专栏文章
浅谈 OI 中的连通性相关算法
算法·理论参与者 4已保存评论 3
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 3 条
- 当前快照
- 1 份
- 快照标识符
- @mipb55m7
- 此快照首次捕获于
- 2025/12/03 09:07 3 个月前
- 此快照最后确认于
- 2025/12/03 09:07 3 个月前
阅读方式:博客园(强烈推荐)
前言
本文旨在深入探讨图论中的强连通分量和双连通分量的求解方法及其理论基础,深入剖析 Tarjan 算法的本质。本文仅讨论求解连通分量的算法而不讨论缩点等引申问题。DFS 和 BFS 作为图论研究中的核心工具,将在本文中频繁涉及。因此,读者在阅读本文之前,应具备对 DFS 算法及其相关性质的扎实理解。
在强连通分量部分,本文将详细介绍经典的 Tarjan 算法,并探讨相对小众但具有独特价值的 Kosaraju 算法。在双连通分量部分,同样讲解 Tarjan 算法,并进一步阐述如何运用 Kosaraju 算法求解边双连通分量。尽管该方法在 OI 界中较少提及,但其算法实现的复杂度并不高于 Tarjan 算法,具有一定的应用价值。
Tarjan 算法在 OI 中已成为解决连通性问题的主流算法,其广泛的应用性和高效性备受青睐。然而,Kosaraju 算法亦具有重要的学习意义。在特定问题场景下,Kosaraju 算法的实现过程更为简洁,能够为问题求解提供更为高效的途径。
在 OI 中,不管是强连通分量,还是双连通分量,通常均是为了缩点(将一个分量缩成一个点),从而使得图变得更有性质。强连通分量缩点后变成 DAG,双连通分量缩点后变成树。在 DAG / 树上做,显然会容易许多。
DFS 生成树
Tarjan 算法的关键便是 DFS 生成树,其内的大部分性质能够帮助我们有效地解决连通性问题,故让我们下来了解 DFS 生成树。DFS 生成树指在对有向图 / 无向图遍历的过程中所生成出的树,接下来将分别对有向图和无向图描述 DFS 生成树。
有向图的 DFS 生成树
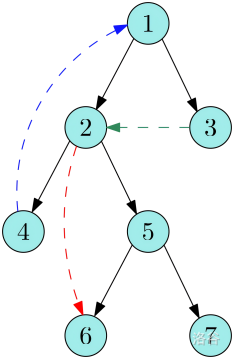
有向图的 DFS 生成树共存在 种边:
- 树边():当 DFS 到 点,向下搜索到还未被访问过的点 时,便形成了一条树边 。通过树边,构建出原图的一棵生成树。示意图中以黑色边表示。
- 反祖边():在生成树中, 点指向祖先节点 的边。示意图中以蓝色边表示。
- 前向边():在生成树中, 点指向 点子树中节点 的边。示意图中以红色边表示。
- 横叉边():在生成树中, 点指向与点 不存在祖先关系的节点 的边。示意图中以绿色边表示。
【性质】 图 为有向无环图当且仅当 DFS 生成树中不存在反祖边,即环是通过反祖边形成的。
【习题】
- 如何通过 DFS 生成树判定有向图是否存在环?要求:时间复杂度为 。
- [HT-043-Rainbow] 美愿时代的恨意
无向图的 DFS 生成树
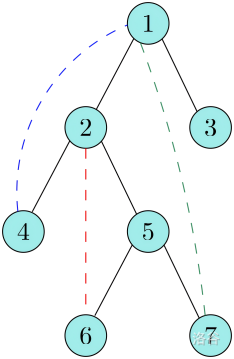
无向图的 DFS 生成树共存在 种边:
- 树边():当 DFS 到 点,向下搜索到还未被访问过的点 时,便形成了一条树边 。通过树边,构建出原图的一棵生成树。示意图中以黑色边表示。
- 后向边():在生成树中, 点连接祖先节点(非父亲节点) 的边。示意图中以红蓝绿边表示。
【思考】 为什么在无向图中没有横叉边呢?
