专栏文章
Day02
算法·理论参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @miqf2ibe
- 此快照首次捕获于
- 2025/12/04 03:45 3 个月前
- 此快照最后确认于
- 2025/12/04 03:45 3 个月前
快速幂:
想要计算一个数 的 次幂
一个一个乘太慢了
我们需要更好的算法。
观察:
如果要计算一个数的 ,只需要把它作 次平方即可,因此实际上我们可以 地计算出一个数的 次方。
那么对于一般的数是预处理
我们预处理出 个 相乘, 个 相乘,,一直到 个 相乘,使得
接下来我们只需要把 分成若干个 的幂次相加就行了…这也是背包里二进制分组的思想
复杂度是 的。
矩阵快速幂:
首先,我们科普一下矩阵和它的乘法。
然后我们给出一道例题:求斐波那契数列的第 项
斐波那契数列:
把相邻两项拿出来,搞成一个 矩阵。
接下来,利用矩阵乘法的定义凑出一个递推式出来。
最后,我们利用矩阵乘法的结合律,把这个式子不断写下去
f_n
\\
f_{n-1}
\end{bmatrix}$$
$$\begin{bmatrix}
f_n
\\
f_{n-1}
\end{bmatrix}=\begin{bmatrix}
1 & 1\\1
&0
\end{bmatrix}\begin{bmatrix}
f_{n-1}
\\
f_{n-2}
\end{bmatrix}$$
$$\begin{bmatrix}
f_n
\\
f_{n-1}
\end{bmatrix}=\left ( \begin{bmatrix}
1& 1\\1
&0
\end{bmatrix} \right ) ^ {n-1}\begin{bmatrix}
f_1\\f_0
\end{bmatrix}$$
发现我们得到了一个东西的若干次幂的形式,那么使用快速幂就可以 $O(log\ n)$
#### 理论部分:
- 矩阵的本质是对列向量线性变换,可以把它当成一个“函数”。
- 矩阵乘法具有结合律。(这本质上是因为函数复合具有结合律)
- 具有结合律的运算可以使用矩阵快速幂。
矩阵乘法不满足交换律
求前 $n$ 项和对 $mod$ 取模的值:
$$f_0=a , f_1=b , f_2=c , f_n=pf_{n-1}+qf_{n-3}+2^n+n^2+fib_n$$
$$\begin{bmatrix}s_{n-1}
\\f_n
\\f_{n-1}
\\f_{n-1}
\\fib_{n+1}
\\fib_n
\\2^{n+1}
\\(n+1)^2
\\n+1
\\1
\end{bmatrix}
=\begin{bmatrix}
1&1 &0 &0 &0 &0 &0 &0 &0 &0 \\
0&p &0 &q &1 &0 &1 &1 &0 &0 \\
0&1 &0 &0 &0 &0 &0 &0 &0 &0 \\
0&0 &1 &0 &0 &0 &0 &0 &0 &0 \\
0&0 &0 &0 &1 &1 &0 &0 &0 &0 \\
0&0 &0 &0 &1 &0 &0 &0 &0 &0 \\
0&0 &0 &0 &0 &0 &2 &0 &0 &0 \\
0&0 &0 &0 &0 &0 &0 &1 &2 &1 \\
0&0 &0 &0 &0 &0 &0 &0 &1 &1 \\
