专栏文章
浅谈进阶数据结构
算法·理论参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @mindu6d3
- 此快照首次捕获于
- 2025/12/02 00:47 3 个月前
- 此快照最后确认于
- 2025/12/02 00:47 3 个月前
放在前面
本文并非“进阶数据结构教程”,只用于快速记忆各大数据结构的基础原理和实用性。
数据结构在信息学竞赛中处处可见,可以说“程序离不开数据结构”。变量、数组、hash 表、线段树等,都是数据结构。我们之前学过的相较基础的数据结构(
stack,queue 等),都是一种比较通用而简单的数据贮存或简单的处理方法,本文中将不再过多提及。进阶数据结构作为提升程序时空复杂度的关键,对于诸多问题都非常必不可少。当要求的操作类型指定、运算规则简单、存在已知做法时,就往往要想到使用数据结构来优化它。
通过具体问题选择数据结构,看上去就变得至关重要了。
本文总结了比较简单的常见进阶数据结构的思想和应用,希望各位能透过本文,重新用进阶数据结构的眼光审视这些有趣的问题。
前置知识:懒惰标记,二分算法,最近公共祖先,树上差分。
区间上的分块
引入
人们常说:“分块是一种优雅的暴力”。为什么呢?
来看这样的一道经典问题:教主的魔法。
给你一个长度为 的序列 ,你需要进行 次操作,操作类型如下:
- 将区间 中所有数的值增加 。
- 查询区间 中,有多少个数不小于 。
,,,,初始 。
我们来看“已知的算法”能否解决该问题:
- 暴力显然 ,过不去。
- 使用差分算法,每次只改变差分数组中 和 的值。然而,查询可能穿插在修改中,为了完成查询,仍然要求一遍前缀和。加上查询的复杂度仍然是 。
- 假设你会一种可以在 时间复杂度内完成区间修改部分和区间和的查询部分(后文要提及的数据结构:线段树)。但仍然不能完成!后文会讲到,线段树需要信息可合并的问题。然而,在该问题中, 的值会变化,因此每次都需遍历每个子节点,而非笼统地统计区间和。时间复杂度 ,直接爆炸。
没有任何已知算法能够解决该问题!此时,分块将助你一臂之力。
核心思想
分块思想将区间划分为多个等长的小块(除最后一个块外),每次跨区间的操作都直接处理每个块的内容(蓝色部分),并暴力处理两端的单独内容(绿色部分)。这样一来,我们就成功地将问题所需的变量的巨大更新规模转化到了大块的处理中。这样的块的长度称之为“块长”。
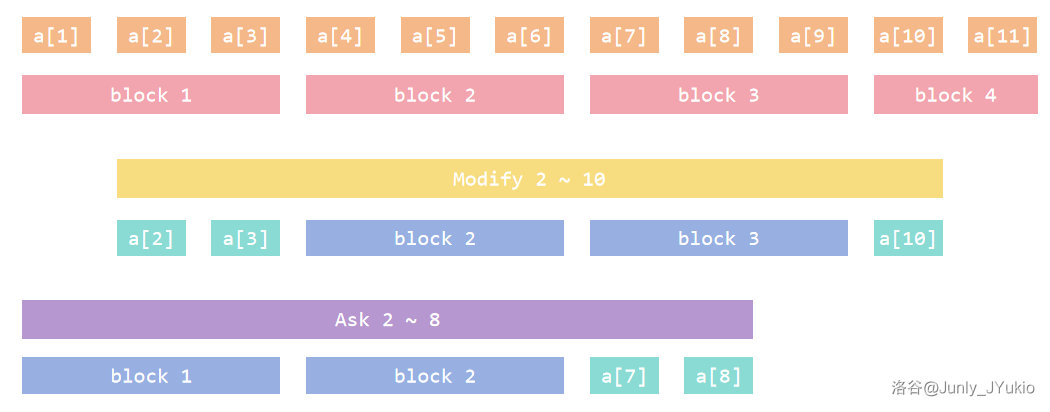
通常情况下,我们都会将长度为 的区间均匀分成 个块(每块大小约 )。如果块长过长,在两端的点所需枚举的复杂度过大;如果块长过小,则每次需枚举的块的个数较多。
因为“块内暴力 + 块外整体”对时间复杂度的平衡,分块思想的单次操作平均复杂度往往是 。
当然除了纯根号的经典版本,块长也可以灵活变化,如可以变为 。
核心操作
分块的操作步骤如下:
- 预处理分块:计算块长 ,划分块编号,预处理每个块的基础信息(如块内总和)。
inline void init_(){
block=sqrt(n);
for(int i=1; i<=block; i++) L[i]=(i-1)*block+1,R[i]=i*block;
if(R[block]<n) block++,L[block]=R[block-1]+1,R[block]=n;
for(int i=1; i<=block; i++) for(int j=L[i]; j<=R[i]; j++) pos[j]=i;
}
时间复杂度 。
- 区间更新:
- 若更新区间覆盖完整块,标记块的懒更新标记;
- 若为不完整块,遍历元素更新并同步块信息。
inline void add(int l,int r,int c) {
x=pos[l],y=pos[r];
if(x==y) {
for(int i=l; i<=r; i++) update_blocks(i);
return;
}
for(int i=l; i<=R[x]; i++) update_items(i);
for(int i=r; i>=L[y]; i--) update_items(i);
lazy_tag(x,y);
}
- 区间查询:
- 完整块直接累加块信息;
- 不完整块遍历元素计算结果。
inline int ask(int l,int r,int c) {
int s=0;
x=pos[l],y=pos[r];
if(x==y) {
for(int i=l; i<=r; i++) query_blocks(s,i);
return;
}
for(int i=l; i<=R[x]; i++) query_items(s,i);
for(int i=r; i>=L[y]; i--) query_items(s,i);
query_lazy_tag(s,x,y);
}
例题解答
在本题中,我们可以使用分块加上懒标记思想。
对于每个块,我们统计这个块已经修改的元素值 。为了保持块内元素的严格有序,每次零散处理元素的时候,就将该元素所在的块全部重新排序。至于整块,不用处理,因为单调性没有发生变化。
至于查询的时候,注意到所有 的元素都能造成一次贡献。于是,就只需要二分查找第一个满足 的元素,其元素与该块中之后的元素都能造成一次贡献。
时间复杂度:定义 。一次修改 (两端排序),一次查询 (每块二分),故可以通过此题。
代码
CPP#include<cstdio>
#include<algorithm>
#include<cmath>
using std::sort;
using std::sqrt;
const int maxn=1e6+10;
int n,q,a[maxn],b[maxn],L[maxn],R[maxn],pos[maxn],add[maxn],block,num;
inline void init(int x) {
for(int i=L[pos[x]]; i<=R[pos[x]]; i++) b[i]=a[i];
sort(b+L[pos[x]],b+R[pos[x]]+1);
}
inline void build() {
block=sqrt(n);
num=n/block;
if(n%block) num++;
for(int i=1; i<=n; i++) pos[i]=(i-1)/block+1,b[i]=a[i];
for(int i=1; i<=num; i++) L[i]=(i-1)*block+1,R[i]=i*block;
R[num]=n;
for(int i=1; i<=num; i++) sort(b+L[i],b+R[i]+1);
return;
}
inline void update(int l,int r,int w) {
if(pos[l]==pos[r]) {
for(int i=l; i<=r; i++) a[i]+=w;
init(l);
return;
}
for(int i=l; i<=R[pos[l]]; i++) a[i]+=w;
for(int i=L[pos[r]]; i<=r; i++) a[i]+=w;
init(l); init(r);
for(int i=pos[l]+1; i<pos[r]; i++) add[i]+=w;
}
inline int search(int x,int w) {
int l=L[x],r=R[x],mid;
while(l<=r) {
mid=(l+r)/2;
if(b[mid]<w) l=mid+1;
else r=mid-1;
}
return R[x]-l+1;
}
inline int ask(int l,int r,int w) {
int cnt=0;
if(pos[l]==pos[r]) {
for(int i=l; i<=r; i++) if(a[i]+add[pos[l]]>=w) cnt++;
return cnt;
}
for(int i=l; i<=R[pos[l]]; i++) if(a[i]+add[pos[i]]>=w) cnt++;
for(int i=L[pos[r]]; i<=r; i++) if(a[i]+add[pos[i]]>=w) cnt++;
for(int i=pos[l]+1; i<pos[r]; i++) cnt+=search(i,w-add[i]);
return cnt;
}
int x,y,w;
int main() {
scanf("%d%d",&n,&q);
for(int i=1; i<=n; i++) scanf("%d",&a[i]);
build();
for(int i=1; i<=q; i++) {
char c[5];
scanf("%s%d%d%d",c,&x,&y,&w);
if(c[0]=='M') update(x,y,w);
else printf("%d\n",ask(x,y,w));
}
return 0;
}
常见应用
- 处理多种其它普通数据结构难以处理的易理解简单区间操作(如区间根号和、区间众数等),可以使用懒标记且数据范围中等,在根号复杂度下可以通过()的场景;
- 复杂区间问题,实现简单且常数较小,如“区间查询值的个数和区间推平(珂朵莉树板子)”。
注意事项
- 分块的单次询问和修改的时间复杂度是 ,而非 。因此,除去常数,对比线段树、树状数组等数据结构,分块的效率较慢。只有必须使用分块而想不到更优的别的方法时,才需使用分块。
- 分块的懒标记通常用于块级别的批量操作(如区间加、区间赋值),需明确标记的含义(如“块内所有元素加 ”“块内所有元素被赋值为 ”),并在访问块内元素时优先应用标记(避免数据不一致)。注意多标记的优先级(如“赋值”会覆盖“加法”,需先处理赋值标记)。
- 在某些问题(如动态询问第 大)中,需要在每次添加或删除一个数字时,通过在相邻块的边界移动数字来重新分块。
- 上面讲的只是块状数组的思路,学有余力的读者可以阅读块状链表和树分块等内容。
树状数组
引入
仍然是一道简单的问题:逆序对。
给定长度为 的序列 ,请求出 。
,。
此题可以使用归并排序(CDQ 分治)来做。此处不介绍这种做法。
考虑合理转化题意。原题目其实相当于在求 。如果直接做,相对困难。如果使用一种类似于桶的值域上求法呢?