【解答】 假设存在横叉边 ,不失一般性地令 在 DFS 中比 先遍历到。那么,DFS 过程中一定会把 的出边均遍历完,也就是说会通过这条横叉边遍历到 ,于是 应为树边。与假设矛盾,证毕。
【习题】 如何通过 DFS 生成树判定无向图是否存在环?要求:时间复杂度为 。
强连通分量
【定义】
- 强连通:有向图 强连通是指 中任意两个结点连通。
- 强连通分量(Strongly Connected Components,SCC):极大的强连通子图。
Tarjan 算法
考虑 DFS 生成树与强连通分量之间的联系,对于一个强连通分量,其在 DFS 生成树上必然是一棵子树,而这棵子树的根记作 。则有,该子树(强连通分量)内的所有点均无法到达 点的祖先节点。
依此设计算法,若能够求解出每个节点能够到达的深度最浅(或时间戳最小)的祖先节点,那么当且仅当这个节点是节点 本身时,说明 是强连通分量对应子树的根。此时, 点对应的强连通分量中的其余节点,为以 为根的子树中,排除其他强连通分量的节点后所剩余的节点。
可能略微难懂,举例说明:
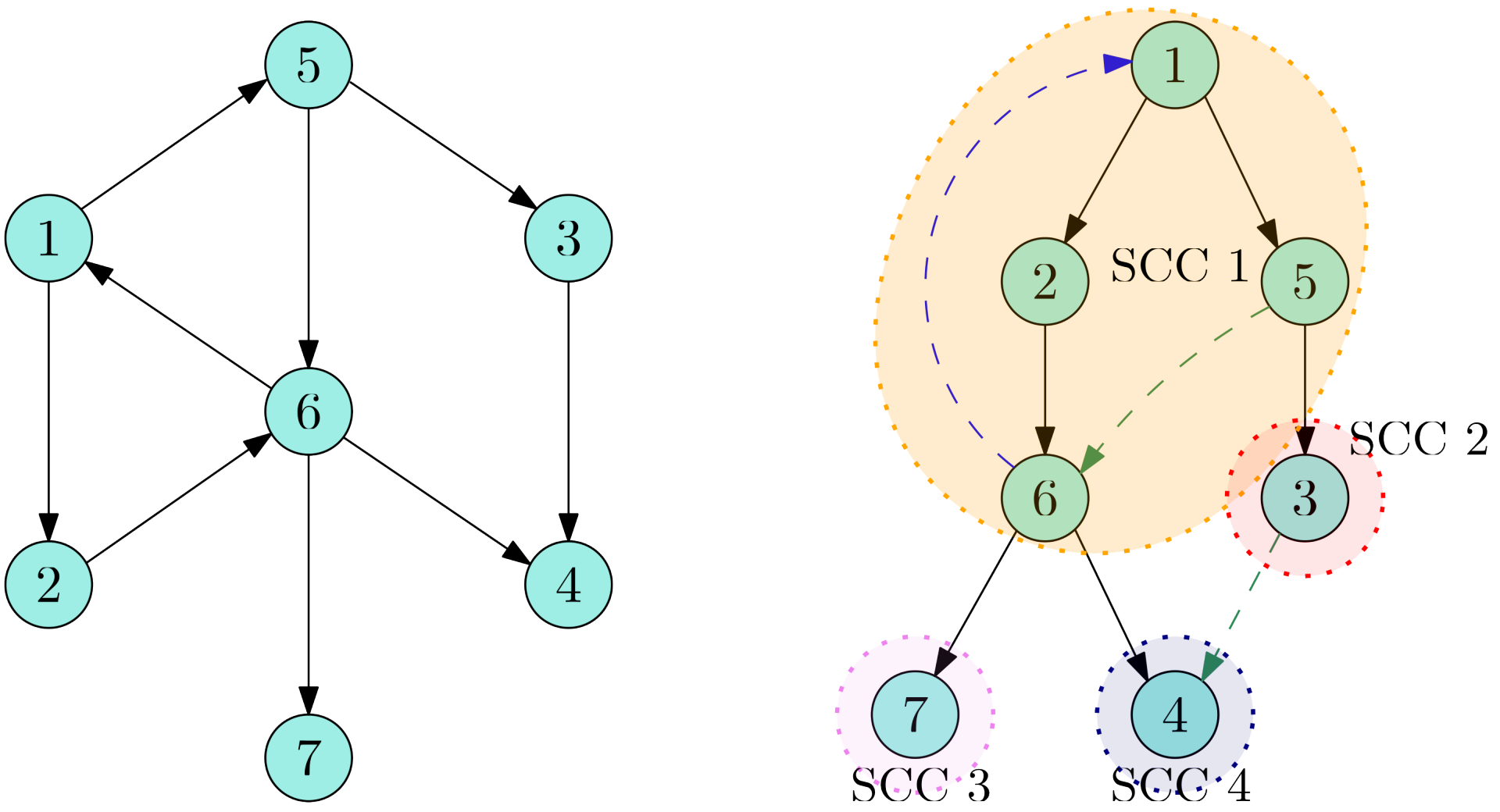
如图橘色、红色、粉色、蓝色圈出的区域分别为 对应的子树,而 分别为这些子树的根节点。每个节点能够到达的深度最浅(或时间戳最小)的祖先节点分别为
不难发现, 节点其祖先节点等于其本身,也就是它们是 SCC 对应子树的根,而其余节点就相当于子树内排除别的 SCC 后剩下的点。比如说, 就相当于 节点子树内(也就是整棵树),排除其余 SCC()的节点()后,剩下的节点 。这样,就可以求解每个 SCC 内的点了。
于是,接下来的问题便是如何快速找到每个节点能够到达的深度最浅(或时间戳最小)的祖先节点,为此定义 数组和 数组:
- :DFS 访问到 点的时间戳。
- : 点所能走到的 最小的还在栈中的节点的时间戳(深度等等均可)。
注意到,在 数组的定义中涉及到栈,栈是干什么的呢?栈就是为了排除 子树内其余的 SCC 的节点,也是为了保证其对应的节点与 存在祖先关系,不会通过横叉边跑到别的子树中去。
而 的维护只需在 DFS 的过程中,类似树形 DP 的方式去维护即可:
- 点未被访问过(树边):
DFS(v)并 。 - 点在栈中:。
每当计算出 的值后(也就是最终
DFS(u) 结束的时候),判断 是否为某个 SCC 对应子树的根节点。若是,则将栈中的节点依此弹出直至 ,注意不能全部弹出因为存在 的祖先节点。而弹出的这些节点,便是这个 SCC 内部的点。至此,我们知晓如何通过 Tarjan 来求解 SCC。CPP