0&0 &0 &0 &0 &0 &0 &0 &0 &1
\end{bmatrix}
\begin{bmatrix}s_{n-2}
\\f_{n-1}
\\f_{n-2}
\\f_{n-3}
\\fib_n
\\fib_{n-1}
\\2^n
\\n^2
\\n
\\1
\end{bmatrix}$$
记 $f[i][u]$ 表示在第 $i$ 个时刻,目前在点 $u$ ,有多少种方案,这样答案就是
$$\sum\limits_{0 \le i \le t, 1 \le u \le n}f[i][u]$$
转移是 $f[i][u] = \sum f[i-1][u]$,其中 $v$ 能到达 $u$ 或者 $v$ 就是 $u$ 。初始化 $f[0][1]=1$。
发现是一个线性加和的形式,成,直接写成矩阵然后快速幂就可以得到 $f$ 的值。
而答案刚好是一个关于 $t$ 的前缀和的形式,这个我们又见过了,也可以矩阵快速幂。
# 数据结构
顾名思义:存放数据的结构。
- 数组是不是数据结构?当然是。
- 为啥需要设计繁多的数据结构?为了更高效地维护数据的某些信息,比如最大值,最小值,某些数据的和,异或和,等等。另一方面,为了对数据进行封装,让我们不至于为了一个很简单的任务使用一个很复杂的结构。
通常情况下数据结构完成某一个操作的时间为 $log n$ ,可以接收的范围是 $\sqrt n$,在一些毒瘤题或者卡常做法中会出现 $\sqrt n log n$ 这种东西。
裸的数据结构题:你需要支持若干修改操作 $/$ 查询操作。强制在线 $/$ 可以离线。
不裸的数据结构题:给你一道题,它的一个核心是通过某个数据结构维护一个东西。
## 一张梗图

# ST表
回忆倍增算法。
维护一个数据结构,支持查询任意区间的最大值。( $RMQ$ 问题)
在每一个位置 $i$ 维护区间 $[i,i+2^k)$ 的最大值。
查询就拼起来。
查询有没有更快的做法?直接叠起来!
预处理 $O(nlogn)$ ,查询 $O(1)$。
## 设计数据结构
我们可以这样设计一个数据结构
支持 : 尾部加入一个元素,头部删除一个元素,查询数据结构内所有元素的最大值。
我们发现这个东西除了第三个功能,有点像一个队列。
那么怎么维护最大值呢?
一个很严重的问题摆在我们面前:“删除”操作很头疼,因为你不能做到删掉一个数之后“复原”最大值,也就是说最大值不满足可减性。
此时就有两个思路:
- 通过栈结构规避删除操作,对应分块做法与“双栈模拟队列”做法。
- 继续发掘题目中有用的性质,对应“单调队列”做法。
## 单调队列
我们考虑后一个思路。
一个不那么显而易见的观察是:当一个位置 $j$ 对应的数字 $a[j]$ 比新加入位置 $i$ 对应的数字 $a[i]$ 要小(准确来讲,不大)的话,那么 $a[j]$ 在今后永远不可能成为最大的数字。因为它会先 $i$ 一步被扔出窗口。
因此,我们的数据结构里的所有元素应该满足这样一个特征:所有元素从左到右单调递减,只有这样才能够满足数据结构中的每一个元素都是有用的,也就是说我们舍弃了那些没用的元素。
更进一步地,此时最左侧的元素就是最大值!
那么,怎么维护这种“单调”的结构呢?
我们发现,只需要在每次在尾部加入一个位置 $i$ 的时候,不断地 $pop$ 掉尾部那些比它小的元素,直到下一个元素严格比它大,就可以把它加入到队尾了!
