;
void dfs1(int u)
{
vis[u] = 1;
for(auto v : g1[u])
if(!vis[v]) dfs1(v);
kos.push_back(u);
}
void dfs2(int u)
{
scc[u] = scc_cnt;
for(int v : g2[u])
if(scc[v] == 0) dfs2(v);
}
void kosaraju()
{
for(int i=1; i<=n; i++)
if(!vis[i]) dfs1(i);
reverse(kos.begin(), kos.end());
for(auto x : kos)
if(scc[x] == 0) ++scc_cnt, dfs2(x);
}
int main()
{
cin >> n >> m;
for(int i=1; i<=m; i++)
{
int a, b; cin >> a >> b;
g1[a].push_back(b);
g2[b].push_back(a);
}
kosaraju();
int cnt[MAX]; for(int i=1; i<=n; i++) cnt[scc[i]]++;
int ans = 0;
for(int i=1; i<=scc_cnt; i++)
if(cnt[i] > 1) ans++;
cout << ans;
return 0;
}
Tarjan 算法
场景:强连通分量、割点、割边、点双、边双、圆方树。
DFS 生成树
有向图的 DFS 生成树主要有 种边(不一定全部出现):
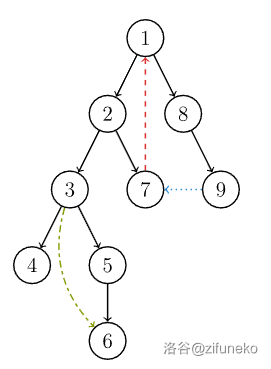
- (树边):示意图中以黑色边表示,每次搜索找到一个还没有访问过的结点的时候就形成了一条树边。
- (反祖边):示意图中以红色边表示(即 ),也被叫做回边,即指向祖先结点的边。
- (横叉边):示意图中以蓝色边表示(即 ),它主要是在搜索的时候遇到了一个已经访问过的结点,但是这个结点 并不是 当前结点的祖先。
- (前向边):示意图中以绿色边表示(即 ),它是在搜索的时候遇到子树中的结点的时候形成的。
过程
Tarjan 算法基于对图进行 深度优先搜索。我们视每个连通分量为搜索树中的一棵子树,在搜索过程中,维护一个栈,每次把搜索树中尚未处理的节点加入栈中。
在 Tarjan 算法中为每个结点 维护了以下几个变量:
- :深度优先搜索遍历时结点 被搜索的次序。
- :在 的子树中能够回溯到的最早的已经在栈中的结点。
一个结点的子树内结点的 都大于该结点的 。从根开始的一条路径上的 严格递增, 严格非降。
按照深度优先搜索算法搜索的次序对图中所有的结点进行搜索,维护每个结点的 与 变量,且让搜索到的结点入栈。每当找到一个强连通元素,就按照该元素包含结点数目让栈中元素出栈。在搜索过程中,对于结点 和与其相邻的结点 ( 不是 的父节点)考虑 种情况:
- 未被访问:继续对 进行深度搜索。在回溯过程中,用 更新 。因为存在从 到 的直接路径,所以 能够回溯到的已经在栈中的结点, 也一定能够回溯到。
- 被访问过,已经在栈中:根据 值的定义,用 更新 。
- 被访问过,已不在栈中:说明 已搜索完毕,其所在连通分量已被处理,所以不用对其做操作。
实现
下面是代码中变量名及其解释:
| 变量名 | 释义 | |
|---|---|---|
| 全局 | ||
| 每个结点的点权(权值)。之后 SCC 缩点时会把每个 SCC 内所有点的点权相加。 | ||
| 原图的邻接表。 | ||
| 缩点之后得到的 DAG 图的邻接表。 | ||
DFS 序编号(访问次序)。当 dfn[u] == 0 时,表示这个点还没被访问过。 | ||
low[u] 表示:从 出发,通过树边和返祖边能到达的最小 值。 | ||
| 全局 DFS 序的计数器。 | ||
| Tarjan算法 的栈,用来存当前 DFS 搜索路径上的点。 栈中元素都是 “已经访问但尚未归属到某个 SCC 的点”。 | ||
| 栈顶指针。 | ||
| 缩点 | ||
| 强连通分量的编号计数器。 | ||
| 这个点属于哪个 SCC,在弹栈时赋值。 | ||
| 每个 SCC 的总点权。在弹栈时,把该 SCC 中所有点的权值累加。 | ||
| 每个 SCC 包含多少个结点。 | ||
| 新图的入度(in-degree) | ||
| 新图的出度(out-degree) | ||
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int MAX = 1e6+5;