即,顺着扫一遍区间 ,对于 号元素统计大于 的值域个数,并将其累加至答案。问题是,值域规模过大。
我们考虑到此题中 数组中所有元素的值域 其实并不重要,因为只需要比对序列元素与元素的大小。于是,可以 离散化,只考虑其相对大小,题目条件变为 。这样,就可以在值域上做文章了:我们需要一种能够快速统计区间之和,并使单点点值增加 的数据结构。
事实上,这完美契合树状数组的特性 —— 树状数组支持 复杂度的单点修改和区间查询。
核心思想
树状数组是一种基于二进制分解的数据处理方法,用数组维护前缀运算(该运算需要满足结合律和可差分性)信息,通过
lowbit 函数快速定位更新和查询的位置,实现 的单点更新和区间查询。树状数组的下标从 开始, 表示特定区间的运算结果:对于 号点,其管辖的区间是 。其中
lowbit(x)=-x&x,代表一个十进制数在二进制表示法下最低位的 及其后面的 所构成的数值。
比如要维护一个序列的前缀和,各个节点的管辖节点如下:

此图中任意紫色方块 代表 ,并且一定满足 。
根据
lowbit 运算的性质,我们还可以发现: 中一定管辖 。利用这些特性,我们能轻松的完成许多任务。
核心操作
1. 单点更新:
add(x,k),代表将第 个元素加 。根据上文中数组元素的管辖关系,考虑通过
lowbit 向上更新父节点,步骤如下。- 第一步:初始令 。
- 第二步:。
- 第三步:。
- 第四步:如果 ,结束操作,否则回到第二步。
考虑到管辖一个节点的 个数一定不超过 ,所以单点修改的时间复杂度就是 。
2. 前缀和查询:
query(x),计算前 个元素的和,通过 lowbit 向下累加子节点。步骤如下:- 第一步:初始令 ,。
- 第二步:。
- 第三步:。
- 第四步:如果 ,结束操作,否则回到第二步。
3. 区间查询:只需要算出
query(r)-query(l-1),就能得到 的区间和。注意事项
- 再次强调,树状数组只能支持具有结合律和可差分的操作。如,区间和,区间异或,逆序对计数。而区间最值、区间众数等问题就无法使用树状数组的思想。
- 树状数组的核心是
lowbit运算,若下标从 开始,lowbit(0)为 ,会导致死循环。因此需将原数组下标统一偏移(如原 对应新 )。
例题解答
将序列 离散化后,按照值域 建立树状数组。
顺序扫 数组。每次扫到一个数字的时候,先计算当前的答案。注意到
ask(a[i]) 表示 所有元素中不大于 的元素个数,所以说 i-1-query(a[i]) 就是所有 对答案的贡献了。最后再将 插入树状数组。扫一个元素的时间复杂度为 ,总时间复杂度 。
代码
CPP#include<cstdio>
#include<algorithm>
using ll=long long;
using std::sort;
using std::lower_bound;
int s;
char ch;
inline int read() {
s=0;
while((ch=getchar())<48);
do s=(s<<3)+(s<<1)+(ch^48);
while((ch=getchar())>47);
return s;
}
int tot;
ll res,ans;
int n,a[500002],b[500002],t[500002];
inline int lowbit(int x) {
return -x&x;
}
inline void add(int pos) {
while(pos<=n) t[pos]++, pos+=lowbit(pos);
}
inline ll query(int pos) {
res=0;
while(pos) res+=t[pos], pos-=lowbit(pos);
return res;
}
int main() {
n=read();
for(int i=1; i<=n; i++) a[i]=b[i]=read();
sort(b+1,b+n+1);
for(int i=1; i<=n; i++) {
a[i]=lower_bound(b+1,b+n+1,a[i])-b;
ans+=i-1-query(a[i]);
add(a[i]);
}
printf("%lld",ans);
return 0;
}
常见应用
-
静态统计问题:逆序对、频率统计(如查询某个数出现的次数)、前缀和 / 后缀和查询;
-
动态更新问题:动态逆序对(支持单点修改)、实时频率更新(如添加 / 删除元素后查询频率);
-
二维扩展:二维树状数组,处理矩阵单点更新和子矩阵和查询(如 ) 矩阵,支持 加 ,查询 到 的和);
-
差分优化:区间更新 + 单点查询(如区间 加 ,查询某个位置的值),直接用树状数组维护差分数组即可。
事实上同时维护 个树状数组可以以 的时间复杂度完成区间修改、区间查询任务。
不过,如果要区修区查,还可以用一个更全能的数据结构 —— 线段树。
不过,如果要区修区查,还可以用一个更全能的数据结构 —— 线段树。
线段树
“忽略常数,凡是树状数组能够解决的问题,线段树一定能解决。”
“而线段树能解决的问题,树状数组不一定能够解决。”
“而线段树能解决的问题,树状数组不一定能够解决。”
线段树为什么这么厉害?它来源于一种非常典型的分治思路 —— 二分。
引入
给定长度为 的序列 (有初始值)与 次操作,类型如下:
1. 给定 ,查询区间 的最大子段和,即 。
2. 给定 ,将 修改为 。,,。
此题中,直接处理数据的时间复杂度是 ,即用贪心求最大子段和。这很明显过不去。
考虑如何优化。通常的数据结构都需要将原区间分成若干个小块,并在小块上处理。可以想象,如果要在小块上处理最大子段和,其值应该为下面两种中的一种:
- 最大的块中最大子段和。
- 最大的相邻部分的子段和之和。
可是,如何处理块内和相邻两块呢?我们可以考虑分治思想,即使用更小的块更新最大的块。这就是线段树,一种运用二分分治思想的数据处理方法。
核心思想
线段树将区间递归划分为左右子区间(直到叶子节点为单个元素),每个节点存储对应区间的信息(如总和、最值、计数),并能通过“分治 + 懒标记”实现 的区间更新和查询。只要能将两个区间的答案合并到一个区间中,就可以考虑使用线段树来维护。
具体地来说,线段树这棵递归树的节点编号和管辖逻辑如下:
- 号点的管辖区间是 。
- 对于 号点,其左儿子的编号是 ,右儿子的编号是 。
- 设某非叶子节点的管辖区间是 ,则其左儿子的管辖区间是 ,右儿子的管辖区间是 。
这样一来,每个非叶子结点都有一个左儿子和一个右儿子,这意味着我们可以快速访问任何区间段。
一张节点编号和管辖区间的示意图如下:
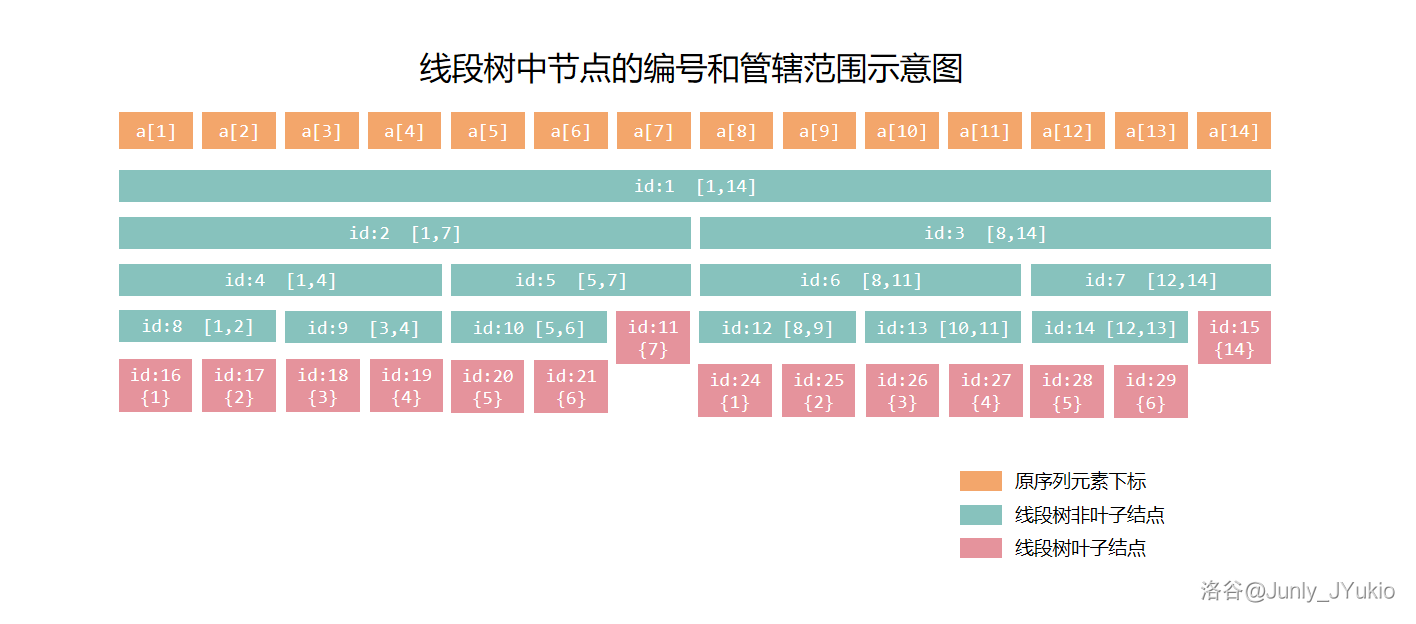
如图,如果要访问 ,就只需要访问大块 , 和 。类似与树状数组,我们也能想象在线段树上应该如何访问被包含的最大块:
1. 令 。
2. 对于每次访问:
- 如果当前管辖区间被 完全包含,就访问当前区间并返回。
- 如果 的左儿子中包含了 中的一段,就访问左儿子。
- 如果 的右儿子中包含了 中的一段,就访问右儿子。
- 值得注意的是,不可能既访问左儿子,又访问右儿子;否则其将被 包含,会直接返回。
因此,在这样的树上,修改靠懒标记,查询靠标记下放,其复杂度皆为 。
核心操作
下面我们将以区间修改 + 区间查询为例,了解朴素线段树的核心操作。
- 建树:递归划分区间,叶子节点存储元素值,非叶子节点合并子节点信息。
inline void build(int l,int r,int p) {
if(l==r) {
c[p]=a[l];
return;
}
int mid=(l+r)>>1;
build(l,mid,p*2);
build(mid+1,r,p*2+1);
c[p]=c[p*2]+c[p*2+1];
}
- 区间更新:
- 若当前节点区间与更新区间完全重合,更新节点信息并标记懒标记;
- 否则传递懒标记到子节点,递归更新左右子树。
inline void pushdown(int p,int l,int r,int mid) {
c[p*2]+=tag[p]*(mid-l+1);
c[p*2+1]+=tag[p]*(r-mid);
tag[p*2]+=tag[p];
tag[p*2+1]+=tag[p];
tag[p]=0;
}
inline void add(int l,int r,int s,int t,ll cc,int p) {
if(l>=s and r<=t) {
c[p]+=(r-l+1)*cc;
tag[p]+=cc;
return;
}
int mid=l+r>>1;
if(tag[p]) pushdown(p,l,r,mid);
if(s<=mid) add(l,mid,s,t,cc,p*2);
if(t>mid) add(mid+1,r,s,t,cc,p*2+1);
c[p]=c[p*2]+c[p*2+1];
}
- 区间查询:
- 若当前节点区间与查询区间完全重合,返回节点信息;
- 否则传递懒标记,递归查询左右子树并合并结果。
inline ll ask(int l,int r,int s,int t,int p) {
if(s<=l and r<=t) return c[p];
int mid=l+r>>1;
ll sum=0;
if(tag[p]) pushdown(p,l,r,mid);
if(s<=mid) sum+=ask(l,mid,s,t,p*2);
if(t>mid) sum+=ask(mid+1,r,s,t,p*2+1);
