专栏文章
题解:AT_abc232_g [ABC232G] Modulo Shortest Path
AT_abc232_g题解参与者 2已保存评论 1
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 1 条
- 当前快照
- 1 份
- 快照标识符
- @miq8ocd8
- 此快照首次捕获于
- 2025/12/04 00:46 3 个月前
- 此快照最后确认于
- 2025/12/04 00:46 3 个月前
思路来自于 @0x3b800001 的(稍改),但是我希望我能用更清晰的语言让大家理解。
这篇比较偏向萌新。因为作者也是萌新呀!
暴力
直接暴力建边,然后跑一遍最短路即可。
正解
观察一条边的边权: 的边权为 。
发现有取模操作,先考虑没有取模操作的特殊情况。
即: 的边权为 。
我们该如何建边?我们可以枚举 ,一旦 固定,那么不管你的 是什么, 就已经固定了。
此时,我们可以建立一个大节点 ,这个节点是 的中转节点。
我们可以让 节点先用 的边权连向 ,然后让 连向这些小节点 ,边权为 。这样拆分,就不用 的建图啦。
接着,再跑一遍 dijkstra,就可以结束了。
再考虑回一般情况。
我们还是一样,枚举 ,那么 就固定了,就只剩下 的事情了。
大家应该都知道,这个取模有两种情况:
- :值为 ,是我们考虑的特殊情况。
- :值为 。
因为 固定,如果我们将节点以 为关键字从小到大排序,那么肯定有:前一半部分是第一种情况,后一半部分是第二种情况。
于是我们就以 为关键字从小到大将节点排序。
此时,只使用节点 来进行连边就不够了。我们可以来一个前后缀节点,定义:
- 对于前缀节点 ,表示的节点是 这个整体。
- 对于后缀节点 ,表示的节点是 这个整体。
模仿特殊情况的连边方式,稍微改一改。
因为对于两个前缀节点 , 节点是覆盖 节点的整体的。
所以,我们可以让 ,如果大的节点行那小的节点也行,边权为 ;
同理,我们也可以让 ,边权为 。
对于一个节点 ,设 的节点是特殊情况, 的节点需要在特殊情况的基础下再减去 。也就是说, 的边权是 , 的边权是 。
至于从整体节点连到单个节点,不管是 的前缀节点 ,还是 的后缀节点 ,我们都令他的边权为 。
正确性:像我们之前说的,对于两个前缀节点 , 节点是覆盖 的整体的。假设我们现在需要到 节点,于是我们可以从 一直走到 ,然后再走到 。所以是正确的。