int n, m, val[MAX], dfn[MAX], low[MAX]; // low: 能到达的最小dfn序
int scc_cnt, tar_index, scc_id[MAX], scc_val[MAX], scc_num[MAX], tar_stack[MAX], top;
vector<int> tar_edge[MAX], edge[MAX];
void tarjan(int u)
{
low[u] = dfn[u] = ++tar_index;
tar_stack[++top] = u; // 入栈
for(auto v : edge[u])
//树边:新点没有设置 dfn
if(dfn[v] == 0) tarjan(v), low[u] = min(low[u], low[v]);
// 非树边没标记:统一的操作方法
else if(scc_id[v] == 0) low[u] = min(low[u], low[v]);
/*
本质上就是在 DFS 中维护 low 值:
- 树边:继续搜索,然后用儿子的 low 维护。
- 返祖边:用祖先的 dfn 维护。
- 前向边:用子孙的 dfn 维护。
- 横叉边:如果没有被标记,用该点的 dfn 维护。
*/
if(dfn[u] == low[u]) // 找到一个强连通分量的顶点。
{
++scc_cnt; // 强连通分量编号
int x; do
{
x = tar_stack[top--]; // 弹出的点
scc_id[x] = scc_cnt; // 编号
scc_val[scc_cnt] += val[x];
}
while(u != x); // 如果弹出的点不是 u 就继续
}
}
// tarjan 主体
void target()
{
for(int i=1; i<=n; i++)
if(scc_id[i] == 0) tarjan(i);
}
int rd[MAX], cd[MAX];
void get_graph()
{
// 统计每一个强连通分量的结点数量。
for(int i=1; i<=n; i++) scc_num[scc_id[i]]++;
//统计每一个强连通分量的入度和出度并重新构图
for(int u=1; u<=n; u++)
for(auto v : edge[u])
if(scc_id[u] != scc_id[v])
tar_edge[scc_id[u]].push_back(scc_id[v]),
rd[scc_id[v]] ++, cd[scc_id[u]] ++;
}
// 状态:dp[i] 表示所有到 i 终止的路径中,最大点权和
// 转移:dp[u] + val[v] --max-> dp[v]
// 初始:dp[i] = val[i]
int dp[MAX];
void kahn()
{
queue<int> sk;
for(int i=1; i<=scc_cnt; i++)
{
dp[i] = scc_val[i];
if(rd[i] == 0) sk.push(i);
}
while(!sk.empty())
{
int u = sk.front();
sk.pop();
for(auto v : tar_edge[u])
{
dp[v] = max(dp[v], dp[u] + scc_val[v]);
if(--rd[v] == 0) sk.push(v);
}
}
}
void tar_clear()
{
tar_index = scc_cnt = 0;
for(int i=1; i<=n; ++i)
{
scc_id[i] = scc_num[i] = low[i] = dfn[i] = 0;
tar_edge[i].clear();
}
}
signed main()
{
cin >> n >> m;
for(int i=1; i<=n; i++) cin >> val[i];
for(int i=1; i<=m; i++)
{
int u, v; cin >> u >> v;
edge[u].push_back(v);
}
target();
get_graph();
kahn();
int ans=0; for(int i=1; i<=scc_cnt; i++) ans = max(ans, dp[i]);
cout << ans;
return 0;
}
割边