return sum;
}
例题解答
定义线段树中编号为 节点的管辖区间左端为 ,右端为 。
考虑在线段树中维护以下四个值:
考虑在线段树中维护以下四个值:
sum[x]表示 。left[x]表示 。right[x]表示 。ans[x]表示 。
容易发现转移关系:
CPPsum[x]=sum[l]+sum[r];
left[x]=max(left[lc],sum[lc]+left[rc]);
right[x]=max(right[rc],sum[rc]+right[lc]);
ans[x]=max(max(ans[lc],ans[rc]),left[lc]+right[rc]);
然后注意
left 和 right 是关键词,只需要 define 一下就好了。代码
CPP#include<bits/stdc++.h>
#define getchar getchar_unlocked
#define left lll
#define right rrr
using namespace std;
inline int read(){
int s=0,f=1; char ch=getchar();
while(!isdigit(ch)){if(ch=='-') f=-1;ch=getchar();}
while(isdigit(ch)){s=(s<<3)+(s<<1)+(ch^48);ch=getchar();}
return s*f;
}
const int N=2e6+5;
struct node{
int a,sum,left,right,ans;
}arr[N];
int n,m,k,xx,yy;
inline void push_down(node &p,node l,node r){
p.sum=l.sum+r.sum;
p.left=max(l.left,l.sum+r.left);
p.right=max(r.right,r.sum+l.right);
p.ans=max(l.ans,max(r.ans,l.right+r.left));
}
inline void build_tree(int l,int r,int p){
if(l==r){
arr[p].sum=arr[l].a;
arr[p].left=arr[l].a;
arr[p].right=arr[l].a;
arr[p].ans=arr[l].a;
return;
}
int mid=(l+r)>>1,ls=p*2,rs=p*2+1;
build_tree(l,mid,ls);
build_tree(mid+1,r,rs);
push_down(arr[p],arr[ls],arr[rs]);
return;
}
inline node ask(int x,int y,int l,int r,int p){
if(x<=l and r<=y) return arr[p];
int mid=(l+r)>>1,ls=p*2,rs=p*2+1;
node lss,rss,now;
if(y<=mid){
lss=ask(x,y,l,mid,ls);
return lss;
}
if(mid<x) {
rss=ask(x,y,mid+1,r,rs);
return rss;
}
lss=ask(x,y,l,mid,ls);
rss=ask(x,y,mid+1,r,rs);
push_down(now,lss,rss);
return now;
}
inline void change(int l,int r,int p){
if(l==r){
arr[p].sum=yy;
arr[p].left=yy;
arr[p].right=yy;
arr[p].ans=yy;
return;
}
int mid=(l+r)>>1,ls=p*2,rs=p*2+1;
if(xx<=mid) change(l,mid,ls);
else change(mid+1,r,rs);
push_down(arr[p],arr[ls],arr[rs]);
return;
}
inline void solve(){
k=read(); xx=read(); yy=read();
if(k==1){
if(xx>yy) swap(xx,yy);
printf("%d\n",ask(xx,yy,1,n,1).ans);
}
else change(1,n,1);
}
int main(){
n=read(); m=read();
for(int i=1; i<=n; i++) arr[i].a=read();
build_tree(1,n,1);
while(m--) solve();
return 0;
}
常见应用
- 各类区间操作(如区间加、区间乘、区间最值、区间求和);
- 结合自定义信息(如区间内不同元素个数),解决复杂统计问题。
注意事项
- 标记传播时需先更新子节点,再清空当前节点标记;如果不下传,会答案错误;如果不清空,会多次统计;如果顺序交换,就不会更新。
- 一棵朴素的线段树需要开 大小的空间,因为在最坏的情况下,线段树是一棵满二叉树,其右儿节点的编号较大。根据可靠的测试,在 的范围之内,最大需要开 倍的大小。根据数学证明,线段树中最大的权值确实最多有 的大小。综上所示,线段树的节点总数上限为 ,因此实际实现中通常开这个大小,以确保不会发生越界。这一结论适用于所有 的情况,是工程实践中经过验证的安全标准。
- 线段树能处理几乎所有区间问题(求和、最值、计数等),但常数比树状数组大(约 倍)。若问题可被树状数组解决(如区间和),优先用树状数组;若需复杂操作(如区间最值 + 区间加),再用线段树。
使用动态开点优化线段树
给定一个长度为 的序列,初始皆为 。请进行 次操作,每次操作有两种:
l r 1将区间 均变为 ,并且输出修改后序列中 的个数。l r 2将区间 均变为 ,并且输出修改后序列中 的个数。。
此题中,考虑按照下标建立线段树,并且每次都进行区修区查。但是问题在于, 的恐怖数据规模会让你连数组都开不起。
朴素的线段树需要开 倍空间。在动态开点线段树问题中,我们可以根据询问的数量重新计算需要访问的节点个数,再重新开某个大小的数组。例如在此题中,最坏情况下每次询问都需要访问 个点(线段树的重要性质之一)。这样一来, 次询问最多仅需访问 个点。
这就是动态开点线段树的思想。每个点的左右儿子节点不再是普通的 ,,而是由访问顺序动态决定的,并被记录至儿子节点数组 和 中。动态开点的步骤如下:
- 动态创建节点:访问节点时若不存在,创建新节点并初始化。
inline void change(int &p,int s,int t,int l,int r,int num){
if(!p) p=++sz; // p 点的编号变为 ++sz,即新开了一个点;p 点的取址使得每个点的左儿子和右儿子能够动态更新。
if(s<=l and r<=t){arr[p]=num*(r-l+1);tag[p]=num;return;}
int mid=l+r>>1;
pushdown(l,r,mid,p);
if(s<=mid) change(L[p],s,t,l,mid,num);
if(t>mid) change(R[p],s,t,mid+1,r,num);
arr[p]=arr[L[p]]+arr[R[p]];
}
- 区间查询:逻辑与普通线段树一致。若遇未被访问的点,通常直接跳过,因为其不会对答案造成任何贡献。
inline ll ask(int p,int l,int r,int s,int t) {
if(!p) return 0;
if(s<=l and r<=t) return c[p];
int mid=l+r>>1;
ll sum=0;
if(tag[p]) pushdown(p,l,r,mid);
if(s<=mid) sum+=ask(L[p],l,mid,s,t);
if(t>mid) sum+=ask(R[p],mid+1,r,s,t);
return sum;
}
这样一来,在例题中,我们就能用动态开点线段树轻松完成了。值得一提的是,本题中“所有点初始均为 ”的限制非常麻烦,所以我们可以将题目中的 和 进行颠倒。此时的 ,就是线段树中每个结点的初始值,系统可以自动完成。
代码
CPP#include<bits/stdc++.h>
#define getchar getchar_unlocked
using namespace std;
int s,f;
char ch;
inline int read(){
s=0,f=1; ch=getchar();
while(!isdigit(ch)){if(ch=='-')f=-1;ch=getchar();}
while(isdigit(ch)){s=(s<<3)+(s<<1)+(ch^48);ch=getchar();}
return s*f;
}
const int N=1e5*40+10;
const int M=1e7+5;
int opt,x,T,root,tot,L[N],R[N],sum[N*2]; // 动态开点,权值线段树
map<int,int> mp; // 前者是数字大小,后者是数列里该数出现的次数
inline void ins(int &p,int l,int r,int x,int num){
if(!p) p=++tot; // 开点
sum[p]+=num; // 先进行操作再判断找到没有
