专栏文章
STL:rope
算法·理论参与者 15已保存评论 24
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 24 条
- 当前快照
- 1 份
- 快照标识符
- @mj7enu0q
- 此快照首次捕获于
- 2025/12/16 01:06 2 个月前
- 此快照最后确认于
- 2026/02/16 01:30 3 天前
关于 rope 的时间复杂度一直有争议,官方文档是描述为 ,可是实际表现并非如此。
声明
本文认为 rope 是 的。
rope 是什么
rope 是一个块状链表。可以做平衡树、可持久化等操作。
块状链表的劣势就是 查询(即使是单点)。
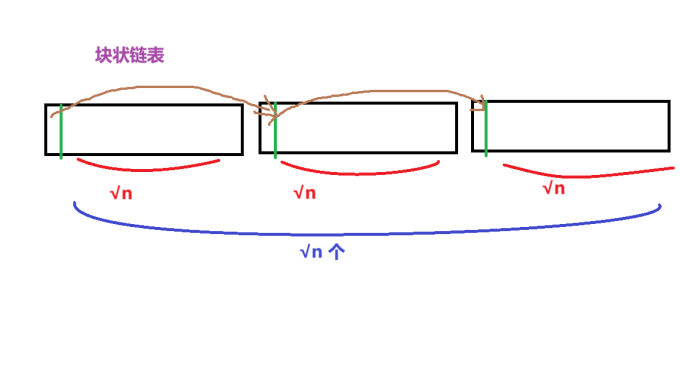
不过,手写的块状链表并没有 rope 快,因此不建议。
注明:rope 在 CCF 的大多数赛事中可以使用,笔者已经亲身试毒。
基础用法
引用
CPP#include<ext/rope>
using namespace __gnu_cxx;
或者
CPP#include<bits/extc++.h>
using namespace __gnu_cxx;
定义
与 vector 类似,
rope<type> 即可定义。rope<type> rp(100000) 可以定义一个大小为 的 rope。另外,
rope<char> 可以写为 crope。操作
这里只讲数组 rope 的使用方法。
在接下来的说明中,使用 作为一个 rope。
a.push_back(x):末尾插入 。该操作为 。a.insert(p,x):在 位置之后插入 。注意 rope 是从 开始的。a.erase(p,x):从 位置向后删除 个数。a.replace(x,y):等价于 ,即单点修改。a.append(x):同a.push_back(x)a.substr(p,x):从 位置向后截取 个数,并返回一个 rope。- rope 支持
clear(),empty(),begin(),end(),size()。 - rope 支持
for(auto i:a)格式的访问。
rope 强在哪里?
首先,rope 调用方法简单,比某 pbds 简单多了。
CPP__gnu_pbds::tree<int,null_type,less_equal<int>,rb_tree_tag,tree_order_statistics_node_update>t;
rope 是用来做可持久化的。因为 rope 的复制(即为
A=B, 都是 rope 类型)是 的。它只有在接下来有修改的时候复制。开 个满的 rope 并不会 MLE,如果只有单点修改的话,空间复杂度是小于 的。
rope 内部的可持久化是这样的:
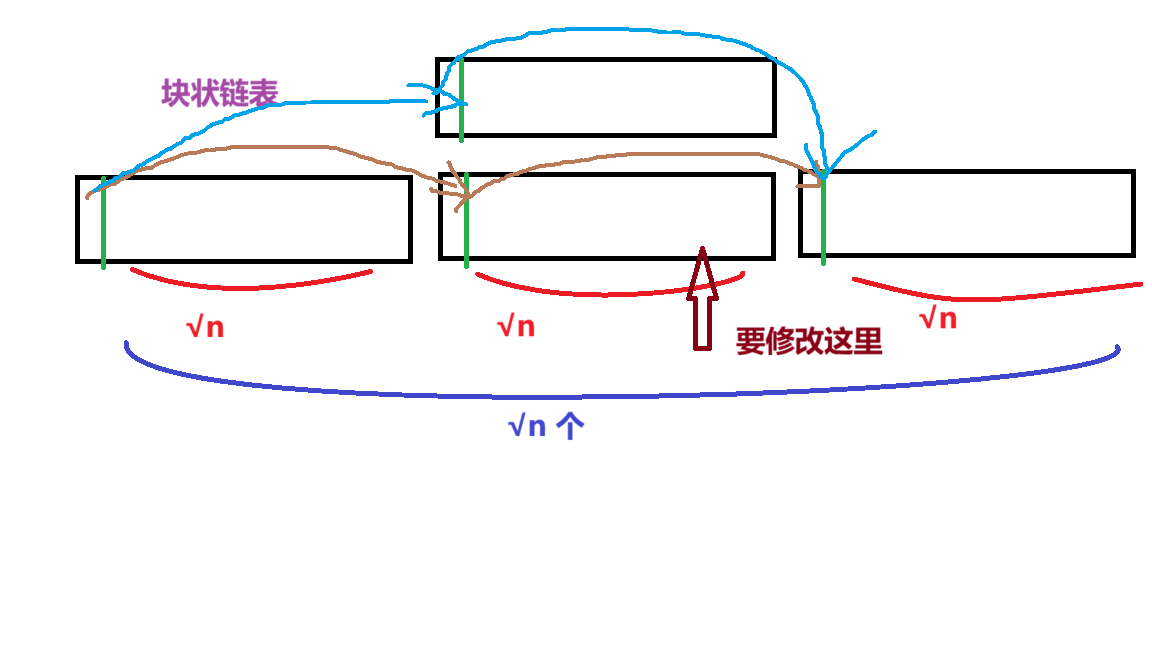
可以看到,这里多开了一个节点。
你可以把它理解成一个可持久化的数组。
同样,把线段树的数组换为 rope 即可做可持久化线段树,但是不建议,是 的。
例题:P1383 高级打字机
按照题意模拟即可。
| 对应的 rope 操作 | |
|---|---|
| Type | push_back |
| Undo | 回滚到 rp[x] |
| Query | rp[ver][x] |
以上还是简单的应用,接下来的可能有些玄学。
rope 的玄学运用(或许也是并查集的优化?)
笔者翻阅了网上的资料,发现这篇文章的代码并不是在线的,并且会被卡掉。
资料代码
CPP#include<bits/stdc++.h>
#include<bits/extc++.h>
using namespace __gnu_cxx;
using namespace std;
const int N=2e5+5;
int f[N],r[N],n,m,op,a,b,cnt1,cnt2,cnt3;
struct node{
int op,a,b;
};
inline int read()
{
int s=0,w=1;
char ch=getchar();
while(ch<'0'||ch>'9')
{
if(ch=='-') w=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9') s=(s<<3)+(s<<1)+ch-'0',ch=getchar();
return s*w;
}
int find(rope<int> &fa,int &i)
{
int f=fa[i];
return f==i?i:find(fa,f);
