专栏文章
CSP-J 2023题解
题解参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @miq4jhqp
- 此快照首次捕获于
- 2025/12/03 22:50 3 个月前
- 此快照最后确认于
- 2025/12/03 22:50 3 个月前
T1
90 分做法:
与经典问题 “约瑟夫问题” 类似,我们可以对约瑟夫问题的背景稍加改动,即可模拟从第 ~个苹果中反复拿取苹果的过程,即:
- 每一轮报数从剩余的最左边的人开始;
- 每一轮报数从 开始,若报数除以 的余数为 ,则出列。
我们可以用布尔数组 表示第 个苹果是否已被拿走,若已经被拿走,则 。代码实现时,可以使用二重循环,外层循环使拿取苹果过程重复进行,内层循环依次遍历第 ~ 个苹果,当且仅当 为 时,才考虑将苹果计入 “报数” 中,如果报数模 为 ,则将第 个苹果拿走,对应地,。
此方法需要开一个大小至少为 的数组,对于前 个数据点,, 空间足够,但最后一个数据点,空间限制,故期望得分90分。
100分做法:
先考虑第一问: 个苹果拿完需要多少天? 我们可以从 较小的情形入手,以输入样例的 为例,第一轮会拿走第 个苹果。此时,我们可以对样例做突然调整:如果 ,那么第一轮还会拿走几个苹果呢?,不难发现:
- n = 9 时,仍然只拿走第 1、4、7 个苹果,共 3 个;
- n = 10 时,需拿走第 1、4、7、10 个苹果,共 4 个;
- n = 11 时,仍然只拿走第 1、4、7、10 个苹果,共 4 个;
其实,问题中拿走苹果的规则,实际就是 “每三个苹果拿走一个”,我们可以考虑将 个苹果从左到右每 个分成一段,最后一段可能不足 个,则这一轮将拿走每一段的最左边的苹果,拿走的总数即分段的数量,在数学上可以使用向上取整记号表示。 代码实现时,可以使用一个循环,反复使,直至 为 ,则循环总次数即为第一问的答案。
再考虑第二问:编号为 的苹果在第几天被拿走? 解决第二问的关键点,在于关注到数据范围中的特殊性质:第一天就能取走编号为 的苹果。 形如 这样的模 余 的正整数时,第 个苹果一定会在第 天被拿走。所以当 模 余 时,答案即为 。但如果 不满足这一条件呢? 其实,我们只需要注意到,在拿走苹果使 n 不断减小的过程中:
- 当 模 余 时,这一天就会拿走最后一个苹果;
- 反之,当 模 余数不为 时,这一天不会拿走最后一个苹果。
从而初始时,若 模 余数不为 ,则第 个苹果还会留着,直至某一时刻 模 余 。所以我们可以在循环中反复判断当前苹果数 是否模 余 ,第一次判断成立时,此时已经经历过的循环次数就是第二问的答案。
最后,这一做法并不需要开数组,唯一需要分析的是时间复杂度。我们可以粗略估计:每一轮循环,大约变为原来的 2/3,假设循环次数为 ,则,故。
T2
25 分做法:
我们会发现此时 , 非常小。所以直接暴力枚举这 个站点每一个是否去加油就可以了。总共有 种情况,这就是一个子集枚举的过程。可以使用 或者二进制枚举来实现。 对于每一种情况,我们只需要算出每个站点的花费就可以了。 因为我们要使得花费最少,所以买油的数量就是能够刚好到达下一次加油的站点所需要的油。这里可以直接模拟,从第一个站点出发(第一个站点必须买油,否则一定无法到达站点 ),每次跳到下一个需要买油的站点。 这个过程和 分做法中模拟的过程是类似的,可以参考 分做法的解析。
额外的 分:
对于性质 ,站点 的油价是最低的,也就是在其它地方买油一定没有在站点 买划算。 由于我们的油箱大小是无限的,所以直接在站点 买够能走到站点 的油就可以了。 答案就是。
100 分做法:
我们可以发现从 号站点走到 号站点所需要的油一定是在 号站点买,从 号站点走到 号站点所需要的油,可以在 号站点和 号站点买,从 号站点走到 号站点所需要的油可以从 这三个站点买。
也就是说从 号站点走到 号站点这一段路,我们需要的油可以从前 个站点去购买。其实就相当于在 号站点买油需要花费的代价是前 个站点买油所需要的最小值。
接下来,我们就按照刚才这个性质进行模拟。
每次从当前站点买够刚好能走到下一个站点的油就可以了。
我们定义一个变量,用 表示我们走到下一个站点后还能多走多少路程。
直接从第一个站点开始往后走。初始时 。
- 如果 小于走到下次买油的地方的路程(也就是 ),我们就在这里买油,并且更新 和答案(花费)。 此时所需要买油的数量其实就是是我们走到下一站还需要的路程,表示走需要消耗的油的数量。 的变化就是新的。
- 否则的话,我们直接更新 ,让 减少我们走到下一个站点买油地方的路程。
- 不断重复上述讨论直到走到 n 号站点。
时间复杂度:
CPP#include<bits/stdc++.h>
using namespace std;
const int N = 100005;