if(l==r) return; // 找到了
int mid=(l+r)>>1;
if(x<=mid) ins(L[p],l,mid,x,num);
else ins(R[p],mid+1,r,x,num);
}
inline int ask(int p,int l,int r,int s,int t){
if(s<=l and t>=r) return sum[p];
int ans=0,mid=(l+r)>>1;
if(s<=mid) ans+=ask(L[p],l,mid,s,t);
if(t>mid) ans+=ask(R[p],mid+1,r,s,t);
return ans;
}
inline int kth(int p,int l,int r,int k){
if(l==r) return l;
int now=sum[L[p]],mid=(l+r)>>1; // 通过左边儿子的个数判断应该走哪里
if(k<=now) return kth(L[p],l,mid,k);
else return kth(R[p],mid+1,r,k-now); // 走右边
}
int main(){
T=read();
while(T--){
opt=read(); x=read();
if(opt==1) mp[x]++,ins(root,1,M*2,x+M,1); // 单点修改
if(opt==2){
mp[x]--,ins(root,1,M*2,x+M,-1);
if(mp[x]==0) mp.erase(x); // 删除该数字
}
if(opt==3) printf("%d\n",ask(root,1,M*2,1,x+M-1)+1);
if(opt==4) printf("%d\n",kth(root,1,M*2,x)-M);
if(opt==5) printf("%d\n",(--mp.lower_bound(x))->first);
if(opt==6) printf("%d\n",(mp.upper_bound(x))->first);
}
return 0;
}
/*
这道题不需要使用序列原有的顺序,所以可以使用 map 像桶一样存储数字和其出现次数,大大减小码量
此时准备三个函数:一个单点修改,一个判断小于某个数的数字个数,一个kth,
此时如果使用二分算法就可以二分出 5,6 (前驱,后继)的答案
*/
动态开点线段树的思想非常单纯。其应用如下:
- 大范围区间操作(如数轴上的区间覆盖、离散化后的区间处理);
- 动态开点线段树还是可持久化线段树的基础结构。
线段树合并、线段树分裂
在题目需要时,合并两棵线段树而变为一棵或分裂一棵线段树成两棵的操作比较常见。
例如,板子题雨天的尾巴:
给定一棵树,树上的每个节点都有一个序列。你需要进行 次操作,每次操作给定三个正整数 ,你需要在树链 上的每个点的序列中都插入一个数 。
问若干次操作后,每个点所代表序列的众数是什么。如果存在多个众数,输出较小的那个。如果序列中没有数字,输出 。。
考虑树上差分。定义 表示点 的最近公共祖先, 代表 的直接父节点。则每个操作等价于:
- 给 的 类型加 。
- 给 的 类型加 。
- 给 的 类型减 。
- 若 不是根节点,则给 的 类型减 。
这样一来,通过后序遍历累加子树信息,即可还原每个节点的实际计数。
因此,我们需要维护的数据结构需要具备下面的功能:
- 可快速合并两个点的 类型。
- 可快速求出 中出现次数最多的类型。
如果使用哈希表或者朴素的桶来统计,明显 是无法承受的。
而虽然本题涉及“众数”,分块思想仍然无法解决。树上分块需首先将任意的路径 分解成 个块,再对块中的元素进行统计。如果再对 的值域分块,明显时间复杂度为 ,完全无法解决此题。
而虽然本题涉及“众数”,分块思想仍然无法解决。树上分块需首先将任意的路径 分解成 个块,再对块中的元素进行统计。如果再对 的值域分块,明显时间复杂度为 ,完全无法解决此题。
因此,考虑线段树。 的值很小(就算很大也能用离散化),所以放心开权值线段树。
但是如何合并两个线段树上所有的权值呢?考虑使用线段树合并和分裂算法。
线段树合并与分裂适用于动态维护多个集合的场景,顾名思义,需要快速完成以下两个内容:
- 合并:将两棵线段树的信息合并到一棵中(通常用于权值线段树),保留所有节点的累计信息;
- 分裂:将一棵线段树按特定规则拆分为两棵(如按权值范围拆分),确保拆分后信息完整。
其中,将线段树 合并至 的步骤如下:
- 对于两棵动态开点线段树 ,从 号节点开始。
- 如果 和 均为叶子结点,直接合并这两个点并退出;
- 如果 和 均有左儿子,递归至其左儿子;如果其中一个的左儿子为空,则直接返回另外一个的左儿子。
- 如果 和 均有右儿子,递归至其右儿子;如果其中一个的右儿子为空,则直接返回另外一个的右儿子。
inline int merge(int a,int b,int l,int r) { // 最后 a 即为合并后的新线段树
if(!a) return b;
if(!b) return a;
if(l==r) {
merge_node(a,b);
return a;
}
int mid=(l+r)>>1;
L[a]=merge(L[a],L[b],l,mid);
R[a]=merge(R[a],R[b],mid+1,r);
pushup(a);
return a;
}
关于线段树合并的时间复杂度(选自 OI-wiki)
显然,对于两颗满的线段树,合并操作的复杂度是 的。但实际情况下使用的常常是权值线段树,总点数和 的规模相差并不大。并且合并时一般不会重复地合并某个线段树,所以我们最终增加的点数大致是 级别的。这样,总的复杂度就是 级别的。当然,在一些情况下,可并堆可能是更好的选择。
将区间 从线段树 中分离(须保证 有序)的步骤如下:
- 从 开始递归进行分裂;
- 如果当前区间 被 直接包含,直接将该点 连接到 中;
- 如果当前区间 和 存在交集,就意味着之后必然会有点被连至新树,故要开一个新的点。
- 继续往下递归,进入和 存在交集的儿子节点。
inline void split(int &x,int &y,int l,int r,int pl,int pr){
if(!x or !sum[x]) return;
if(pl<=l and pr>=r){
y=x; x=0;
return;
}
y=++idx;
int mid=l+r>>1;
if(pl<=mid) split(lc[x],lc[y],l,mid,pl,pr);
if(pr>mid) split(rc[x],rc[y],mid+1,r,pl,pr);
pushup(x); pushup(y);
}
关于线段树分裂的时间复杂度(选自 OI-wiki)
线段树分裂中被断开的边至多只有 条,所以分裂的复杂度即为 。
在例题中,考虑将每个节点根据自身的差分标记,初始化一个线段树。之后,直接按后序遍历处理树,对每个节点 ,合并其所有子节点的线段树到 的线段树中。合并完成后,每个节点的线段树中存储了所有 类型的总计数,查询 即为答案。
代码
CPP#include<cstdio>
#include<vector>
#define N 100002
using std::vector;
int S;
char ch;
inline int read() {
S=0;
while((ch=getchar())<48);
do S=(S<<3)+(S<<1)+(ch^48);
while((ch=getchar())>47);
return S;
}
inline void write(int V) {
if(V>9) write(V/10);
putchar(V%10+48);
}
int n,m,fr,to,f[N][22],dep[N],rt[N],X,Y,Z,t,ans[N];
int res[N<<7],sum[N<<7],ls[N<<7],rs[N<<7],idx;
vector<int> vec[N];
inline void pushup(int x) {
if (sum[ls[x]]<sum[rs[x]]) {
res[x]=res[rs[x]];
sum[x]=sum[rs[x]];
} else {
res[x]=res[ls[x]];
sum[x]=sum[ls[x]];
}
}
inline int merge(int a,int b,int l,int r) {
if(!a) return b;
if(!b) return a;
if(l==r) {
sum[a]+=sum[b];
return a;
}
int mid=l+r>>1;
ls[a]=merge(ls[a],ls[b],l,mid);
rs[a]=merge(rs[a],rs[b],mid+1,r);
pushup(a);
return a;
}
inline void dfs(int x) {
dep[x]=dep[f[x][0]]+1;
for(int i=0; i<=20; i++) f[x][i+1]=f[f[x][i]][i];
for(int i=0; i<vec[x].size(); i++) {
if(vec[x][i]==f[x][0]) continue;
f[vec[x][i]][0]=x;
dfs(vec[x][i]);
}
}
inline int Lca(int a,int b) {
if(dep[a]<dep[b]) a^=b^=a^=b;