总结(上图,一图胜千言):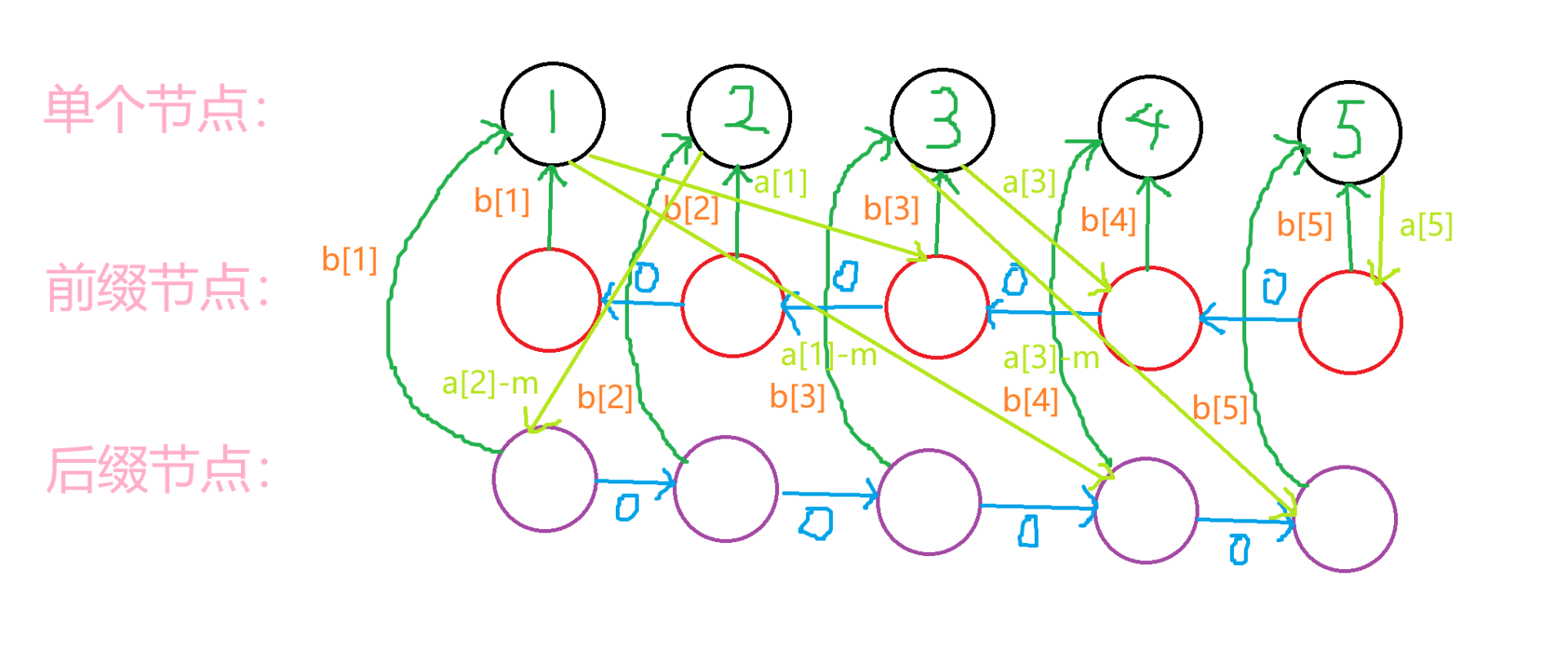
这个图只是举个例子,因为淡绿色的边不能污染了其他颜色的边,所以这里只举了部分连边例子。
但是我们发现:边权可能为负!
考虑怎么让边权变为自然数。我们发现,只有当单个节点连向后缀节点的时候,才会产生负数的边。
于是,我们考虑将 也一同加入。也就是说,我们的单个节点 连向的整体节点 的边权变成了 ,此时这个边权确实非负了。但是?如果后缀节点之间节点的连边边权还是 的话,就有问题。所以我们要调整一下这些边权。
于是,我们走一条边 ,因为我们当前 的贡献是 ,现在要变成 ,于是我们令这条边权为 。
这样,我们的 边的边权就不再需要考虑到 的贡献,直接赋值为 即可。
诶?等等? 数组是从小到大排序的?那这个边权不也是非负的嘛?
这不就完美解决了嘛?
上图(不再展示单个节点连向前缀节点的边):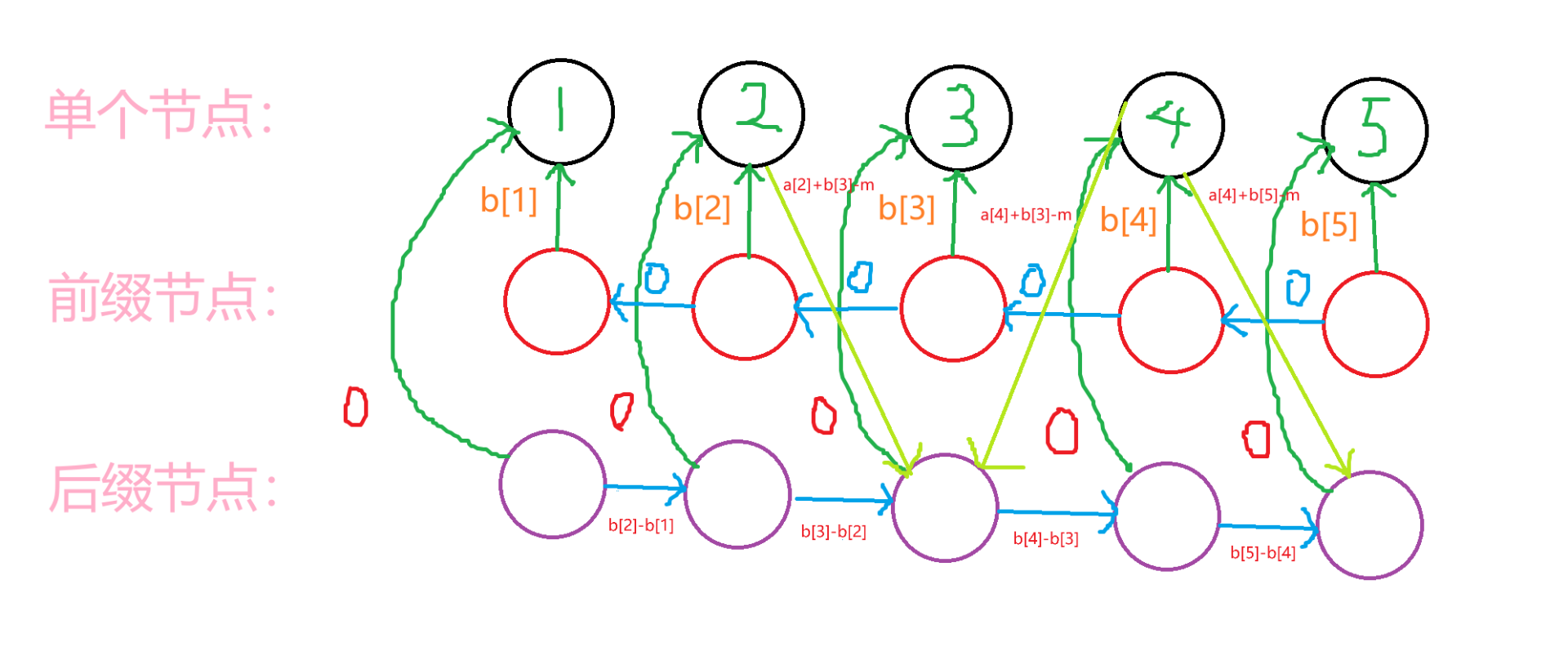
其中,红色的边强调该边权有更改。
代码(应该有可读性吧):
CPP#include<bits/stdc++.h>
#define x0 x_0
#define x1 x_1
#define y0 y_0
#define y1 y_1
#define yn y_n
#define j0 j_0
#define j1 j_1
#define k0 k_0
#define k1 k_1
#define d0 d_0
#define d1 d_1
#define LL long long
#define LD long double
#define ZPB push_back
#define ZPF push_front
#define US unsigned
using namespace std;
struct node{
int a,b,id;
bool operator < (const node &o)const{return (b!=o.b ? b<o.b : id<o.id);}
};
struct Enode{
int v;
LL w;
bool operator < (const Enode &o)const{return w>o.w;}
};
/*
[1,n]: real_node
[n+1,2n]: qjh_node
[2n+1,3n]: hjh_node
*/
node val[200010];
int n,m,st,ed;
const LL LLmex=1e18;