int n, d, v[N], a[N];
long long ans;
int main(){
cin >> n >> d;
for(int i = 1; i < n; i++) cin >> v[i];
for(int i = 1; i <= n; i++) cin >> a[i];
int minn = a[1]; // 能加的最便宜的油
int rest = 0; // 剩下还能走的公里数
for(int i = 1; i < n; i++){
minn = min(a[i], minn);
if(rest >= v[i]){
rest -= v[i];
continue;
}
int t = (v[i] - rest + d - 1) / d;
ans += 1ll * t * minn;
rest = t * d + rest - v[i];
}
printf("%lld\n",ans);
return 0;
}
T3
25 分做法:
先来讨论特殊性质 ,也就是的情况,这个时候原本的方程就是,容易发现这个方程一定有实数解,并且两个解分别是。
-
当时,直接输出 。
-
当时,我们来考虑输出(其实本质上相当于输出一个形如的数字,均为整数)。
现在有两种情况。
- 第一种情况是个整数,也就是,此时直接输出的值。
- 第二种情况不是整数,也就是。此时我们需要按格式输出,可以给都除以它们的最大公约数,从而把化成最简真分数的形式。记的最大公约数是。
此时需要输出的解。 需要特别注意的就是当时,输出的是这样的形式,当时,输出的是的形式。
50 分做法:
接着我们来讨论性质 ,也就是的情况,这个时候原本的方程会变成。根据题意,当时方程无实数解,直接输出
NO;否则,方程解的形式一定是最大的实数解是,下面考虑如何输出(本质上需输出形如的数字,均为整数)。这里主要讨论的情况,因为时直接输出 即可。
-
当为整数时: 记,需要输出的解就是,接下来直接利用处理性质 时的方法来做。
-
当不为整数时:
- 先把转化为的形式,保证不存在大于 的数使得 。 因为,令,用从 ~ 枚举完全平方数,每次检查是否是的倍数,若是则让变为(为根号前系数),变为\(\frac{r}{i^{2}}) $(x_{1}=\frac{k}{a}*\sqrt{r}) $。
- 然后将化为最简分数形式: 记和的最大公约数是,令 。 此时输出的解) 。若,让和均变为相反数。 由于不是整数,所以,输出形式大致为。
需要注意两个特殊情况:
- 当时,不需要输出这个部分。
- 当时,不需要输出这个部分。
额外的 20 分:
现在我们来讨论性质 ,也就是如果方程有解,解一定是整数的情况。对于一元二次方程。
-
当时,方程无实数解,直接输出
NO。 -
当时,我们知道两个解。然后由于性质 保证如果有解,解一定是整数,所以我们可以通过枚举法来枚举这两个解。 由于答案一定是整数,说明一定是一个完全平方数,而且式子除以后可以整除,因此这里直接输出就可以了。
100 分做法:
根据题意,我们可以知道对于一元二次方程。
-
当时,方程无实数解,直接输出
NO。 -
当时,方程两个解分别为。
-
当时,最大的实数解是。此时我们记。
-
当时,最大的实数解是。此时我们记。
我们会发现需要输出的解,并且。
接下来我们分两种情况进行讨论:
- 为整数时: 记。我们要输出的数是,输出这种形式的解的做法和讨论性质 时一致。
- : 我们要输出的数是,我们要输出的其实是两个部分,一个部分是,另一个部分是,中间用
+连接。 所以我们可以先用之前的做法把第一部分输出。
需要特别注意,当时,也就是没有第一部分的时候。我们不需要输出第一部分和
+。而关于第二部分的输出,做法和讨论性质 时一致(当时我们需要输出的是,现在则是。
注意:现在我们需要枚举的完全平方数的范围不再是,因为,所以我们的i需要从枚举到。
满分做法其实就是把之前的对于特殊性质 A 和特殊性质 B 的做法进行整合。
时间复杂度:(O(TM))
CPP#include<bits/stdc++.h>
using namespace std;
int t, m, a, b, c;
int aa, bb, gd1, gd2;
int gcd(int a, int b){
if(a % b == 0) return b;
return gcd(b, a % b);
}
int main(){
scanf("%d%d", &t, &m);
while(t--){
scanf("%d%d%d", &a, &b, &c);
int det = b * b - 4 * a * c;
if(det < 0){
printf("NO\n");
continue;
}
int ans1 = 1;
for(int i = 2; i * i <= det; i++) {