for(int i=20; i>=0; i--) {
if(dep[f[a][i]]>=dep[b]) a=f[a][i];
}
if(a==b) return a;
for(int i=20; i>=0; i--) if(f[a][i]!=f[b][i]) a=f[a][i], b=f[b][i];
return f[a][0];
}
inline void change(int &p,int l,int r,int s,int del) {
if(!p) p=++idx;
if(l==r) {
sum[p]+=del;
res[p]=s;
return;
}
int mid=l+r>>1;
if(s<=mid) change(ls[p],l,mid,s,del);
else change(rs[p],mid+1,r,s,del);
pushup(p);
}
inline void Arrange(int x) {
for(int i=0; i<vec[x].size(); i++){
if(vec[x][i]==f[x][0]) continue;
Arrange(vec[x][i]);
rt[x]=merge(rt[x],rt[vec[x][i]],1,N-2);
}
ans[x]=res[rt[x]];
if(sum[rt[x]]==0) ans[x]=0;
}
int main() {
n=read(), m=read();
for(int i=1; i<n; i++) {
fr=read(), to=read();
vec[fr].push_back(to);
vec[to].push_back(fr);
}
dfs(1);
while(m--) {
X=read(), Y=read(), Z=read();
t=Lca(X,Y);
change(rt[X],1,N-2,Z,1);
change(rt[Y],1,N-2,Z,1);
change(rt[t],1,N-2,Z,-1);
change(rt[f[t][0]],1,N-2,Z,-1);
}
Arrange(1);
for(int i=1; i<=n; i++){
write(ans[i]);
putchar('\n');
}
return 0;
}
警示后人
如果要使用
该代码中不能在
lca,则 dep 数组必须明确定义。该代码中不能在
dfs 函数中将 dep 更新搬到内层的 for 循环。否则,,界限不明确,可能就会让 lca=0。这就只有 分。可持久化线段树(主席树)
引入
例题:高级打字机
你有一个字符串 ,初始为空串。共有 次 种操作:
T x:在串末加入 这个字符( 为小写字母)。U x:撤销最后的 次修改操作(修改操作指T或U操作)。Q x:输出 (即字符串第 个位置的字符, 从 开始)。。
分析已知算法的局限性:
- 若用数组直接存储字符串 + 栈记录版本,
U操作可回溯版本,但Q操作需直接访问数组;但普通数组无法高效保留历史版本,栈仅能记录版本标识,无法支持随机位置查询。 - 若用链表存储,
Q x操作需遍历 个节点,时间复杂度 ,无法通过 数据。
此时需一种能保留历史版本且支持随机查询的数据结构,可持久化线段树(主席树)恰好契合:每个版本对应一棵线段树,存储当前字符串的字符分布,
T 操作生成新版本,U 操作回溯旧版本根节点,Q 操作查询指定版本的线段树。核心思想
可持久化线段树的本质是“保留线段树的历史修改轨迹”,每次更新时仅复制修改路径上的节点(其余节点复用旧版本),从而实现:
- 每个版本对应一个独立的根节点,通过根节点可访问该版本的完整线段树结构;
- 空间复杂度 (每次操作最多修改 个节点, 次操作共需 个节点);
- 版本查询与更新均为 复杂度。
以本题为例,线段树的每个叶子节点对应字符串的一个位置(如叶子节点 存储 ),非叶子节点仅用于划分区间:
T x操作:在第 个位置插入 ( 为当前字符串长度),生成新版本线段树;U x操作:直接复用 版本的根节点( 为当前操作次数);Q x操作:查询指定版本线段树的第 个叶子节点。
核心操作
1. 节点结构定义
CPPstruct Node {
int ls,rs;
char val;
} tr[2000005];
int root[100005],cnt;
2. 版本更新(插入字符)
CPPinline void update(int &now,int root_old,int l,int r,int pos,char val) {
now=++cnt;
tr[now]=tr[root_old];
if(l==r) {
tr[now].val=val;
return;
}
int mid=(l+r)>>1;
if(pos<=mid) update(tr[now].ls,tr[root_old].ls,l,mid,pos,val);
else update(tr[now].rs,tr[root_old].rs,mid+1,r,pos,val);
}
3. 历史版本查询
CPPinline char query(int now,int l,int r,int pos) {
if(l==r) return tr[now].val;
int mid=(l+r)>>1;
if(pos<=mid) return query(tr[now].ls,l,mid,pos);
else return query(tr[now].rs,mid+1,r,pos);
}
4. 版本回溯(撤销操作)
U x 操作无需修改线段树,仅需记录“当前版本”与“回溯后的版本”的映射:- 用变量 记录当前操作次数(初始为 0);
- 执行
U x时,新的 变为 (因当前U操作本身也是一次修改,需额外减 ); - 后续操作基于新的 版本根节点 。
例题解答
可持久化线段树的核心是“版本复用”,每个操作生成新根节点,仅复制修改路径上的节点,其余节点复用旧版本。此题中,这种思想可以极其轻松地使用。
代码
CPP#include<bits/stdc++.h>
#define getchar() getchar_unlocked()
using namespace std;
const int N=1e5+5;
int n,tot,root[N],idx;
inline int read() {
int s=0;
char ch=getchar();
while(!isdigit(ch)) ch=getchar();
while(isdigit(ch)) {
s=(s<<3)+(s<<1)+(ch^48);
ch=getchar();
}
return s;
}
char opt;
struct node {
int lc,rc,val;
char sum;
} T[N<<5];
inline void build(int &p,int l,int r) {
p=++idx;
if(l==r) {
T[p].sum=' ';
return;
}
int mid=l+r>>1;
build(T[p].lc,l,mid);
build(T[p].rc,mid+1,r);
}
inline int change(int p,int l,int r,char k) {
int now=++idx;
T[now]=T[p];
T[now].val++; // val 记录操作次数
if(l==r) {
T[now].sum=k;
return now;
}
int mid=l+r>>1;
if(T[T[p].lc].val<(mid-l+1)) T[now].lc=change(T[p].lc,l,mid,k);
else T[now].rc=change(T[p].rc,mid+1,r,k);
return now;
}
inline char query(int p,int l,int r,int k){
if(!p) return ' ';
if(l==r) return T[p].sum;
int mid=l+r>>1;
if(k<=mid) return query(T[p].lc,l,mid,k);
else return query(T[p].rc,mid+1,r,k);
}
char xx;
int main() {
n=read();
build(root[0],1,n);
for(int i=1; i<=n; i++) {
opt=getchar();
if(opt=='T') {
tot++;
getchar();
xx=getchar();
root[tot]=change(root[tot-1],1,n,xx);
getchar();
} else if(opt=='Q') {
putchar(query(root[tot],1,n,read()));
putchar('\n');
} else { // undo 操作中,只需要将原先版本的可持久化线段树子树复制过来即可
tot++;
root[tot]=root[tot-read()-1];
}
}
return 0;
}
/*
给定一个操作栈(?),需要进行以下操作:
T x 操作:s[++tot]=x
Q x 操作:输出s[x]
U x 操作:撤销最近的T和U操作
可持久化线段树
*/
注:代码中 len 的维护为简化版,实际竞赛中需额外数组 len_ver[now_ver] 记录每个版本的字符串长度,避免重复查询。
常见应用
- 历史版本查询:如查询“第 次更新后的区间最值”“过去某时刻的前缀和”;