}
void merge(rope<int> &fa,int &a,int &b)
{
a=find(fa,a),b=find(fa,b);
if(a==b) return;
if(r[a]>r[b]) fa.replace(b,a);
else
{
if(r[a]==r[b]) r[b]++;
fa.replace(a,b);
}
}
void prework(){for(int i=1;i<=n;i++) f[i]=i;f[0]=1;}
vector<node> qus;
signed main()
{
qus.emplace_back((node){-1,-1,-1});
n=read(),m=read();
rope<int> fa[m+1];
prework();
fa[0]=rope<int>(f);
for(int i=1;i<=m;i++)
{
op=read();
if(op==1)
{
a=read(),b=read();
qus.emplace_back((node){op,a,b});
cnt1++;
}
else if(op==2) a=read(),cnt2++,qus.emplace_back((node){op,a,-1});
else
{
a=read(),b=read();
qus.emplace_back((node){op,a,b});
cnt3++;
}
}
if(cnt1>=99999&&cnt2<=3)
{
printf("0");
return 0;
}
for(int i=1;i<=m;i++)
{
op=qus[i].op;
if(op==1)
{
fa[i]=fa[i-1];
a=qus[i].a,b=qus[i].b;
merge(fa[i],a,b);
}
else if(op==2) a=qus[i].a,fa[i]=fa[a];
else
{
fa[i]=fa[i-1];
a=qus[i].a,b=qus[i].b;
printf("%d",(find(fa[i],a)==find(fa[i],b)?1:0));
putchar('\n');
}
}
}
同样,还有一篇题解的:
题解代码
CPP#include <bits/stdc++.h>
#include <ext/rope>
//#define int long long
#define endl '\n'
#define rint register unsigned
using namespace __gnu_cxx;
using namespace std;
#define IN stdin->_IO_read_ptr < stdin->_IO_read_end ? *stdin->_IO_read_ptr++ : __uflow(stdin)
#define OUT(_ch) stdout->_IO_write_ptr < stdout->_IO_write_end ? *stdout->_IO_write_ptr++ = _ch : __overflow(stdout, _ch)
const int N = 2e5 + 5;
unsigned f[N];
unsigned r[N];
void read(unsigned &x)
{
x = 0;
char ch = IN;
while (ch < 47)
ch = IN;
while (ch > 47)
x = (x << 1) + (x << 3) + (ch & 15), ch = IN;
}
unsigned find(rope<unsigned> &fa, unsigned &i)
{
unsigned f = fa[i];
return f == i ? i : find(fa, f);
}
void merge(rope<unsigned> &fa, unsigned &a, unsigned &b)
{
a = find(fa, a);
b = find(fa, b);
if (a == b)
{
return ;
}
if (r[a] > r[b])
{
fa.replace(b, a);
}
else
{
if (r[a] == r[b])
{
r[b]++;
}
fa.replace(a, b);
}
}
signed main()
{
unsigned n, m, op, a, b;
read(n);
read(m);
rope<unsigned> fa[m + 1];
for (rint i = 1; i <= n; i++)
{
f[i] = i;
