专栏文章
浅谈信息论
算法·理论参与者 45已保存评论 51
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 51 条
- 当前快照
- 1 份
- 快照标识符
- @mhz5sy3u
- 此快照首次捕获于
- 2025/11/15 01:56 3 个月前
- 此快照最后确认于
- 2025/11/29 05:24 3 个月前
信息论是运用概率论与数理统计的方法研究信息、信息熵、通信系统、数据传输、密码学、数据压缩等问题的应用数学学科。
上面一段话节选自百度百科,可以不用管它。本文将简单介绍信息论,并结合一些好玩的例子加深大家对信息论的理解与应用。
本文主要起到普及作用,让大家对于信息论有一个简单的认识。
笔者才疏学浅,且为方便读者理解,文章并不是十分专业,部分缺乏严谨性,若有严重错误,欢迎指出。
引子
1A2B游戏相信很多人都知道,但是是否有人考虑过解决该游戏的最佳策略应该如何分析呢?下面将以该游戏的最优策略为例子介绍信息论的实际应用。
介绍
一种常见的数学游戏,规则很简单,极好上手,它的数学概念主要为排列组合,共有5040种可能性供对手猜测,也因为排列组合的复杂多变性,使得这种游戏虽然简单却不单调,十分耐玩。
规则
由两人完成,分为出题者和猜测者,出题者随机想出一个各位数字互不相同的四位数 ( 允许最高位为0,即可以有前导零,如0123 ) 。猜测者每次询问一个各位数字互不相同的数 ,出题者将 和 进行对比,令 为 和 中数字正确且位置正确的数字的个数, 为 和 中数字正确但位置不正确的数字的个数,以 的形式返回给猜测者,猜测者需要根据出题者所给的信息,确定四位数 。
举例来说,若出题者想的数字是1234,猜测者询问的数字为5283,其中2数字正确且位置正确,3数字正确但位置错误,所以出题者返回 。若出题者返回 时,即说明猜测者猜中了,游戏结束。
分析
显然,我们的目的不仅仅是猜中出题者给出的数字,我们还要在尽量少的步数内猜中,那么我们就想到,对于每次猜测,是否有一种最优策略?
考虑每次询问的目的是什么?发现是获得更多信息,那么我们在一次询问中获得最多的信息呢?只要我们每次询问的数,都是能询问的数中获得信息最多的一个,那么显然这是最优策略,但是,要如何找到能询问的数中能获得信息最多的呢?别急,且看下一部分。
信息量的概念
信息量是信息有多少的度量。在信息论中,认为信源输出的消息是随机的。即在未收到消息之前,是不能肯定信源到底发送什么样的消息。而通信的目的也就是要使接收者在接收到消息后,尽可能多的解除接收者对信源所存在的疑义(不定度),因此这个被解除的不定度实际上就是在通信中所要传送的信息量。 bit 就有 种可能。
上面这段话还是节选自百度百科,用人话来说,信息就是消除不确定性,比如本来一件事你知道有哪些可能发生,现在别人告诉你发生了其中的某一件事,不确定性就消除了,别人告诉你这件事就叫做信息。
比如,你知道珂朵莉现在可能在吃饭,睡觉,聊天,但是你不确定她到底在做什么,这时告诉了你,她现在在睡觉,这就是信息。
为了方便起见,我们使用bit作为信息量的单位,1bit即为1个为0或1的数字,所以,1bit的信息,有两种可能,1或0。所以,1bit可以看成1个二进制数。下面举一些例子:
-
一个 的数字所含的信息量为1 bit;
-
一个 的数字所含的信息量为2 bit;
-
一个 的数字所含的信息量为10 bit;
-
轻小说《末日时在做什么?有没有空?可以来拯救吗?》第一卷约有77748个汉字,所含的信息量为1243968 bit;
-
动漫《末日时在做什么?有没有空?可以来拯救吗?》第一集长度为24.5分钟,大小为297MB,所含的信息量为2491416576 bit。
信息量的计算
珂朵莉抛了一枚硬币,威廉知道现在硬币可能有两种状态(假设硬币不会立着),正面或反面,这时珂朵莉告诉威廉硬币是正面,这件事的信息量是多少呢?不难理解,信息量是1bit,我们可以用1来表示正面,0来表示反面。
珂朵莉今天有四分之一的概率学习,二分之一的概率打游戏,四分之一的概率看番,现在她告诉你,她今天在看番,那么珂朵莉告诉你的信息量有多少呢?信息量是2bit。
那如果珂朵莉告诉你,她今天在打游戏,那么这件事的信息量有多少呢?信息量是1bit。
为什么告诉我两件不同的事,信息量会不一样?因为一件事信息量与其发生概率有关。概率越小的事件传递的信息量越大,反之概率越大的事件所传递的信息量越少。
比如,若珂朵莉今天学习,可以用2bit表示为11,若她今天在打游戏,可以用1bit表示为0,若她今天看番,可以用2bit表示为10。
同时我们可以反过来考虑,若珂朵莉告诉你,她今天没有打游戏,那么这件事的信息量为多少?相信所有人都知道是1bit。
那我们再来看一种情况,珂朵莉掷了一枚普通的六面骰子,你知道点数共有6种可能,现在珂朵莉告诉你点数,这件事信息量有多少?请读者停下来思考一下。若你独立计算出了答案,恭喜你,你差不多已经独立推导出了信息量的计算公式,这件事的信息量为 。本文之后的 均默认为以2为底的对数函数 。