- 静态区间第 k 大:基于权值线段树的可持久化,每个版本对应“前 个元素的权值分布”,查询 第 大时,用第 版本减去第 版本的权值计数;
- 可持久化数组:支持随机位置修改、历史版本查询(如本题的字符串维护)。
注意事项
- 空间分配:需预先估算节点数(通常为 , 为操作次数),避免 MLE;
- 版本号维护:确保每个操作对应唯一版本号,
U类回溯操作需精准计算目标版本号; - 节点复用:仅复制修改路径上的节点,未修改节点直接复用旧版本,避免冗余空间;
- 离散化:若处理大范围权值(如权值线段树),需先对权值离散化,减少线段树区间范围。
CDQ 分治
引入
例题:陌上花开
有 朵花,每朵花有三个属性:花型 、颜色 、香味 。定义“一朵花比另一朵花美”当且仅当 、、。求每朵花作为“被比美的花”时,有多少朵花比它美(即满足上述条件的 的个数)。,。
分析已知算法的局限性:
- 暴力枚举所有
pairs,复杂度 ,完全无法通过; - 二维偏序(如 且 )可通过排序 + 树状数组解决,但三维偏序无法直接用树状数组扩展;
- 平衡树套平衡树(树套树)可处理三维偏序,但实现复杂、常数大,易超时。
CDQ 分治通过“分治降维”将三维偏序拆解为多个二维偏序问题,大幅降低实现难度与时间复杂度。
核心思想
CDQ 分治的核心是“将问题拆解为三部分递归处理”:
- 左子问题:处理区间 内部的贡献(如左区间内花朵的相互比较);
- 右子问题:处理区间 内部的贡献;
- 跨左右子问题:处理左区间对右区间的贡献(如左区间花朵对右区间花朵的“比美”贡献)。
通过分治递归,将高维问题转化为“子问题 + 跨区间低维问题”,其中跨区间问题可通过排序 + 基础数据结构(如树状数组)解决。对于三维偏序问题,步骤如下:
- 先按 排序,确保左区间 均小于右区间 (消除 维度的影响);
- 分治处理左、右子问题;
- 对左、右区间按 排序,用双指针遍历右区间,将左区间中 小于当前右区间 的元素的 插入树状数组,再查询树状数组中 小于当前右区间 的个数(即左区间对当前右区间元素的贡献)。
总时间复杂度 (分治 层,每层排序 ,树状数组操作 )。
核心操作
1. 数据结构定义
CPPstruct Flower {
int a,b,c;
int cnt;
int ans;
} f[100005],tmp[100005];
int tree[100005];
int max_c;
2. 排序与去重
CPPinline bool cmp_a(const Flower &x,const Flower &y) {
if(x.a!=y.a) return x.a<y.a;
if(x.b!=y.b) return x.b<y.b;
return x.c<y.c;
}
inline int unique(int n) {
int m=1;
for(int i=2; i<=n; i++) {
if(f[i].a==f[m].a and f[i].b==f[m].b and f[i].c==f[m].c) {
f[m].cnt++;
} else {
f[++m]=f[i];
f[m].cnt=1;
}
}
return m;
}
3. 树状数组操作(维护 c 的前缀和)
CPPinline int lowbit(int x) {
return x&-x;
}
inline void add(int x,int val) {
for(; x<=max_c; x+=lowbit(x)) {
tree[x]+=val;
}
}
inline int query(int x) {
int res=0;
for(; x; x-=lowbit(x)) {
res+=tree[x];
}
return res;
}
inline void clear(int x) {
for(; x<=max_c; x+=lowbit(x)) {
if(tree[x]==0) break;
tree[x]=0;
}
}
4. CDQ 分治核心函数
CPPinline void cdq(int l,int r) {
if(l==r)return;
int mid=(l+r)>>1;
cdq(l,mid);
cdq(mid+1,r);
int i=l,j=mid+1,k=l;
while(i<=mid and j<=r) {
if(f[i].b<=f[j].b) {
add(f[i].c,f[i].cnt);
tmp[k++]=f[i++];
} else {
f[j].ans+=query(f[j].c-1);
tmp[k++]=f[j++];
}
}
while(i<=mid) {
add(f[i].c,f[i].cnt);
tmp[k++]=f[i++];
}
while(j<=r) {
f[j].ans+=query(f[j].c-1);
tmp[k++]=f[j++];
}
for(int x=l; x<=r; x++) {
f[x]=tmp[x];
clear(f[x].c);
}
}
例题解答
CDQ 分治通过“分治降维”处理三维偏序,步骤为“排序消去 维→分治处理左右子问题→双指针 + 树状数组处理跨区间贡献”。
代码
CPP#include<bits/stdc++.h>
#define N 100001
#define reg register int
//#define getchar getchar_unlocked
using namespace std;
int s=0;
char ch;
inline int read() {
s=0;
while((ch=getchar())<48);
do s=(s<<3)+(s<<1)+(ch^48);
while((ch=getchar())>47);
return s;
}
inline void write(int x) {
if(x>9) write(x/10);
putchar(x%10+'0');
}
struct node {
int x,y,z,w,res;
} a[N<<1],b[N<<1];
inline bool cmp(node A,node B) {
if(A.x!=B.x) return A.x<B.x;
if(A.y!=B.y) return A.y<B.y;
return A.z<B.z;
}
int n,m,k=1,ans[N],c[N];
inline void add(int x,int val){
while(x<=m){
c[x]+=val;
x+=((-x)&x);
}
}
inline int ask(int x){
int res=0;
while(x){
res+=c[x];
x-=((-x)&x);
}
return res;
}
inline void solve(int l,int r) {
// 边界条件
if(l==r) return;
// 分解子问题
int mid=l+r>>1;
solve(l,mid);
solve(mid+1,r);
// 集中处理排序结果
int i=l,k=l,j=mid+1;
while(i<=mid and j<=r) {
if(a[i].y<=a[j].y){
add(a[i].z,a[i].w);
b[k++]=a[i++];
}
else {
a[j].res+=ask(a[j].z);
b[k++]=a[j++];
}
}
while(i<=mid) add(a[i].z,a[i].w),b[k++]=a[i++];
while(j<=r) a[j].res+=ask(a[j].z),b[k++]=a[j++];
for(i=l; i<=mid; i++) add(a[i].z,-a[i].w);
for(i=l; i<=r; i++) a[i]=b[i];
}
int main() {
n=read(),m=read();
for(reg i=1; i<=n; i++){
a[i].x=read();
a[i].y=read();
a[i].z=read();
a[i].w=1;
}
sort(a+1,a+n+1,cmp);
for(reg i=2; i<=n; i++) { // 1.起到 Unique 作用;2.记录每个点产生的贡献。
if(a[i].x==a[k].x and a[i].y==a[k].y and a[i].z==a[k].z) a[k].w++; // 需要去重
else a[++k]=a[i]; // 可以更新下一位
}
solve(1,k);
for(reg i=1; i<=k; i++) ans[a[i].res+a[i].w-1]+=a[i].w;
for(reg i=0; i<n; i++) printf("%d\n",ans[i]);
return 0;
}
常见应用
- 高维偏序问题:如三维偏序(本题)、四维偏序(嵌套 CDQ 分治);
- 动态规划优化:如用 CDQ 分治优化 DP 转移(如“最长上升子序列”的 解法);
- 离线区间操作:如离线处理“区间加、区间求和”问题,将操作按时间分治,处理跨区间的影响。
注意事项
- 离线算法:CDQ 分治仅适用于离线问题,无法处理在线查询(如动态插入元素的偏序查询);
- 排序顺序:分治前需按某一维度排序,确保左区间对右区间的单向性(如本题按 排序);
- 去重优化:若存在重复元素,需先去重,避免重复计算贡献;
- 树状数组清空:分治每层处理完后需清空树状数组,避免影响上层递归(可用时间戳优化,无需每次 memset)。
整体二分
引入
例题:区间第 k 大
