专栏文章
字典树(trie)详解
算法·理论参与者 2已保存评论 1
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 1 条
- 当前快照
- 1 份
- 快照标识符
- @mk74k821
- 此快照首次捕获于
- 2026/01/10 01:03 上个月
- 此快照最后确认于
- 2026/02/19 01:19 13 小时前
引入
字典树是一种存储字符串的树形数据结构。具体来说,每条边有一个字符,每个节点到儿子的边的字符不重。同时每个节点都代表一个字符串,为从根节点出发向下走到这个节点路上经过所有边的字符组成的字符串。
下面给出了字典树的一个例子:
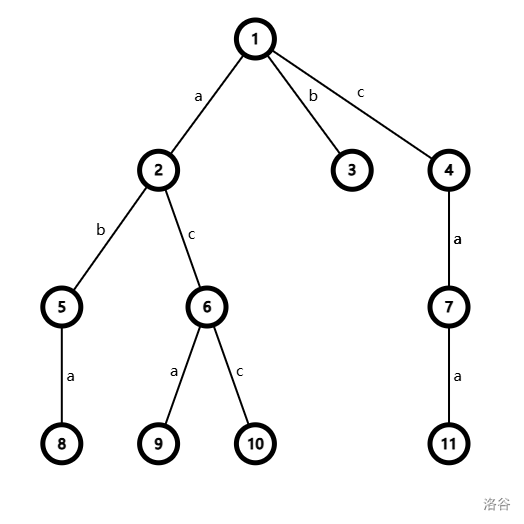
例如节点 表示的字符串为 ,节点 代表的字符串为 。
当我们把一个可重字符串集维护成字典树时,我们需要知道那些字符串有几个,因此会在每个节点 处打上标记 ,表示节点 代表的字符串 在当前可重集中有 个。
例如如果把以下字符串集 存到上面的字典树中,那么 ,其余均为 。
因为每个节点到儿子的边的字符不重,所以任何在字典树上的字符串都有唯一的一个节点来代表它。
字典树具有的最重要的性质是任意两个字符串集中不等的字符串 , 为 前缀 当且仅当 代表 的节点为 节点的祖先,正确性显然。这条性质说明字典树就是维护前缀类信息的数据结构,这也是它大部分应用所基于的性质。
代码实现细节
一般会用 表示节点 边上字符为 的儿子,反映到代码上就是一个数组
ch[u][i] 表示 ,如果没有记为 0 或 -1,取决于你的代码习惯。为了节省空间,
ch 一般开到 ch[N][M],其中 N 是可能用到的 trie 节点个数,上界为字符串长度之和,M 是字符集大小,即 。通过一个函数(我一般用 get)来把字符转换为唯一对应的数,用于访问 ch 的第二维。根节点取
0 或者 1,同时 trie 肯定是动态开点的,记一个 idx 即可,以下设根节点为 。插入字符串
按照定义从根节点出发往下找即可,发现没有创建的节点就创建。
CPPint ch[N][M], cnt[N], idx = 1, rt = 1;
int get(char);
void insert(const string& s) {
int u = rt;
for (char i : s)
u = ch[u][get(i)] ? ch[u][get(i)] : ch[u][get(i)] = ++idx;
cnt[u]++;
}
删除字符串
从上往下找到然后让 减去 即可。
CPPvoid remove(const string& s) {
int u = rt;
for (char i : s) u = ch[u][get(i)];
if (u) cnt[u]--;
}
应用
多次查询前缀/后缀个数
即给定 个模式串 ,每次询问给定一个字符串 求有多少个模式串是它的前缀/后缀。
根据 trie 的性质,插入所有模式串后,如果找前缀个数,从根结点出发按 走若没有点就停下,路上经过的点的 之和即为答案;找后缀就找到代表 的节点,查询子树 之和即可。
P8306 【模板】字典树(找前缀个数)代码
CPP#include <iostream>
#define endl '\n'
using namespace std;
constexpr int N = 1e5 + 10, M = 1e6 + 10, K = 26;
int n, m;
int idx = 1, ch[M][K], cnt[M];
int get(char ch) { return ch - 'a'; }
void push(const string& s) {
int u = 1;
for (char i : s) {
if (!ch[u][get(i)]) ch[u][get(i)] = ++idx;
u = ch[u][get(i)];
}
cnt[u]++;
}
int query(const string& s) {
int u = 1, res = 0;
for (char i : s)
res += cnt[u = ch[u][get(i)]];
return res;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m;
for (int i = 1; i <= n; i++) {
static string temp;
cin >> temp;
push(temp);
}
for (int i = 1; i <= m; i++) {
static string temp;
cin >> temp;
cout << query(temp) << endl;
}
return 0;
}
求序列两两异或和最大值
我们把每个整数的二进制高位补零到 位后从高位到低位插入 trie 中,称为 01-trie。
首先如果查询一个整数和 trie 中所有数异或和的最大值,根据位运算的性质,贪心地让高位更优一定是全局最优的,因此我们可以从高位往低位枚举,如果 trie 中存在和该整数异或后该位为 ,表现为当前遍历节点存在该数在该位值异或 的子节点,那么就必定要走这个儿子,否则一定不是最优的。否则只能走另一个儿子。因为 trie 中每个数插入的长度固定,除了最后一层节点每个节点都有至少一个儿子。
于是就可以一个一个把整数插入 Trie 中,在插入整数前查询一下当前 Trie 中和该整数异或和最大值即可。
上述问题代码
CPP#include <iostream>
using namespace std;
constexpr int N = 1e5 + 10, M = 32e5 + 10, K = 31;
int n, ans = 0;
int idx = 1, ch[M][2];
void push(int val) {
int u = 1;