while(det % (i*i) == 0)
ans1 *= i, det /= i * i;
}
aa = 2 * a; bb = -b;
if(aa < 0) aa = -aa, bb = -bb;
if(det == 1) det = 0, bb += ans1;
gd1 = gcd(abs(bb), aa);
gd2 = gcd(ans1, aa);
if(det == 0) {
if(bb % aa == 0) printf("%d", bb / aa);
else printf("%d/%d", bb / gd1, aa / gd1);
}
else {
if(bb != 0) {
if(bb % aa == 0) printf("%d", bb / aa);
else printf("%d/%d", bb / gd1, aa / gd1);
printf("+");
}
if(ans1 / gd2 != 1) printf("%d*", ans1 / gd2);
printf("sqrt(%d)", det);
if(aa / gd2 != 1) printf("/%d", aa / gd2);
}
printf("\n");
}
return 0;
}
T4 P9751 [CSP-J 2023] 旅游巴士
35分做法:
设想如果开放时间为的话,那说明在任何一个地点,都可以顺利走到下一点,不用考虑道路开放不开放的问题。而且第一次达到终点时,一定为答案要求的最早时间——这些数据点是最简单的了,这几乎就是bfs模板了。突破口就在此。
过程中,我们用记录点是否已经走过。那么在第一次遍历到, 程序就会结束,此时的离开时间不一定是的整数倍。有可能是第二次遍历到n时的时间才是的倍数,所以只记录是否访问过点,是不行的。还需要记录某个时间点是否来过这个点。因此,需要将数组修改为二维,第二维记录到达这个点的时间。
但是又会出现一个问题,这样空间不就爆了吗?其实,第二维只需要记录对的余数即可。因为,第二次或者后面扫描到同个点,且第二维的余数相同,肯定是没有第一次遍历到时的时间优的,一定是多了的整数倍。这是因为的搜索顺序,决定了早到达的时间一定小。题中,最多取100,所以空间上是满足要求的。
CPP#include<bits/stdc++.h>
using namespace std;
const int N = 1e4 +10;
int n, m, k;
struct edge{
int v, a; // 顶点, 及这个点开放时间
};
struct node{
int p, t;// 顶点,及到这个点的时间
};
vector<edge>g[N];
bool vis[N][110];
int bfs(){
queue<node>q;
q.push((node){1, 0});
while(q.size()){
node cur = q.front(); q.pop();
if(cur.p == n && cur.t % k == 0)// 第一次遇到的,且时间满足k倍,则一定是最优解
return cur.t;
if(vis[cur.p][cur.t % k]) continue;
vis[cur.p][cur.t % k] = true;
for(int i = 0; i < g[cur.p].size(); i++){
edge x = g[cur.p][i]; // 扩展下一个点
q.push((node){x.v, cur.t + 1});
}
}
return -1;
}
int main(){
cin >> n >> m >> k;
for(int i = 1; i <= m; i++){
int u, v, a;
cin >> u >> v >> a;
g[u].push_back((edge){v, a});
}
cout << bfs() << '\n';
return 0;
}
提交后,的确是35分!
接下来,我们加入道路的开放时间,进一步考虑。
从起点出发, 想去下一个相邻的地点前,检查一下当前时间与开放时间的大小。
- 如果当前时间 >= 开放时间,那么可以通过,并将当前时间
+1走到下一个相邻地点。 - 如果当前时间
<开放时间,那么说明走不通。真的走不通了?不,我们只需要推迟出发时间即可。举个例子,
如果,时刻从出发, 的开放时间是, 的开放时间是, 的开放时间为.
显然,上述例子中,时刻在号点,是无法到达号点的,因为此时道路还没开放。题目中又规定不能等待。但是实际上,我们可以通过推迟出发时间来达到停留的效果。由于出发时间必须是的倍数,因此增加的“等待"时间也必须是的倍数,
- 时刻判断道路是否开放,如果不开放,则继续推迟一个出发时间。
- ,此时发现可以通行,相当于等待了个的时间,到达号点。
那么,怎么计算需要多少个.