给定长度为 的序列 ,有 个查询,每个查询为 ,求区间 中第 大的数。,,。
分析已知算法的局限性:
- 在线算法(如可持久化权值线段树)可处理,但实现复杂度较高;
- 单个查询的二分(对每个查询二分答案,用树状数组统计区间内 的个数)时间复杂度 ( 为答案范围),,勉强可过,但常数较大;
- 整体二分将所有查询与元素一起二分,批量处理,降低常数,时间复杂度同单个查询二分,但实际运行更快。
核心思想
整体二分的核心是“将所有查询的答案一起二分”,通过“判定答案可行性”将操作划分为左右两组,递归处理:
- 二分答案范围:设当前答案区间为 ,取中点 ;
- 判定处理:用基础数据结构(如树状数组)处理所有元素和查询,判断每个查询的答案是否 (如本题中,统计区间 内 的个数,若 则答案 ,否则 );
- 划分操作组:将元素和查询划分为“答案 ”的左组和“答案 ”的右组;
- 递归处理:对左组递归二分 ,对右组递归二分 ,直至 ,此时 即为该查询的答案。
整体二分通过“批量判定”减少重复操作(如树状数组的插入和查询可一次性处理所有元素),核心优势是常数小、代码简洁。
例题解答
代码
CPP#include<bits/stdc++.h>
#define N 100005
#define reg register int
#define getchar getchar_unlocked
using namespace std;
char ch;
int s;
inline int read() {
s=0;
while((ch=getchar())<48);
do s=(s<<1)+(s<<3)+(ch^48);
while((ch=getchar())>47);
return s;
}
inline void write(int x) {
if(x>9) write(x/10);
putchar(x%10+'0');
}
struct queries {
char op;
int l,r,k;
} qu[N*2];
struct segmentTree {
int lc,rc;
int sum;
} T[N*400];
int n,m,a[N*4],b[N*4],rt[N*4],lent,idx,temp[2][20],cnt[2];
inline void change(int &p,int l,int r,int x,int val) {
if(!p) p=++idx;
T[p].sum+=val;
if(l==r) return;
int mid=l+r>>1;
if(x<=mid) change(T[p].lc,l,mid,x,val);
else change(T[p].rc,mid+1,r,x,val);
}
inline void add(int pos,int val) {
int num=lower_bound(b+1,b+lent+1,a[pos])-b;
for(int i=pos; i<=n; i+=(i&(-i))) change(rt[i],1,lent,num,val);
}
int query(int l,int r,int k) {
if(l==r) return l;
int mid=l+r>>1,sum=0;
for(reg i=1; i<=cnt[1]; i++) sum+=T[T[temp[1][i]].lc].sum;
for(reg i=1; i<=cnt[0]; i++) sum-=T[T[temp[0][i]].lc].sum;
if(k<=sum) {
for (int i=1; i<=cnt[1]; i++) temp[1][i]=T[temp[1][i]].lc;
for (int i=1; i<=cnt[0]; i++) temp[0][i]=T[temp[0][i]].lc;
return query(l,mid,k);
} else {
for (int i=1; i<=cnt[1]; i++) temp[1][i]=T[temp[1][i]].rc;
for (int i=1; i<=cnt[0]; i++) temp[0][i]=T[temp[0][i]].rc;
return query(mid+1,r,k-sum);
}
}
int ask(int l,int r,int k) {
memset(temp,0,sizeof temp);
cnt[0]=cnt[1]=0;
for (int i=r; i; i-=i&-i) temp[1][++cnt[1]]=rt[i];
for (int i=l-1; i; i-=i&-i) temp[0][++cnt[0]]=rt[i];
return query(1,lent,k);
}
int main(){
lent=n=read(),m=read();
for(reg i=1; i<=n; i++) b[i]=a[i]=read();
for(reg i=1; i<=m; i++){
cin>>qu[i].op;
if (qu[i].op=='Q') qu[i].l=read(),qu[i].r=read(),qu[i].k=read();
else qu[i].l=read(),b[++lent]=qu[i].r=read();
}
sort(b+1,b+lent+1);
lent=unique(b+1,b+lent+1)-b-1;
for(reg i=1; i<=n; i++) add(i,1);
for(reg i=1; i<=m; i++){
if(qu[i].op=='Q') printf("%d\n",b[ask(qu[i].l,qu[i].r,qu[i].k)]);
else{
add(qu[i].l,-1);
a[qu[i].l]=qu[i].r;
add(qu[i].l,1);
}
}
return 0;
}
常见应用
- 离线区间第 大 / 小:如本题的静态区间第 大,或带修改的区间第 大(需结合时间分治);
- 批量查询满足条件的个数:如“查询多个区间内大于 的元素个数”“查询多个点对的最短路径是否 ”;
- 带约束的计数问题:如“统计满足多个条件的元素个数”,通过整体二分将多条件转化为单条件判定。
注意事项
- 离线算法:需一次性读入所有元素和查询,无法处理在线插入 / 删除;
- 答案范围:初始答案范围需覆盖所有可能值(如本题需先求元素的 和 ),或对元素值离散化;
- 值调整:右组查询的 值需减去左组中满足条件的个数(如本题中,答案 时, 变为 );
- 树状数组优化:可用时间戳替代
memset清空树状数组(如记录每个位置的最后访问时间,未访问则视为 ),减少时间消耗。
平衡树(以 FHQ-Treap 为例)
引入
例题:普通平衡树
实现一棵普通平衡树,支持以下操作:
- 插入 数;
- 删除 数(若有多个相同数,只删除一个);
- 查询 数的排名(比 小的数的个数 + 1);
- 查询排名为 的数;
- 求 的前驱(小于 的最大数);
- 求 的后继(大于 的最小数)。
。
分析已知算法的局限性:
- 有序数组:插入 / 删除 ,无法通过;
- 二叉搜索树(BST):最坏情况下退化为链(如插入有序序列),所有操作 ;
- 平衡树(如 AVL、Splay):AVL 旋转复杂,Splay 实现繁琐;FHQ-Treap(无旋转 Treap)通过“分裂与合并”实现所有操作,逻辑简单、代码短。
核心思想
FHQ-Treap(无旋转 Treap)结合了二叉搜索树(BST)的有序性和堆的随机性,通过“分裂(Split)”和“合并(Merge)”两个核心操作实现所有平衡树功能:
- BST 有序性:每个节点的左子树所有值 ≤ 节点值,右子树所有值 ≥ 节点值;
- 堆的随机性:每个节点有一个随机优先级(pri),合并时优先级大的节点作为父节点,确保树的高度期望为 ;
- 分裂(Split):将一棵树按值或大小分裂为两棵树(如按值 分裂为“值 ≤ x”和“值 > x”的两棵树);
- 合并(Merge):将两棵树合并为一棵,需满足左树所有值 ≤ 右树所有值,且合并后仍满足堆的优先级性质。
所有操作(插入、删除、查询)均可通过分裂与合并组合实现,时间复杂度期望 。
核心操作
1. 节点结构定义
CPPstruct Node {
int ls,rs;
int key;
int pri;
int size;
} tr[100005];
int root,cnt;
2. 辅助函数(维护子树大小)
CPPvoid pushup(int x) {
tr[x].size=tr[tr[x].ls].size+tr[tr[x].rs].size+1;
}
3. 分裂(Split)
按值分裂:将树 分裂为 和 , 中所有值 ≤ key, 中所有值 > key:
CPPvoid split(int x,int key,int &l,int &r) {
if(!x) {
l=r=0;
return;
}
if(tr[x].key<=key) {
l=x;
split(tr[x].rs,key,tr[x].rs,r);
} else {
r=x;
split(tr[x].ls,key,l,tr[x].ls);
}
pushup(x);
}
按大小分裂:将树 分裂为 和 , 的大小为 , 的大小为 (用于查询排名为 的数):
CPPvoid split_size(int x,int k,int &l,int &r){
if(!x){
l=r=0;
return;
}