for (int i = K - 1; ~i; i--) {
if (!ch[u][val >> i & 1]) ch[u][val >> i & 1] = ++idx;
u = ch[u][val >> i & 1];
}
}
int query(int val) {
int u = 1, res = 0;
for (int i = K - 1; ~i; i--) {
int j = val >> i & 1;
if (ch[u][j ^ 1]) { // 能走一定走,累计答案
u = ch[u][j ^ 1], res |= 1 << i;
} else {
u = ch[u][j];
}
}
return res;
}
int main() {
ios::sync_with_stdio(false);
cin >> n;
for (int i = 1; i <= n; i++) {
int val; cin >> val;
if (i > 1) ans = max(ans, query(val));
push(val);
}
cout << ans << endl;
return 0;
}
Trie 优化建图
根据 Trie 的性质,和字符串前后缀有关的问题可以利用 Trie 的树形结构,来优化图论模型。下面给出了一道例题。
P6965 [NEERC 2016] Binary Code
给定 个 01 串,每个 01 串至多有一位未知,可填 0 或 1,求是否存在一组方案,使得任意一个字符串都不是其它任意字符串的前缀。
,其中 为 01 串长度之和。
每个串只有两种选择,因此使用 2SAT,把每个串拆成两个点,称为决策点。
对于完全确定的串,任意取一个位置拆开,然后让代表变化后串的点向代表原串的点连一条边即可。
对于代表完全相同字符串的多个点,每个点要向其它每个点的否定连边,因此可以使用前后缀优化建图。
接下来最后一种连边就是每个点对代表它所代表字符串的前缀和后缀的点的否定连边。因为是前后缀关系,考虑使用字典树。把每个点代表的串放入字典树中,然后在图中以此为基本建出一棵根向树和一棵叶向树。
树上每个节点向代表它在 trie 中代表的字符串的点的所有否定连边,随后对于每个决策点,在根向树上向它代表字符串在 trie 中节点的父亲连边,在叶向树上向它代表字符串在 trie 中节点的所有儿子连边(不直接在节点连边是为了防止直接连向它的否定),这样就处理完了所有冲突的情况。
最后按 2SAT 的跑 Tarjan,然后输出答案即可。
代码
CPP#include <iostream>
#include <vector>
#define endl '\n'
#define gia(__X__) ((__X__) > n ? (__X__) - n : (__X__) + n)
#define gt1(__X__) ((__X__) + (n << 1))
#define gt2(__X__) ((__X__) + (n << 1) + tn)
#define gx(__X__) ((__X__) + (n << 1) + (tn << 1) + gm)
using namespace std;
constexpr int N = 5e5 + 10, TN = 5e5 * 2 + 10, SN = 5e5 * 8 + 10, SM = 5e5 * 12 + 10;
vector<int> tv[TN];
int n, tc[TN][2], fa[TN], tn = 1, gm;
struct { string s; int p; } a[N];
vector<int> g[SN];
bool vis[SN];
int curdfn, dfn[SN], low[SN], stk[SN], top, scc[SN], cnt;
int get(char ch) { return ch == '1'; }
void addedge(int u, int v) {
g[u].push_back(v);
}
void push(const string& s, int val) {
int u = 1;
for (char i : s)
u = tc[u][get(i)] ? tc[u][get(i)] : (tc[u][get(i)] = ++tn);
tv[u].push_back(val);
}
void tarjan(int u) {
low[u] = dfn[u] = ++curdfn, vis[u] = true, stk[++top] = u;
for (int v : g[u]) {
if (!dfn[v]) {
tarjan(v);
low[u] = min(low[u], low[v]);
} else if (vis[v]) {
low[u] = min(low[u], dfn[v]);
}
}
if (low[u] == dfn[u]) {
++cnt;
do scc[stk[top]] = cnt, vis[stk[top]] = false;
while (stk[top--] != u);
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> a[i].s, a[i].p = -1;
for (size_t j = 0; j < a[i].s.size(); j++)
if (a[i].s[j] == '?') a[i].p = j;
string t = a[i].s; int p = a[i].p == -1 ? 0 : a[i].p;
t[p] = '0', push(t, i), t[p] = '1', push(t, n + i);
if (a[i].p == -1) (a[i].s[0] == '0' ? addedge(n + i, i) : addedge(i, n + i)), a[i].p = 0;