经过上面这些例子,于是我们自然而然想到,信息量的计算公式为:
或者写为:
其中, 是信息量,单位为bit, 是事件发生的概率。
信息熵是在结果出来之前,对于一个事件所传递的信息量的期望。期望通俗来讲,就是对于一个随机事件,我们进行很多很多次,其结果的平均值就是期望。稍微形式化一点来讲,是一个事件所有可能的结果乘以其概率的总和。
由数学期望的公式及信息量的计算公式,我们推出信息熵的计算公式:
其中, 是信息熵, 是事件 发生的概率。 是求和符号,表示将所有后面出现的东西加起来,比如 。在不引起混淆的情况下省略上下界。
应用:1A2B游戏
信息论是一门应用学科,所以我们可以直接把信息论拿来用,让我们回到开头的问题:在最少的步数内解决1A2B问题。
考虑对于每一次询问,我们都要获得最多的信息,消除不确定性。答案一开始共有5040种可能(因为各位数字不能相同),那如果直接告诉你答案,这个信息量是多少?不错,是 bit ,所以我们只要收集到12.3bit的信息,答案就确定了。
对于每一次的询问及相应的回答,我们都可以计算出这有多少信息量,如询问1234,若回答为0A1B,那么在原来有5040种可能的答案中,只剩下1440种答案是可能的,若为其它的答案,则回答不为0A1B。所以我们询问1234,回答为0A1B,所获得的信息量:
好,那我们接下来考虑,如果询问1234,期望获得的信息量为多少?这时我们就需要计算该询问的信息熵,我们枚举所有可能的回答,计算每种回答发生的概率,设回答 发生的概率为 ,那么询问X的信息熵:
需要注意的是,若回答 发生的概率为0,则我们不需要计算该回答对于信息熵的贡献。
所以,我们可以简单计算一下,在第一次询问1234所获得的信息熵,即期望获得的信息量为2.77bit,在该次询问过后,我们需要去掉5440种可能的答案中,不符合该情况的答案,剩下可能的答案的期望数量为:
相信现在大家都知道最优策略了,总结一下。
-
枚举当前可能的解中,询问哪个解得到的期望信息量最大
-
根据询问及其回答,将不可能的解去掉,留下可能的解
-
重复上面两步,直到可能的解只剩下一种,此时询问即为答案
那么我们来看下这个最优策略的效率如何,笔者写了一个程序进行模拟,为了对照,还有另一个朴素程序,朴素程序采取的策略为:
-
在当前可能的解中,等概率选取一个进行询问
-
根据询问及其回答,将不可能的解去掉,留下可能的解
-
重复上面两步,直到可能的解只剩下一种,此时询问即为答案
以下是朴素程序与信息论程序解决效率的比较。
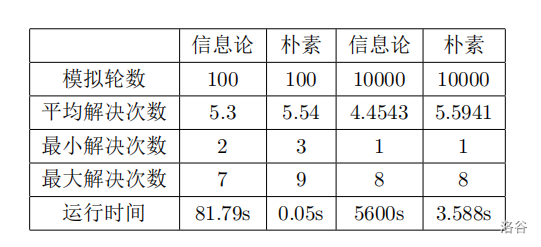
可以看出,信息论程序的解决次数比朴素程序的优秀很多,但是运行时间远远慢于朴素程序,原因是信息论最优策略需要枚举所有可能的解以及对应的回答计算信息熵。
附:1A2B信息论模拟代码
CPP#include<bits/stdc++.h>
using namespace std;
inline int rd(){
int f=1,s=0;char c=getchar();
while(c<'0'||c>'9'){if(c=='-')f=-1;c=getchar();}
while(c<='9'&&c>='0'){s=(s<<3)+(s<<1)+(c^48);c=getchar();}
return s*f;
}
const double eps = 1e-7;
int X,ans[10];
bool c[10000];
bitset<10000>s;
const int N = 100;
int minn=0x7fffffff,maxx=-0x7fffffff;
struct node{
int num;
double E;
}f[10000];
bool cmp_E(const node& x,const node& y){
return (abs(x.E-y.E)<eps)?(x.num<y.num):(x.E>y.E);
}
double I(double x){
return -log2(x);
}
inline void print(int *x){
for(int i=1;i<=4;++i)
printf("%d",x[i]);
printf(" ");
return ;
}
inline void get(int *x,int n){
x[1]=n/1000; n-=1000*x[1];
x[2]=n/100; n-=100*x[2];
x[3]=n/10; n-=10*x[3];
x[4]=n;
return;
}
inline void init(){
int x[10];
for(int i=0;i<=9999;++i){
get(x,i);
s[i]=1;c[i]=0;
for(int j=1;j<=4;++j)
for(int k=1;k<=4;++k)