由于每个元素仍然只入队一次,出队一次,因此总复杂度仍然是 $O(n)$ 的。
如果我们把要解决的问题写出来,会发现它长成这个样子:
$$ans_i=\underset{j\ge i-k+1}{max} \left \{ a_j \right \} $$
那么接下来就是喜闻乐见的扩展环节了。
$$ans_i=\underset{f_i\ge g_i}{max} \left \{ h_j \right \} $$
问题变成:给定三个数组 $f$ , $g$ , $h$ ,求数组 $ans$。
考虑把这个问题转化到滑动窗口问题。
把下标按 $f$ 从小到大排序,此时:
- 如果 $g$ 单调不降,那么变成滑动窗口问题。$O(n)$
- 否则,我们不要使用队头 $pop$ 这个操作,而是直接二分找分界点。
## 单调栈
给定一个序列,对于每个位置 $i$ 求出 $i$ 之后第一个大于 $a[i]$ 的元素 $a[j]$ 对应的下标 $j$。
我们仿照单调队列的思路,考虑剔除不需要的元素。
把这个过程看成是一个“站队”的过程,每个身高为 $a[i]$ 的人向右看,能看到的第一个人。
对于 $j<k$ ,如果 $a[j]>a[k]$ ,那么 $k$ 就被 $j$ 完全挡死啥也看不见了。
删掉这样的 $k$ ,我们会得到一个从左到右单调递增的序列,每次向这个序列的最左侧增加一个$a$,然后删掉被它挡死的所有元素。最后最左边的那个元素就是我们想要的。
由于每个元素最多会进栈一次,因此复杂度 $O(n)$。
## 堆
维护一个数据结构,维护一个集合,支持插入一个元素,查询最大值,删除最大值。
又遇到了删除问题,但是这次我们没有很好的性质去利用了,必须要使用更加复杂的数据结构。
考虑将数据结构中的每个元素排成一棵完全二叉树,使得父亲结点的值大于等于两个儿子结点的值,那么最大值就是根结点的值。
现在考虑如何实现插入和删除两个操作。
首先是插入:我们先把待插入的结点放在完全二叉树最后一层最右边的叶子之后。然后不断地向上将这个叶子与父亲结点 $swap$ ,直到父亲的权值大于等于这个叶子的权值。复杂度 $O(log n)$ 。
接下来考虑删除:我们把最后一层的最后一个叶子节点与根交换,删除根节点,紧接着不停地把这个叶子与它权值最大的那个儿子 $swap$ ,重复这个过程直到不需要 $swap$。复杂度 $O(log n)$。
我们称第一个过程中让新节点不断上浮的过程为“向上调整”,下面那个将叶子节点不断下沉的过程叫“向下调整”。
最后是直接用 $n$ 个元素建堆的方法:直接 $sort$ 或者一个一个插入是 $O(nlogn)$ 的,但是我们从 $n$ 到 $1$ 不断向下调整每个结点,就是 $O(n)$ 的。
### 可删除堆
找到并删除一个非堆顶元素太麻烦了!因此我们不妨“懒”一点:新开一个堆,维护所有“删除操作”,就像一个代办清单,那么堆顶的操作是最迫切的那个:元素值最大的那个。
接着,由于我们所有的操作都是在堆顶完成的,因此我们一旦看见堆顶的值刚好和我们“待办清单”中的第一个值一样,我们就把它和这个操作同时删掉。这样一来,我们既不用费劲去找那些值,只需要等它们自己到堆顶就行。
### 对顶堆
我们维护两个堆,然后把它们的堆顶拼在一起。
左边是一个大根堆,堆顶叫 $x$ ,右边是一个小根堆,堆顶叫 $y$。
我们需要满足 $x < y$。
每次加入一个元素 $v$ ,如果 $ x < v$ ,那么我们把它扔进右面的小根堆,不然我们把它扔进左边的大根堆。
接下来,不停地把右边的堆顶扔进左边或者把左边的堆顶扔进右边:总之,让两个堆的大小差值不超过 $1$ 。
最后堆大小较大的那个堆的堆顶就是中位数。
(相当于我们把中位数夹在两个数中间)
## 并查集
维护一个数据结构:一开始有 $n$ 个元素,分别位于 $n$ 个不同的集合,支持两个操作:
1. 将两个集合合并为一个集合
2. 查询两个元素是否在同一个集合中。
我们考虑用一个树形(准确来讲,森林)结构去实现这些操作。
把元素当成一个结点,并给每个点指派一个父亲结点,或者把它作为一个树根,此时它的父亲结点设为自己。