}
for (int i = 1; i <= tn; i++)
tc[i][0] && (fa[tc[i][0]] = i), tc[i][1] && (fa[tc[i][1]] = i);
for (int i = 1; i <= tn; i++) {
if (tc[i][0]) addedge(gt1(i), gt1(tc[i][0])), addedge(gt2(tc[i][0]), gt2(i));
if (tc[i][1]) addedge(gt1(i), gt1(tc[i][1])), addedge(gt2(tc[i][1]), gt2(i));
for (int j : tv[i]) {
addedge(gt1(i), gia(j)), addedge(gt2(i), gia(j));
tc[i][0] && (addedge(j, gt1(tc[i][0])), false), tc[i][1] && (addedge(j, gt1(tc[i][1])), false);
fa[i] && (addedge(j, gt2(fa[i])), false);
}
if (tv[i].size() > 1) {
int dm = tv[i].size();
for (int j = 0; j < dm; j++)
addedge(gx(j + 1), gia(tv[i][j])), addedge(gx(j + 1 + dm), gia(tv[i][j])),
j > 0 && (addedge(tv[i][j], gx(j + dm)), false), j < dm - 1 && (addedge(tv[i][j], gx(j + 2)), false);
for (int j = 1; j < dm; j++) addedge(gx(j), gx(j + 1));
for (int j = dm; j > 1; j--) addedge(gx(j + dm), gx(j - 1 + dm));
gm += (dm << 1);
}
}
for (int i = 1; i <= gx(0); i++)
if (!dfn[i]) tarjan(i);
for (int i = 1; i <= n; i++)
if (scc[i] == scc[n + i])
return cout << "NO" << endl, 0;
cout << "YES" << endl;
for (int i = 1; i <= n; i++) {
a[i].s[a[i].p] = scc[i] < scc[n + i] ? '0' : '1';
cout << a[i].s << endl;
}
return 0;
}
01 trie 维护全局异或和
下面介绍一种基于 01 trie 的数据结构,它维护了一个可重集合 ,支持插入、删除、查询 中所有元素的异或和以及给 中每个数加上 这四个操作。
具体来说,我们把 中的数高位补 到相同位数后从低位到高位插入到 01 trie 中(注意和最大异或对的 trie 不一样),同时每个节点维护其子树中包含的数的数量(下称 ,代码中用
siz 表示),和它子树中包含数的异或和(下称 ,代码中用 val 表示)。注意这个异或和是切断它和父亲节点的联系后,把它作为一棵 trie 的根节点所形成的 trie 树中,所有存储元素的异或和,而不是在原树视角下它这个子树存储元素的异或和。也就是说如果它子树高度为 (一个节点的树高度称为 ),那么它的异或和是 位的。
那么这样我们很容易写出
CPPpushup 函数(用于更新当前点信息)的代码:void pushup(int u) {
if (!ch[u][0] && !ch[u][1]) return; // 叶子不要更新
siz[u] = siz[ch[u][0]] + siz[ch[u][1]];
// 左右儿子异或和左移一位,得到除了最低位的其它位
// 然后如果这一为 1 的元素个数为奇数才更新最低位
val[u] = ((val[ch[u][0]] ^ val[ch[u][1]]) << 1) | (siz[ch[u][1]] & 1);
}
插入和删除时找到对应位置插入,然后一路
pushup 回到根节点即可,删除同理,这里就不放代码了。集合整体加 操作
分析一下一个数加上 这个过程,可以发现是从低位往高位找到第一个不为 的位,把这一位置为 ,然后把前面遍历到的置为 。
放到 trie 树上,对于一个节点 ,如果要把它的子树中所有元素加上 ,那么可以发现当前最低位为 的元素(都在 的子树中)要把最低位置为为 ,只需要令 即可;对于原来最低位位 的,那么需要将其置为 ,并继续递归下去处理,于是就要交换 和 ,然后对新的 ,即原来的 递归下去进行处理。回溯时重新计算当前节点权值即可。
下面给出整体加 的代码:
CPPvoid addall(int u) {
if (!u) return;
swap(ch[u][0], ch[u][1]); // 交换左右儿子
addall(ch[u][0]), pushup(u); // 递归处理新左儿子,更新当前节点
}
很明显只会遍历 trie 上的一条链,复杂度为深度,若设值域为 ,那么这里就是 的。
在应用上这种 trie 一般和下面要讲的 trie 合并搭配起来使用。
trie 树的合并
trie 和线段树同属分治数据结构,因此也可以实现合并操作。具体来说,就是没有的节点选有的用,都有的节点往下递归合并,代码长得和线段树合并也差不多。
下面给出了 01 trie 的合并代码(其它 trie 的不常用,不过要写原理和下面是一样的):
CPPint merge(int u, int v) {
if (!u || !v) return u | v; // 有一个没有,选有的那个/都没有返回 0
if (!ch[u][0] && !ch[u][1]) {
// ...