LL dp[600010];
vector<Enode> G[600010];
int main(){
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
cin>>n>>m;
for(int i=1;i<=n;++i) cin>>val[i].a,val[i].id=i;
for(int i=1;i<=n;++i) cin>>val[i].b;
sort(val+1,val+n+1);
for(int i=1;i<=n;++i){
if(val[i].id==1) st=i;
if(val[i].id==n) ed=i;
G[n+i].ZPB({i,val[i].b}),
G[(n<<1)+i].ZPB({i,0});
}
for(int i=2;i<=n;++i) G[n+i].ZPB({n+i-1,0});
for(int i=1;i<n;++i) G[(n<<1)+i].ZPB({(n<<1)+i+1,val[i+1].b-val[i].b});
for(int i=1;i<=n;++i){
int L=1,R=n,ans=n+1;
while(L<=R){
int mid=(L+R)>>1;
if(val[i].a+val[mid].b>=m) R=mid-1,ans=mid;
else L=mid+1;
}
if(ans>1) G[i].ZPB({n+ans-1,val[i].a});
if(ans<=n) G[i].ZPB({(n<<1)+ans,val[i].a+val[ans].b-m});
}
priority_queue<Enode> q;
for(int i=1;i<=(n<<1)+n;++i) dp[i]=LLmex;
dp[st]=0,q.push({st,0});
while(q.size()){
Enode dt=q.top();
q.pop();
int x=dt.v;
if(dp[x]<dt.w) continue;
for(int i=0;i<(int)G[x].size();++i){
int u=G[x][i].v;
LL w=G[x][i].w;
if(dp[u]>dp[x]+w) dp[u]=dp[x]+w,q.push({u,dp[u]});
}
}
cout<<dp[ed]<<"\n";
return 0;
}
相关推荐
评论
共 1 条评论,欢迎与作者交流。
正在加载评论...