if(j!=k&&x[j]==x[k])c[i]=1,s[i]=0;
}
return;
}
bitset<10000> ask(int x[],int a,int b){
bitset<10000> t;
t.reset();
int d[10],sa,sb;
bool v[12];
for(int i=0;i<=9;++i)
v[i]=0;
for(int i=1;i<=4;++i)
v[x[i]]=1;
for(int i=0;i<=9999;++i){
get(d,i);
sa=0,sb=0;
for(int j=1;j<=4;++j)
if(d[j]==x[j])++sa;
sb=v[d[1]]+v[d[2]]+v[d[3]]+v[d[4]]-sa;
if(sa==a&&sb==b)t[i]=1;
}
return t;
}
void find(int *x){
int z[5],cnt=0;
double sum=s.count(),p,res,e;
bitset<10000> t;
for(int i=0;i<=9999;++i){
if(c[i]==1||s[i]==0)continue;
e=0;
get(z,i);
for(int j=0;j<=4;++j){
for(int k=0;k<=4-j;++k){
t=ask(z,j,k);
t=s&t;
res=t.count();
if(res==0)continue;
p=res/sum;
e+=I(p)*p;
}
}
++cnt;
f[cnt].num=i;
f[cnt].E=e;
}
sort(f+1,f+1+cnt,cmp_E);
get(x,f[1].num);
return;
}
inline void result(int *x,int &a,int &b){
bool v[12];
for(int i=0;i<=9;++i)
v[i]=0;
for(int i=1;i<=4;++i)
v[ans[i]]=1;
int sa=0,sb=0;
for(int i=1;i<=4;++i)
if(ans[i]==x[i])++sa;
sb=v[x[1]]+v[x[2]]+v[x[3]]+v[x[4]]-sa;
a=sa,b=sb;
return;
}
void rnd(){
mt19937 myrand(time(0));
int p;
bool vis[12];
memset(vis,0,sizeof(vis));
for(int j=1;j<=4;++j){
p=myrand()%10;
while(vis[p])
p=myrand()%10;
ans[j]=p;vis[p]=1;
}
}
int round(){
init();
int x[5];
int a,b,cnt=0;
while(true){
if(!cnt) get(x,123);
else find(x);
++cnt;
result(x,a,b);
if(a==4)return cnt;
s=s&ask(x,a,b);
}
return cnt;
}
int main(){
double sum=0;
for(int i=1;i<=N;++i){
rnd();
int k=round();
minn=min(k,minn);
maxx=max(k,maxx);
sum+=k;
}
sum=sum/N;
cout<<sum<<endl<<maxx<<endl<<minn;
return 0;
}
其实这个代码还是有一定小问题的,我计算出期望信息量并不够准确,因为进行一次询问能得到的信息量,严格来说并不就是单纯对可能答案减少量的计算,而是需要考虑到,剩下的每个答案询问之后得到的信息熵的期望。
也就是说,我第一步说的“考虑对于每一次询问,我们都要获得最多的信息”,不一定是正确的,因为这一步获得最多的信息,并不代表之后获得的信息也是最多的,这个决策方式并不总是满足贪心算法的要求的。
举例来讲,就是说,询问某个答案 ,可能这次信息量得到的并不多,但是再询问一次,期望信息量得到的就会非常多;询问某个答案 ,这一次得到的信息量非常多,但是再询问一次,期望得到的就不多了。
那么,当询问答案 得到的信息量,与之后再询问一次得到的期望信息量之和,比询问 ,与之后再询问一次得到的期望信息量之和更多时,我们选择询问 ,就会更优。
而剩下的答案询问之后减少的信息量的期望,又依赖于再下一次的询问,所以计算次数会多很多。
因此,受实现效率的影响,我并没有严格的计算出期望信息量。不过,在这一问题,我们可以通过预处理所有情况的方式,计算出所有可能的信息量,这样就可以较快的回答每一个询问了。
总结
信息论是一个很实用的东西,在很多方面都有巨大的用处,希望本文能让读者对于信息论有一个初步的认识。
练习:P8079
有问题直接私信我,不要在博客下面评论,我没法回复。
相关推荐
评论
共 51 条评论,欢迎与作者交流。
正在加载评论...