// 做叶子信息的合并
}
// 递归合并左右儿子
ch[u][0] = merge(ch[u][0], ch[v][0]);
ch[u][1] = merge(ch[u][1], ch[v][1]);
return pushup(u), u; // 更新当前节点信息
}
复杂度上,和线段树合并类似,最坏需要遍历整棵 trie 树,复杂度线性,只有合并操作满足某些特殊性质时才能保证复杂度。因此确切知道复杂度前慎用
例题——P6623 [省选联考 2020 A 卷] 树
每个节点都先建立一棵 01 trie 保存它自己的权值,随后在一次深度优先搜索时每个节点把它子节点的 trie 合并起来加上 再合并上它自己权值的 trie 就得到了它子树所有元素的异或 01 trie,查询全局异或和就得到了当前节点的价值。
这样就得到了一种 的算法,足以通过本题。
题目代码
CPP#include <cstdint>
#include <iostream>
#include <vector>
#define int int64_t // 十年 OI 一场空,________
using namespace std;
constexpr int N = 525020, K = 25, M = N * K;
int n, a[N], h[N], e[N], ne[N], idx, ans;
// 实际上不用垃圾回收也可以,空间复杂度仍为 nlogV
int m, ch[M][2], siz[M], val[M], pool[M], pooltop;
void addedge(int u, int v) {
++idx, e[idx] = v, ne[idx] = h[u], h[u] = idx;
}
void clear(int u) { ch[u][0] = ch[u][1] = siz[u] = val[u] = 0; }
void pushnode(int u) { clear(pool[pooltop++] = u); }
int getnode() { return pooltop ? pool[--pooltop] : ++m; }
void pushup(int u) { // 01 trie 的 pushup
if (!ch[u][0] && !ch[u][1]) return;
siz[u] = siz[ch[u][0]] + siz[ch[u][1]];
val[u] = ((val[ch[u][0]] ^ val[ch[u][1]]) << 1) | (siz[ch[u][1]] & 1);
}
int build(int x) { // 按一个权值建树
int rt = getnode(), u = rt;
siz[rt] = 1, val[u] = x;
for (int i = 0; i < K; i++)
u = ch[u][x >> i & 1] = getnode(), siz[u] = 1, val[u] = x >> (i + 1);
// 注意这里 val 要取 x >> (i+1) 因为异或和是局部的
return rt;
}
int merge(int u, int v) { // 01 trie 合并
if (!u || !v) return u | v;
if (!ch[u][0] && !ch[u][1]) siz[u] += siz[v];
ch[u][0] = merge(ch[u][0], ch[v][0]);
ch[u][1] = merge(ch[u][1], ch[v][1]);
return pushup(u), pushnode(v), u;
}
void addall(int u) { // 全局加 1
if (!u) return;
swap(ch[u][0], ch[u][1]);
addall(ch[u][0]), pushup(u);
}
int dfs(int u) {
int rt = 0;
for (int i = h[u]; i; i = ne[i])
rt = merge(rt, dfs(e[i])); // 合并儿子的 trie
addall(rt); // 这里加 1 有助于减小常数
rt = merge(rt, build(a[u]));
return ans += val[rt], rt; // 查询全局异或和,就是根节点的 val
}
signed main() {
ios::sync_with_stdio(false);
cin >> n;
for (int i = 1; i <= n; i++) cin >> a[i];
for (int i = 2, f; i <= n; i++)
cin >> f, addedge(f, i);
dfs(1);
cout << ans << endl;
return 0;
}
练习题
相关推荐
评论
共 1 条评论,欢迎与作者交流。
正在加载评论...