void tarjan(int u) {
dfn[u] = low[u] = ++ tot;
stk[ ++ top] = u, in_stk[u] = true;
for (auto v : g[u])
if (!dfn[v]) {
tarjan(v);
low[u] = min(low[u], low[v]);
} else if (in_stk[v])
low[u] = min(low[u], low[v]);
if (dfn[u] == low[u]) {
int w;
do {
w = stk[top -- ];
in_stk[w] = false;
/*
根据不同的题目,维护不同的信息。
*/
} while (w != u);
}
}
Kosaraju 算法
原图的汇是反图的源。
Kosaraju 的思想与 Tarjan 算法截然不同,Kosaraju 算法并没有用到 DFS 生成树,只是简单的 DFS 就解决了复杂的 SCC 问题。所以,笔者认为 Kosaraju 算法是非常优美的!
如 所言,强连通分量缩点后是一张 DAG(有向无环图),那么如果能够找到出度为 的 SCC 内部的任意一个点,那么再跑 DFS 所经过的点便是这个 SCC 内部的点,因为其出度为 无法到达其他 SCC 而且 SCC 内部任意两个点连通所以肯定能将这个 SCC 遍历完。将某个出度为 的 SCC 处理完后,将其以及指向它的边删除并继续操作,便能找到所有 SCC。
原图的汇是反图的源,这其实是反图上拓扑排序的过程,如果能得到反图的拓扑序,则按照该拓扑序在原图上不断 DFS,每次经过的点便是一个 SCC,注意不能遍历到之前 SCC 的点。于是,我们只需要得到反图的拓扑序即可,而 DFS 离开的顺序刚好是倒着的拓扑序,所以只需要在反图上跑一遍 DFS 并将离开的点的顺序记录出,并反着在原图上依此跑 DFS 即可。
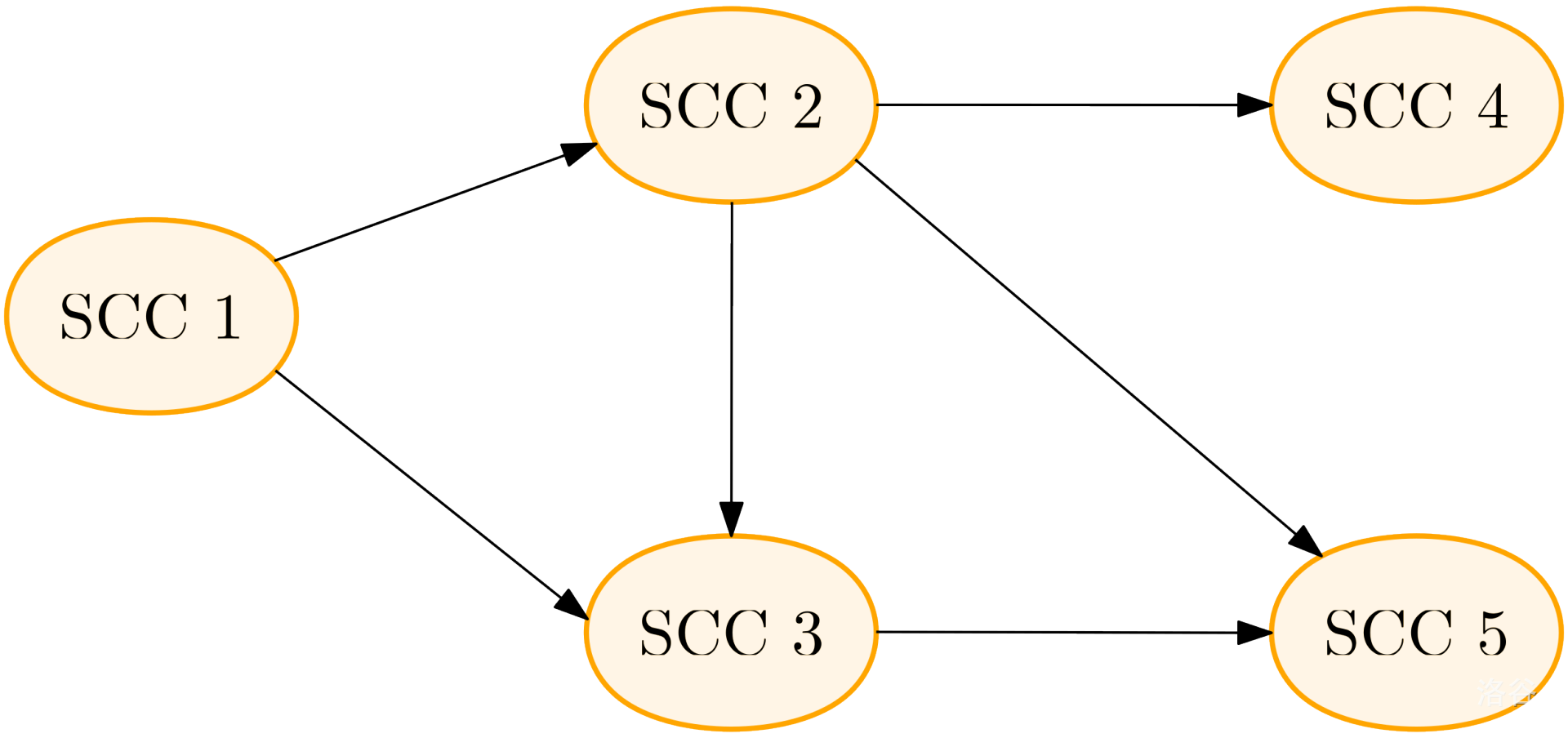
如图,上来从 中的任意一个点开始跑 DFS,由于强连通分量内的任意两点连通,故必然能将 内部的点遍历完,而且 不存在出边,所以只能遍历 内部的点。 同理。接下来,遍历 ,虽然其能遍历到 ,但是由于已经遍历过了所以仍然只能在 中。以此类推……
【习题】 如果先在原图跑出拓扑序,再在反图上跑对吗?如果对,说明理由;否则,给出反例。
CPP
void dfs1(int u) {
vis[u] = 1;
for (auto v : rg[u])
if (!vis[v]) dfs1(v);
ord[ ++ tot] = u;