}
f[0] = 1;
fa[0] = rope<unsigned>(f);
for (rint i = 1; i <= m; i++)
{
read(op);
switch (op)
{
case 1:
fa[i] = fa[i - 1];
read(a);
read(b);
merge(fa[i], a, b);
break;
case 2:
read(a);
fa[i] = fa[a];
break;
default:
fa[i] = fa[i - 1];
read(a);
read(b);
OUT(find(fa[i], a) == find(fa[i], b) ? '1' : '0');
puts("");
}
}
return 0;
}
这写代码都使用了快读或离线特判等方式。
而笔者的呢?
PS:这个帖子其实是我发的,我被【】了。
代码
CPP#include<bits/extc++.h>
using namespace std;
const int maxn=5e5+10;
int rk[maxn],T;
inline int read(){
int s=0,w=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') w=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9') s=(s<<3)+(s<<1)+ch-'0',ch=getchar();
return s*w;
}
int opt1,opt2,opt3;
struct DSU{
int ver=0;
__gnu_cxx::rope<int> fa[maxn];
void reset(int v,int n){
fa[v].push_back(1);
for(int i=1;i<n;i++)fa[v].push_back(i),rk[i]=1;
}
int find(int x){
if(fa[ver][x]==x)return x;
if(rand()%T==0)fa[ver].replace(x,find(fa[ver][x]));
return find(fa[ver][x]);
}
void merge(int x,int y){
ver++;
fa[ver]=fa[ver-1];
int fx=find(x),fy=find(y);
if(fx==fy)return;
//fa[fx]=fy
if(rk[fx]<=rk[fy])fa[ver].replace(fx,fy);
else fa[ver].replace(fy,fx);
if(rk[fx]==rk[fy]&&fx!=fy)rk[fy]++;
}
void back(int v){
ver++;
fa[ver]=fa[v];
}
bool group(int a,int b){
ver++;
fa[ver]=fa[ver-1];
return find(a)==find(b);
}
};
int main(){
// ios::sync_with_stdio(0);
// cin.tie(0);
int n,m;
n=read(),m=read();
DSU d;
T=sqrt(n)*log2(n);
d.reset(0,n+1);
while(m--){
int opt;
opt=read();
if(opt==1){
int a,b;
a=read(),b=read();
d.merge(a,b);
}
else if(opt==2){
int k;
k=read();
d.back(k);
}
else{
int a,b;
a=read(),b=read();
putchar(d.group(a,b)^48);
putchar('\n');
}
}
return 0;
}
时非常快。此时相当于 的概率进行路径压缩。这正与我发的帖子中的 接近。我当时只尝试了 这三个数。
这样使得由原来的 变为【神秘】。我也不会证啊。
不加任何快读,最慢点的是 。这已经是吊打优于同学的主席树的解法了。
UPD:实际上,将这种技术运用到可持久化线段树维护的并查集上并没有较大的优化,因为并查集本身的复杂度 并没有优于数据结构的复杂度 。之所以使用 rope 可以优化,是因为数据结构本身的时间复杂度(包括单点查询,
a[x] 也是)是 的,相比于并查集的 略劣。总结
总之,rope 是一种不太强但比较好用的 STL,它可以在特殊情况下替代可持久化数据结构。
相关推荐
评论
共 24 条评论,欢迎与作者交流。
正在加载评论...