专栏文章
P2879 [USACO07JAN] Tallest Cow S 题解
P2879题解参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @miqm95o7
- 此快照首次捕获于
- 2025/12/04 07:06 3 个月前
- 此快照最后确认于
- 2025/12/04 07:06 3 个月前
看了一遍题解区,发现并没有详细讲明为什么区间减一正确的题解,特发题解讲解。
题目简析
给定一个长度为 的整数数组 ,给出一个最大值 (由样例答案可知最大值位置不唯一),接下来给定 个关系 ,对 有以下限制:
求 的最大值,保证存在满足所有关系的 。
"线段"树建模
我们可以将 当作有向线段理解,样例画出来的图是这样的:
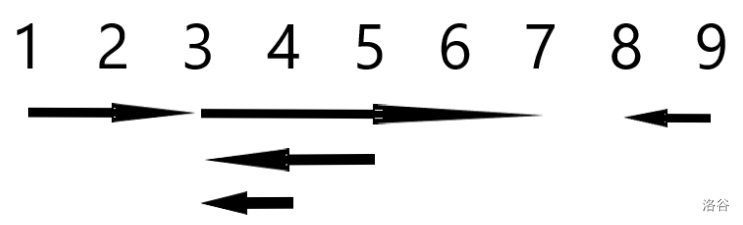
上面的图看起来隐约存在一个"线段"树结构:如果我们再抽象出一个虚拟的覆盖整个 的"全集"线段,那么我们能建出一棵树,满足以下条件:
- 一个线段的子线段都被自己包含。
- 一个线段的所有子线段不交(这里将只有一个端点相交也视为不交)。
不过真的能对所有关系都建出这样的树吗?
It is guaranteed that it is possible to satisfy all the constraints.(数据保证有解)
以上信息是保证这棵树存在的关键,这就是前面对"保证存在满足所有关系的 "加粗的原因。
定理 I:所有有向线段要么互相包含,要么不交
证明:假设存在不满足 定理 I 的两个有向线段,即它们既不存在包含关系,也相交。
不失一般性,不考虑它们的方向,设这两个线段为 ,即使关系不考虑方向也有以下性质:
不失一般性,不考虑它们的方向,设这两个线段为 ,即使关系不考虑方向也有以下性质:
推出矛盾,因此假设不成立,定理 I成立。
在定理 I的条件下,我们通过实现
insert 方法来证明这棵树的存在性,从"全集"线段开始递归,insert 的实现如下:- 如果待插入线段与当前递归线段重合,直接退出。
- 查找待插入线段是否被某个子线段包含,如果是则进入这个子线段递归
- 否则根据定理 I,待插入线段与所有子线段都不交,直接插入到当前递归线段下。
树上求解
显然关系的先后不影响答案,我们在得到的树上用 DFS 逐个考虑每个关系求解答案。
注意我们先计算线段的贡献再进入子线段,类似先序遍历。
先考虑"全集"线段的子线段,容易发现它们的端点和它们未覆盖的点的最大值均为 ,而线段内部的点(不含端点)最大值被限制为 ,即线段内部的点的最大值要 ,如图所示:
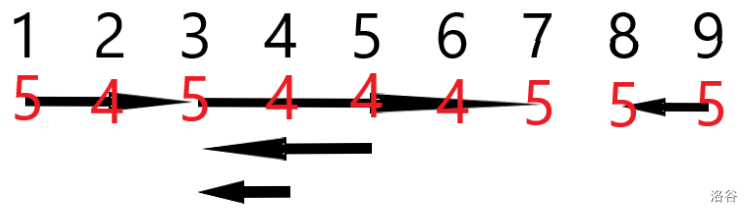
值得注意的是,如果存在重合的线段,不能连续两次 ,这就是为什么
insert 时要排除重合的线段。考虑下一层的线段前,先放送一个定理:
定理 II:DFS 递归求解过程中,当前递归线段内部的点的最大值相等
例如,递归到上面的关系 后,内部 位置上的最大值相等,均为 。
显然,进入子线段后依然保留 定理 II 成立。
根据 定理 II,考虑子线段时,一定有子线段中间的点的最大值等于至少一个端点的最大值,因此处理它的贡献时仍然将中间的点的最大值 。
如果端点涉及父线段的端点呢?这并不影响子线段中间要 ,而且由于一定有解,因此只会出现这些情况:

将图中的两个子有向线段反向会导致无解,而如图所示的情况显然不会导致子有向线段的起点的最大值减小。
综上,我们只需要先令每个位置的最大值均为 ,然后对每个不同的线段内部的点区间 即可,不需要真的建这棵树。由于只需要输出答案一次,用差分维护即可,总复杂度 。
去重
需要注意的是, 应该被视为相同的线段,因此输入时先有序化再判重。
本题去重可以用以下方法:
- 哈希法,可以手写哈希,
std::unordered_set,std::unordered_map。 - 平衡树,可以
std::set,std::map,应该不会有人这题手写平衡树吧。 - 直接写一个 的桶,如果定义为单字节变量,需要约
95.37MB内存,本题够用。但 POJ 上的内存限制为64MB,为了进一步优化,我们可以采用单比特压缩,std::vector<bool>, std::bitset<N>均可,详见代码。 - 离线+排序+去重,常见于离散化操作,这里不展开叙述。
拓展
上面对区间减的正确性分析基于一定有解的前提,如果不保证有解,要判定解是否存在,似乎只能用 SPFA 判断负环+倍增法优化建图?其实并不需要。
假设有解,仍然采用上面的算法跑出答案,然后检查是否满足所有关系和 。
" 之间的所有奶牛的高度都比 小" 等价转换为 " 之间的最高奶牛的高度比 小",用 RMQ 验证即可。
- 如果满足所有关系,那么显然有解(废话)。
- 反之,如果不满足所有关系,那么一定无解,因为我们的算法在有解的情况得出的答案一定符合所有关系和 。
本题数据极弱,许多平方暴力算法最慢点也跑不过
50ms,卡平方数据见 https://www.luogu.com.cn/discuss/1030470 ,尽管对本题的数据范围来说以上数据并不能真的卡平方。代码
CPP#include <cstdio>
#include <cstring>
#include <bitset>
using namespace std;
#ifdef ONLINE_JUDGE
#define getchar() getchar_unlocked()
#endif
inline int read(){
int ch = getchar();
while(ch<48||ch>57) ch = getchar();
int x = 0;
while(48<=ch&&ch<=57){
x = (x<<3)+(x<<1)+(ch^48);
ch = getchar();
}
return x;
}
int N, I, H, R;
int ans[10001]; // 最大值
bitset<100000000> mp; // bitset 判重
int main(){
N = read(); I = read(); H = read(); R = read();
// 注意如何初始化差分后的 ans 数组
ans[0] = H;
memset(ans+1, 0, N<<2);
while(R--){
int a = read(), b = read();
if(a>b) swap(a, b); // 有序化
int id = a*10000+b-10001; // 映射为 0~99999999
if(!mp[id]){
// 差分修改 [a+1, b-1]
--ans[a+1];
++ans[b];
mp[id] = true;
}
}
for(int i=1; i<=N; ++i){
printf("%d\n", ans[i] += ans[i-1]);
}
return 0;
}
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...