对于一个无向图,如果删掉一条边后图中的连通分量数增加了,则称这条边为桥或者割边。
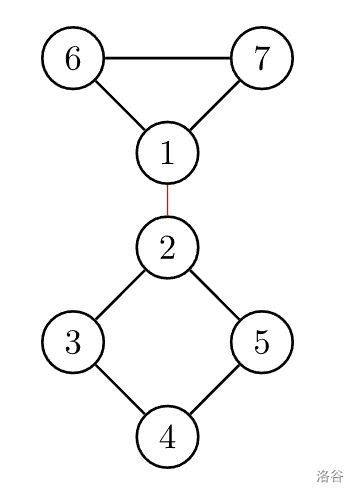
红色的边就是割边。
求解
把无向图看成有向图,发现有三种情况(记 的子节点为 ):
- :是桥, 没有其他路径能到 。
- :不是桥,该边在一个环中。
- :不是桥,该边在一个环中。
模版
【模板】割边
题目描述
给定一个 个点 条边的无向图,求割边数量。
输入格式
第一行两个整数 。
接下来 行,每行两个整数 ,表示一条连接 和 的边。
输出格式
共一行,输出值为割边数量。
in #1
CPP6 7
1 2
2 3
3 1
3 4
4 5
5 6
4 6
out #1
CPP1
说明/提示
对于 的数据,。
CPP#include<bits/stdc++.h>
using namespace std;
const int MAX = 3e5+5;
int n, m, low[MAX], dfn[MAX], tar_index, is_cnt[MAX];
struct Edge {int v, id;};
vector<Edge> edge[MAX];
// e_id 表示来边的编号,防止回搜
void tarjan(int u, int e_id)
{
dfn[u] = low[u] = ++tar_index;
for(auto [v, id] : edge[u])
if(dfn[v] == 0)
{
tarjan(v, id);
low[u] = min(low[u], low[v]);
// 对于每条边,跑完后判断
if(low[v] > dfn[u]) is_cnt[id] = true;
}
else if(e_id != id) low[u] = min(low[u], dfn[v]);
}
void target()
{
for(int i=1; i<=n; i++)
if(!dfn[i]) tarjan(i, 0);
}
int main()
{
cin >> n >> m;
for(int i=1; i<=m; i++)
{
int u, v;
cin >> u >> v;
edge[u].push_back({v, i});
edge[v].push_back({u, i});
}
target();
int ans=0;
for(int i=1; i<=m; i++)
if(is_cnt[i]) ans++;
cout << ans;
return 0;
}
割点
CPP#include<bits/stdc++.h>
using namespace std;
const int MAX = 3e5+5;
int n, m, low[MAX], dfn[MAX], tar_index, is_cut[MAX], cut_num=0;
vector<int> edge[MAX];
void tarjan(int u, int root)
{
dfn[u] = low[u] = ++tar_index;
int son = 0;
for(auto v : edge[u])
if(dfn[v] == 0)
{
son++;
tarjan(v, root);
low[u] = min(low[u], low[v]);
if(low[v] >= dfn[u] && u != root)
cut_num += 1 - is_cut[u],
is_cut[u] = true;
}
else low[u] = min(low[u], dfn[v]);
if(son >= 2 && u == root) cut_num += 1 - is_cut[u], is_cut[u] = true;
}
void target()
{
for(int i=1; i<=n; i++)
if(!dfn[i]) tarjan(i, i);
}
int main()
{
cin >> n >> m;
for(int i=1; i<=m; i++)
{
int u, v;
cin >> u >> v;
edge[u].push_back(v);
edge[v].push_back(u);
}
target();
cout << cut_num << endl;
for(int i=1; i<=m; i++)
if(is_cut[i]) cout << i << ' ';
return 0;
}
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...