}
void dfs2(int u) {
vis[u] = 1;
for (auto v : g[u])
if (!vis[v]) dfs2(v);
}
int main() {
// 读入,g 为原图,rg 为反图。
for (int i = 1; i <= n; i ++)
if (!vis[i]) dfs1(i);
memset(vis, 0, sizeof vis);
for (int i = n; i >= 1; i --)
if (!vis[ord[i]]) {
dfs2(ord[i]);
/*
根据不同题目维护不同信息
*/
}
}
双连通分量
【定义】
- 边双连通:对于两个点 和 ,如果无论删去哪条边都不能使得它们不连通,就说 和 边双连通。
- 点双联通:对于两个点 和 ,如果无论删去哪个点都不能使得它们不连通,就说 和 点双连通。
- 边双连通分量:对于一个无向图中的 极大 边双连通的子图,我们称这个子图为一个 边双连通分量。
- 点双连通分量:对于一个无向图中的 极大 点双连通的子图,我们称这个子图为一个 点双连通分量。
双连通分量的 Tarjan 算法与强连通分量原理是一样的,所以大家可以先尝试自行思考,再往下阅读。
边双连通分量
边双连通分量和强连通分量是相通的。
Tarjan 算法
与强连通分量类似,还是维护 和 两个数组。只不过维护略有不同,甚至简单,因为无向图上没有横叉边。所以,我们不需要维护每个点是否在栈中,因为在维护 的时候,如果不是树边,则一定是后向边,均与 有祖先关系,不会导致维护到其余子树中。
接下来的部分均与强连通分量一致,有一个注意点是由于是无向边,一条树边 ,在 DFS 到 的时候,仍会遍历 ,但不应该用 来更新 。所以,需要在 DFS 的时候,维护父亲节点的边,遍历的时候不遍历该边。
故,在写边双连通分量的时候,推荐使用链式前向星建图,这样容易维护父亲节点的边,因为每条边都有自己的编号。
CPP
void tarjan(int u, int fa) {
dfn[u] = low[u] = ++ tot;
stk[ ++ top] = u;
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (i == fa) continue;
if (!dfn[v]) {
tarjan(v, i ^ 1);
low[u] = min(low[u], low[v]);
} else low[u] = min(low[u], low[v]);
}
if (low[u] == dfn[u]) {