等待时间开放时间 到达时间 这里要取上整。
这也是出发时间需要推迟的单位时间数。下面我们就对
CPPbfs简单改造一下,加上对开放时间的判断。如果到某个点的时候,下一个地点的开放时间已经过了,那么可以走下去,如果没过,则将到达时间增加k的若干倍。#include<bits/stdc++.h>
using namespace std;
const int N = 1e4 +10;
int n, m, k;
struct edge{
int v, a; // 顶点, 及这个点开放时间
};
struct node{
int p, t; // 顶点,及到这个点的时间
};
vector<edge>g[N];
bool vis[N][110];
int ans = INT_MAX;
void bfs(){
queue<node>q;
q.push((node){1, 0});
while(q.size()){
node cur = q.front(); q.pop();
if(cur.p == n && cur.t % k == 0)
ans = min(ans, cur.t);
if(vis[cur.p][cur.t % k]) continue;
vis[cur.p][cur.t % k] = true;
for(int i = 0; i < g[cur.p].size(); i++){
edge x = g[cur.p][i];
if(cur.t >= x.a)
q.push((node){x.v, cur.t + 1});
else{
int wait = (x.a - cur.t + k - 1)/ k * k;
q.push((node){x.v, cur.t + 1 + wait});
}
}
}
}
int main(){
cin >> n >> m >> k;
for(int i = 1; i <= m; i++){
int u, v, a;
cin >> u >> v >> a;
g[u].push_back((edge){v, a});
}
bfs();
if(ans == INT_MAX) puts("-1");
else cout << ans << '\n';
return 0;
}
提交后得到50分!
再进一步思考,剩余的哪里出了问题? 思考下面的图: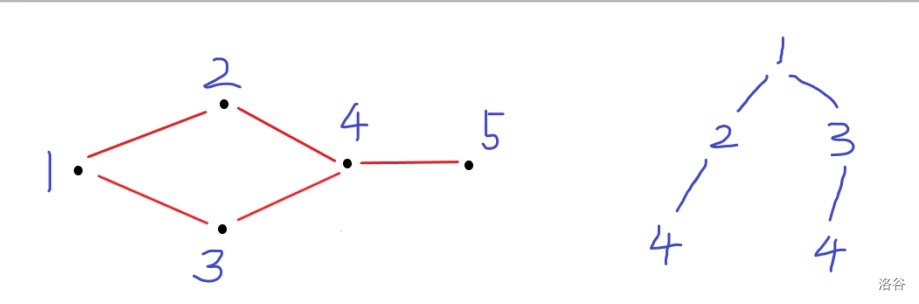
出发,扩展两个节点和
出发,扩展到4,时间为;
3出发,扩展到4, 时间为 , 且
4出发,扩展到5,刚好离开。
那么在上述分代码中,由于号先扩展出来的,使得标记了, 导致号扩展出来的, 在代码的第行被。 但实际上答案更优!
改进办法就是先计算号点扩展出来的,就可以避免上述情况。
怎么操作? 利用优先队列 替换普通队列即可!
只需将上述代码再次简单修改!
CPP#include<bits/stdc++.h>
using namespace std;
const int N = 1e4 +10;
int n, m, k;
struct edge{
int v, a; // 顶点, 及这个点开放时间
};
struct node{
int p, t; // 顶点,及到这个点的时间
friend bool operator < (node x, node y){
return x.t > y.t;//重载,时间越小,优先级越高
}
};
vector<edge>g[N];
bool vis[N][110];
int ans = INT_MAX;
void bfs(){
priority_queue<node>q;// 替换成优先队列
q.push((node){1, 0});
while(q.size()){
node cur = q.top(); q.pop();
if(cur.p == n && cur.t % k == 0) // 这次不是第一次搜到就是最优解了
ans = min(ans, cur.t); // 第一次搜到可能延迟了很多个k
if(vis[cur.p][cur.t % k]) continue;
vis[cur.p][cur.t % k] = true;
for(int i = 0; i < g[cur.p].size(); i++){
edge x = g[cur.p][i];
if(cur.t >= x.a)
q.push((node){x.v, cur.t + 1});
else{
int wait = (x.a - cur.t + k - 1) / k * k;
q.push((node){x.v, cur.t + 1 + wait});
}
}
}
}
int main(){
cin >> n >> m >> k;
for(int i = 1; i <= m; i++){
int u, v, a;
cin >> u >> v >> a;
g[u].push_back((edge){v, a});
}
bfs();
if(ans == INT_MAX) puts("-1");
else cout << ans << '\n';
return 0;
}
总结:
测试数据范围可能会引导我们思考的方向。从小范围数据开始着手考虑问题,慢慢再进一步优化算法,从而解决整个问题。
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...