int left_size=tr[tr[x].ls].size+1;
if(left_size<=k){
l=x;
split_size(tr[x].rs,k-left_size,tr[x].rs,r);
} else{
r=x;
split_size(tr[x].ls,k,l,tr[x].ls);
}
pushup(x);
}
4. 合并(Merge)
CPPint merge(int l,int r){
if(!l ||!r)return l+r;
if(tr[l].pri>tr[r].pri){
tr[l].rs=merge(tr[l].rs,r);
pushup(l);
return l;
} else{
tr[r].ls=merge(l,tr[r].ls);
pushup(r);
return r;
}
}
5. 常用操作实现
CPPvoid insert(int x) {
int l,r;
split(root,x,l,r);
tr[++cnt]= {0,0,x,rand(),1};
root=merge(merge(l,cnt),r);
}
void erase(int x) {
int l,r,mid;
split(root,x,l,r);
split(l,x-1,l,mid);
mid=merge(tr[mid].ls,tr[mid].rs);
root=merge(merge(l,mid),r);
}
int get_rank(int x) {
int l,r;
split(root,x-1,l,r);
int res=tr[l].size+1;
root=merge(l,r);
return res;
}
int get_kth(int k) {
int l,r,mid;
split_size(root,k,l,r);
split_size(l,k-1,l,mid);
int res=tr[mid].key;
root=merge(merge(l,mid),r);
return res;
}
int get_prev(int x) {
int l,r,mid;
split(root,x-1,l,r);
if(!l) return-1e9;
split_size(l,tr[l].size-1,l,mid);
int res=tr[mid].key;
root=merge(merge(l,mid),r);
return res;
}
int get_next(int x) {
int l,r,mid;
split(root,x,l,r);
if(!r) return 1e9;
split_size(r,1,mid,r);
int res=tr[mid].key;
root=merge(merge(l,mid),r);
return res;
}
例题解答
代码
CPP#include<cstdio>
#include<cstdlib>
#include<algorithm>
using namespace std;
struct Node {
int ls,rs,key,pri,size;
} tr[1000005];
int root,cnt;
void pushup(int x) {
tr[x].size=tr[tr[x].ls].size+tr[tr[x].rs].size+1;
}
void split(int x,int key,int &l,int &r) {
if(!x) {
l=r=0;
return;
}
if(tr[x].key<=key) {
l=x;
split(tr[x].rs,key,tr[x].rs,r);
} else {
r=x;
split(tr[x].ls,key,l,tr[x].ls);
}
pushup(x);
}
void split_size(int x,int k,int &l,int &r) {
if(!x) {
l=r=0;
return;
}
int left_size=tr[tr[x].ls].size+1;
if(left_size<=k) {
l=x;
split_size(tr[x].rs,k-left_size,tr[x].rs,r);
} else {
r=x;
split_size(tr[x].ls,k,l,tr[x].ls);
}
pushup(x);
}
int merge(int l,int r) {
if(!l ||!r)return l+r;
if(tr[l].pri>tr[r].pri) {
tr[l].rs=merge(tr[l].rs,r);
pushup(l);
return l;
} else {
tr[r].ls=merge(l,tr[r].ls);
pushup(r);
return r;
}
}
void insert(int x) {
int l,r;
split(root,x,l,r);
tr[++cnt]= {0,0,x,rand(),1};
root=merge(merge(l,cnt),r);
}
void erase(int x) {
int l,r,mid;
split(root,x,l,r);
split(l,x-1,l,mid);
mid=merge(tr[mid].ls,tr[mid].rs);
root=merge(merge(l,mid),r);
}
int get_rank(int x) {
int l,r;
split(root,x-1,l,r);
int res=tr[l].size+1;
root=merge(l,r);
return res;
}
int get_kth(int k) {
int l,r,mid;
split_size(root,k,l,r);
split_size(l,k-1,l,mid);
int res=tr[mid].key;
root=merge(merge(l,mid),r);
return res;
}
int get_prev(int x) {
int l,r,mid;
split(root,x-1,l,r);
if(!l) return -2147483647;
split_size(l,tr[l].size-1,l,mid);
int res=tr[mid].key;
root=merge(merge(l,mid),r);
return res;
}
int get_next(int x) {
int l,r,mid;
split(root,x,l,r);
if(!r) return 2147483647;
split_size(r,1,mid,r);
int res=tr[mid].key;
root=merge(merge(l,mid),r);
return res;
}
int main() {
int n;
scanf("%d",&n);
while(n--) {
int op,x;
scanf("%d%d",&op,&x);
if(op==1) insert(x);
else if(op==2) erase(x);
else if(op==3) printf("%d\n",get_rank(x));
else if(op==4) printf("%d\n",get_kth(x));
else if(op==5) printf("%d\n",get_prev(x));
else if(op==6) printf("%d\n",get_next(x));
}
return 0;
}
常见应用
- 动态排名系统:如实现支持插入、删除的排行榜(如本题的 种操作);
- 区间操作:结合分裂与合并实现区间反转、区间平移(如 Splay 树的区间操作,FHQ-Treap 同样可实现);
- 平衡树套平衡树:外层平衡树按某一维度排序,内层平衡树处理另一维度,解决高维偏序问题(如二维矩形查询)。
注意事项
- 随机性:优先级需用随机数生成,避免恶意数据导致树退化为链;
- 空间分配:节点数组需预先分配足够空间(通常为操作次数的 倍);
- 分裂与合并的一致性:分裂后合并需保证树结构不变(如查询操作后需合并回原树);
- 重复元素处理:可在节点中记录相同值的计数(
cnt),避免重复创建节点,优化插入 / 删除效率。
写在后面
回头看这些进阶结构,其实都围绕着一个核心逻辑:用分治、二进制分解或版本保留的思路,把复杂操作拆解成可高效处理的单元。分块是“暴力的优雅平衡”,树状数组是“二进制的精准定位”,线段树是“分治的万能延伸”,而 CDQ、整体二分则是“离线问题的批量优化”,平衡树是“动态有序数据的灵活操控”。
它们没有绝对的优劣,只有“是否适配场景”的区别:
- 若操作简单、想快速写对,优先分块;
- 若只是单点更新 + 区间查询(求和 / 异或),树状数组是最优解;
- 若涉及复杂区间操作(最值、众数),线段树兜底;
- 若遇到高维偏序、离线 DP 优化,CDQ 分治更简洁;
- 若批量处理查询、追求常数优势,整体二分值得一试;
- 若需要动态维护有序数据(插入 / 删除 / 排名),FHQ-Treap 的“分裂 + 合并”逻辑最易上手。
最后想说,数据结构是解决问题的工具,而非目的。真正的竞赛高手,不是能背完所有结构,而是能在看到问题的瞬间,判断出“哪种工具能以最低的实现成本,达到所需的时空复杂度”。希望这篇总结能成为你工具箱里的“快速索引”,帮你在赛场上少走弯路,多留时间给更具挑战性的思维环节。
写完啦,完结撒喇叭。
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...