int w;
do {
w = stk[top -- ];
/*
根据不同的题目,维护不同的信息。
*/
} while (w != u);
}
}
Kosaraju 算法
边双连通分量亦可 Kosaraju!
还记着,开头语说的边双连通分量和强连通分量是相通的?这是因为在通过 DFS 给无向图定向(树边向下,后向边向上)后,变成有向图,则每个强连通分量便是原来的边双连通分量!是不是很神奇?
实际上,原理是这样的。给无向图通过 DFS 定向后,原来每个环,现在仍然是有向环,而边双连通分量实际上就是由若干环拼接在一起的,而现在变成了若干个有向环拼接在一起,仍然是一个强连通分量(我相信没有人喜欢看枯燥无味的证明的,所以这里就不放,其实是不会证)。举个例子:
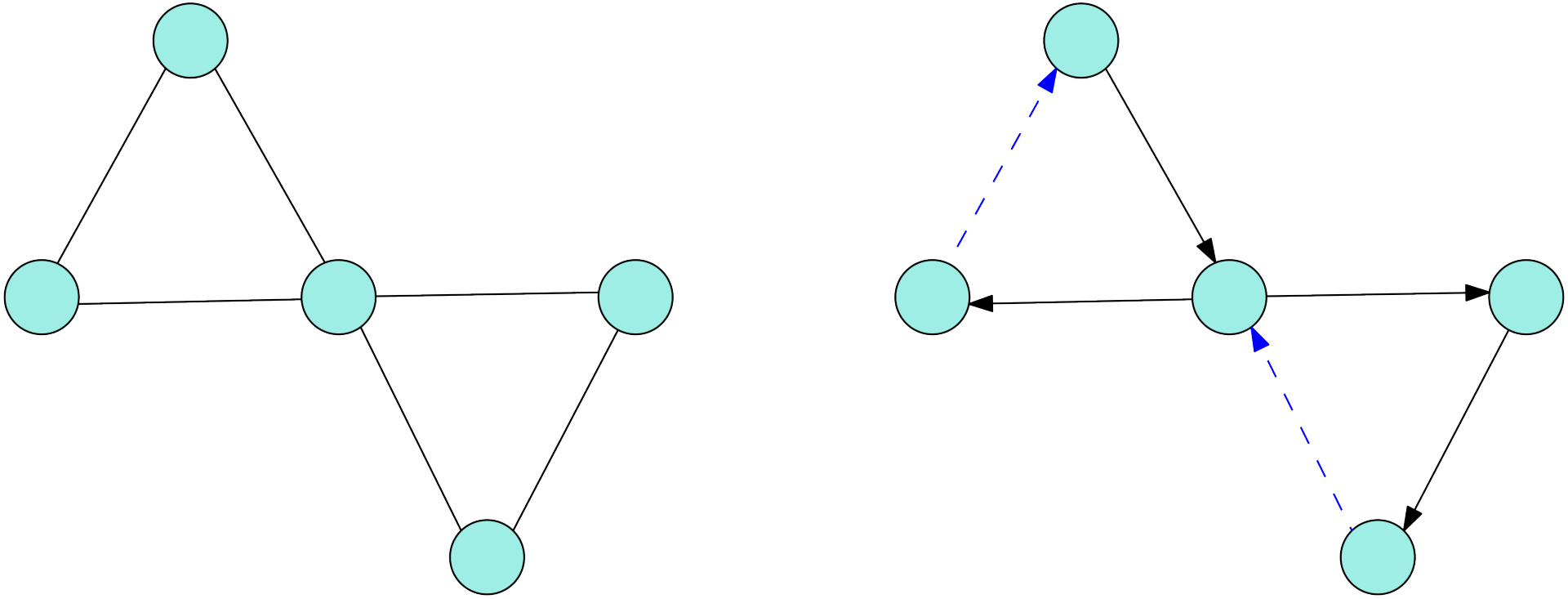
左图为边双连通图,右图为 DFS 定向后的图,蓝色虚线边为后向边,黑色边为树边。不难发现,这样定向后,最终是强连通图。
于是,考虑如何实现定向操作,笔者想到的实现方式是用深度实现,如果边 , 的深度小于等于 的深度,那么就说明这条边的方向就是现在的方向。这里,如果是树边,那么在 DFS 的过程中, 的深度还未计算,所以仍小于等于 的深度,并无矛盾。
综上,使用链式前向星建图,第一次 DFS 的过程中标记哪些边使用了,第二次 DFS 在反图上跑一遍 DFS 即可。
实际上,这里只是将边双连通分量的求解转化为强连通分量的求解,并不是真正意义上的边双连通分量 Kosaraju。只是由于 Kosaraju 本身有一个 DFS 是在预处理,而定向可以同时进行,所以显得比较般配。但实际上,如果你先定向,然后再跑 Tarjan,只要不嫌麻烦,也没问题。
CPP
void dfs1(int u, int fa) {
vis[u] = 1;
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (dep[v] <= dep[u] && fa != i) st[i] = 1;
if (!vis[v]) {
dep[v] = dep[u] + 1;
dfs1(v, i ^ 1);
}
}
ord[ ++ tot] = u;
}
void dfs2(int u) {
vis[u] = 1;
for (int i = h[u]; ~i; i = ne[i])
if (!vis[e[i]] && !st[i]) dfs2(e[i]);
}
int main() {
for (int i = 1; i <= n; i ++)