这样我们就可以把一个集合看成一棵有根树,它的根就是这个集合的代表元素。
查询两个点是否在一个集合其实就是查询两个点所在树的树根是否一样。
合并两个集合其实就是把其中一棵树的树根合并到另一棵树上。
单次查询是 $O$ (树高) $= O(n)$ 的,合并因为要查询,所以也是 $O$ (树高) $ =O(n)$的。
### 路径压缩与按秩合并
我们延续搜索中“记忆化”的思想,如果我们已经知道某个点的树根了,那我们直接把这个点的父亲设置为它的树根,这样以后再找根就只需要蹦一步了。
另一个优化是,如果我们每次把深度较小的那个树合并到深度较大的树上,就可以使得树高增加地尽可能缓慢。这样也可以减少时间复杂度。
|优化|平均时间复杂度|最坏时间复杂度|
|:-:|:-:|:-:|
|无优化|$O(logn)$|$O(n)$|
|路径压缩|$O(\alpha (n))$|$O(logn)$|
|按秩合并|$O(logn)$|$O(logn)$|
|路径压缩+按秩合并|$O(\alpha (n))$|$O(\alpha (n))$|
**注:反阿克曼函数 $a(n)$ 是一个增长难以想象地缓慢的函数,它是单调增的,但是在宇宙可观测的 $n$ 内不会超过 $5$ ,其实就是和常数没区别。**
```cpp
#include <bits/stdc++.h>
using namespace std;
int n,m,s,p1,p2,p3,ans,f[10001];
int find(int k){
if(f[k]==k)return k;
return f[k]=find(f[k]);
}
int main(){
cin >> n >> m;
for(int i=1;i<=n;i++)f[i]=i;
for(int i=1;i<=m;i++){
cin >> p1 >> p2 >> p3;
if(p1==1)f[find(p2)]=find(p3);
else
if(find(p2)==find(p3))printf("Yes\n");
else printf("No\n");
}
return 0;
}
```
## 线段树
### 区间问题
维护一个序列上的数据结构,支持:
- 给某个位置加上一个整数。
- 查询某个区间的和 $/$ 最大值。
这时分治结构要出来了。
采取这种从中间对半劈开的方法,我们发现任何一个区间都可以表示成这些区间没有交集的并。
比如 $[2,6]$ 就是 $[2,2] + [3,4] + [5,6]$ 。
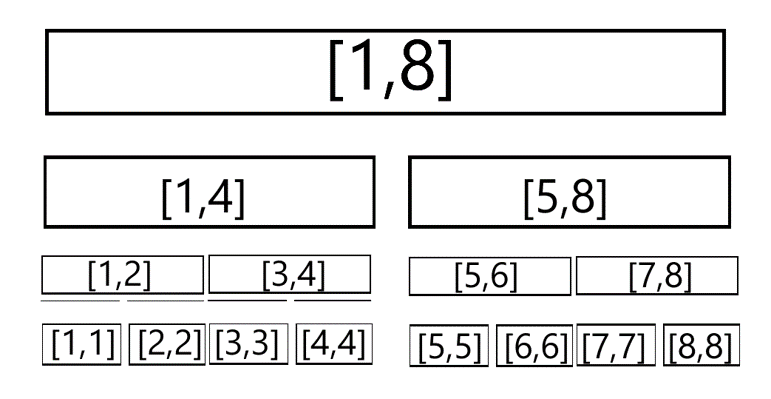
我们发现这样的对半分的区间实际上形成了一棵完全二叉树,称为线段树。
观察:一段区间在线段树上表现为一个被二进制拆分的前缀和一个被二进制拆分的后缀,因此一个区间总可以被划分为 $O(logn)$ 个小区间。
这样我们只需要维护这 $O(n)$ 个区间上的和与最大值即可。
而修改一个点最多只会影响 $O(logn)$ 个区间的值,我们直接修改这些区间即可。
复杂度:建树 $O(n)$ ,单次区间查询 $O(logn)$ ,单点修改 $O(logn)$
### 懒标记
如果区间加一个数呢?
我们发现,一次区间修改可能会影响所有的结点
但是不要怕,我们要充分利用线段树的结构,把要修改的区间同样劈成 $O(log n)$ 个区间,能不能只修改这几个区间?
懒标记:我们发现这个区间的答案是好办的:区间的和增加 $v*(r-l+1)$ ,区间的最大值增加 $v$ 。因此我们先增加区间的答案,然后给这个区间做一个记号:设置一个$tag$ 记录这个结点总共被加了多少。
那么当我们需要用到它子节点的时候,将标记“下传”到子节点,同时更新子节点的答案,这样懒标记就被下放到子节点继续挂着。
于是我们发现,只需要每次在前往子节点时下传懒标记,就可以使得每个结点的值都是正确的,我们也就完成了 $O(logn)$ 的区间加。相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...