if (!vis[i]) dfs1(i, -1);
memset(vis, 0, sizeof vis);
for (int i = n; i >= 1; i --)
if (!vis[ord[i]]) {
dfs2(ord[i]);
/*
根据不同的题目,维护不同的信息。
*/
}
}
点双连通分量(Tarjan 算法)
点双连通分量会比较反常,前文所述的连通分量都是互不相交地划分了所有点,而割点却可能出现在多个点双连通分量中。考虑如何求解割点,当知道点 为割点后,则其每个儿子节点均为一个点双连通分量,也就很好找出每个点双连通分量了。
如何判断点 为割点呢?考虑树边 ,当 DFS 完 后,如果 ,则说明点 为割点,因为割掉后 节点将于 上面的节点不连通。不难发现, 是根的时候需要特判,如果根只有一个儿子,则不是割点;否则是割点。
那如何求点双连通分量呢?只需要当 的时候,通过栈的方式将分量内部的点全部取出。这时候,就不需要特判根了,因为我们不需要知道根是否是割点,只是将根放入下面的分量中而已。但是,需要特判独立点,因为这时候没有儿子无法放入分量中,需要手动创建一个分量将其放入。
CPP
void tarjan(int u, int fa) {
dfn[u] = low[u] = ++ tot;
stk[ ++ top] = u;
bool single = true;
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
single = false;
if (i == fa) continue;
if (!dfn[v]) {
tarjan(v, i ^ 1);
low[u] = min(low[u], low[v]);
if (low[v] >= dfn[u]) {
int w;
do {
w = stk[top -- ];
/*
根据不同的题目,维护不同的信息。
*/
} while (w != v);
// 注意:u 也在分量中
}
} else low[u] = min(low[u], dfn[v]);
}
if (single) res.push_back({u});
}
结语
至此,我们讨论完了 OI 中的强联通分量和双连通分量的算法,讲述了 Tarjan 算法究竟是在干什么?为什么要这么干?以及 Kosaraju 算法和边双连通分量的 Kosaraju 算法(本质上是将边双转变为强连通分量)。
如果您认为文章哪里存在问题或理解不当,欢迎指出,感谢您的阅读。
相关推荐
评论
共 3 条评论,欢迎与作者交流。
正在加载评论...