专栏文章
NOIP2025 个人题解 - LCA
算法·理论参与者 97已保存评论 100
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 100 条
- 当前快照
- 3 份
- 快照标识符
- @miotrad2
- 此快照首次捕获于
- 2025/12/03 01:01 3 个月前
- 此快照最后确认于
- 2025/12/25 01:30 2 个月前
NOIP2025 个人题解
作者:LCA 蔡德仁 CommonAnts特别感谢助教 @_ 协助验证细节,写暴力等。
评
总体难度:
- T1 黄/绿
- T2 上位蓝/下位紫
- T3 黑
- T4 上位紫/下位黑
分项:
- T4 原题度偏高, 情况是 LOJ6490
- T3 需要一点注意力
- T2 T3 相对 NOIP 来说比较多数学细节硬推导,尤其是 T3
- T2 T3 T4 算法细节相对 NOIP 来说都比较多
- T4 相对 NOIP 来说代码细节比较多
T1 糖果店 / candy
思路和算法
如果 那么我们只会买最便宜的。带着这个直觉考虑奇偶性不同的情况。
每个糖果可以拆成两种糖果:
- 个数 ,价格 ,无限购买。
- 个数 ,价格 ,只能买一个。
对于只能买一个的这部分,既然个数都是 ,肯定是价格从低到高购买。
对于买两个的这部分,由于是无限的,我们只会买最便宜那种。记 最小的糖果为 ,若其他糖果购买了 颗,则将前两颗换为 一定不劣。
因此购买方案一定为购买了若干对糖果 ,然后再买每种糖果不超过一颗。将 从小到大排序,枚举每个前缀,计算购买一个这些糖果的答案即可。
时间复杂度 。
也可以视为背包, 表示买 颗糖最小总花费,进行 DP,也能发现对于总个数 的情况值直接等于 。
T2 清仓甩卖 / sale
思路和算法
对于一种定价方案,假设糖果已经按照性价比降序排序:
考虑最后一颗购买的糖果 ,若 , 则购买的糖果一定是全局性价比最高的若干颗,且要么 的买完了要么钱恰好花完了(否则会继续买 的)。此时一定是最优解。只有 ,才可能存在某种替换方案使得原价更高。
具体来说,设按顺序购买了糖果 这里 分别表示买的倒数第二个 的糖,买的总倒数第二个糖,以及买的最后一个糖(按上文讨论必须 )。可能 (买的最后两个都是 ),也可能 不存在(钱恰好剩 时 的买完了)。需要满足 。
设 表示性价比排在 后面没选的 的糖果里最大的。若 ,那么将 替换为 可以使原价总和更大,否则这种方案一定最优.
将 按性价比排序,枚举 ,此时让 的定价方案可以组合数计算,合法 的选择是一段后缀,双指针统计即可。
细节比较多,(买的最后两个都是 )以及 不存在(钱恰好剩 时 的买完了),注意讨论。好在计数题如果没讨论清楚可以在样例发现。
时间复杂度
T3 树的价值 / tree
思路和算法
这是个最优化问题,先考虑最优解长什么样。
观察、调整,可以得到几个基本结论:
- 不会有祖孙标同样的号。一个数字已经让它到根路径点的数字集合都有这个数了,祖先再这么干就浪费了。
- 不会有祖先比子孙标号小。在上一条基础上容易发现这一点。
- 每个点只有两种可能的决策,要么让自己的答案变大,要么给祖先产生贡献,否则肯定浪费。
- 进一步地,我们可以把每个点标为黑白两种颜色之一,分别表示答案变大( 比每个儿子的都大)的点以及答案不变大( 等于儿子的最大值)的点,然后自底向上决策。可以归纳证明对于特定的染色方案,最优解就是把每个白点分给祖先里最近的黑点(否则不如把最近的黑点也变白一起向上贡献),然后遇到黑点时它的 是子树内所有黑点 最大值加上分给它的白点个数再 (它自己的贡献。)。
明显可以自底向上递推,比如我们可以设计一个暴力 DP: 表示子树 中, 个贡献到 以上的白点,黑点 最大值为 的情况下最大子树内 总和。这可以优化转移到 的。有 到 分。
怎么优化呢?我们继续考虑最优解的结构,可以发现更多性质:
- 每个黑点必然有至少一个黑儿子。如果一个黑点 全是白儿子,我们找到它子树内所有黑点 最大的 ,通过重排分给 的白点可以让子树内黑点值都不变的情况下 到 路径都变成黑点,这一定更优。如果子树内全是白点则要么这个黑点本身变白更优,要么仍然前述更优。
- 所以,把每个黑点和它继承的黑儿子连起来,有一个链剖分结构。我们设每个点的重儿子是它所有儿子中 最大的那个,这也是它最大的黑儿子。
- 每个黑点都有黑色重儿子,所以链都是直通叶子的,每个链都是上白下黑。
- 可以发现每个黑点的 就等于它所属链往下的黑点个数,加上这些点的轻儿子向下连通的连续白点个数之和。白点的 等于重儿子的。
- 我们发现在这个链剖分结构上,贡献可以拆分给各个链。点的贡献,是祖先中第一个黑点在自己链的深度。所有贡献都可以在链之间的树上自底向上统计。
那么我们考虑改为这个状态 DP:尝试设 表示当前考虑了重链 和重链 所有子树的情况下的最优解。这个状态数(树上可能的祖孙链数)是 的,然而我们只能统计子树内祖先有黑点的点的贡献。
因此状态需要记录中间值 表示考虑了子树 ,并且 向上的贡献系数(祖先中第一个黑点在自己链的深度)为 情况下的最优贡献。转移时统计所有祖先中第一个黑点在 上的点的贡献。现在我们的目的是优化转移。
的转移需要枚举 链向下的第一个黑点,也就是枚举 向下到 的一条链。这条链的一个到 距离 的点分支出的孩子 的贡献是 ,然后 的值是所有 对应的值取最大值。这个可以用数据结构维护每种深度的贡献来统计。
时间复杂度:
使用长链剖分优化可以做到理论上 。
一开始的时候以为的 转移是想简单了。这个问题的确有子树 内在不知道其余部分的情况下可能成为最优子结构的本质不同极优解个数不超过 (子树大小和 到根深度)的性质。但是转移合并是链合并不是儿子合并,所以和树形背包的复杂度分析结论不同。直接维护转移的复杂度会退化到 ,只能得 分。能否继续挖掘子树最优决策性质,快速找到子树最优决策,从而优化枚举链的转移复杂度?比如说贪心微调或者决策单调性之类的?
T4 序列询问 / query
思路和算法
问题问的是:每个合法区间的区间和,分别贡献到区间内每个位置 上,问每个位置被贡献的最大值。其中,合法区间,指的是区间长度在给定范围内的所有区间。
数据范围允许 的时间复杂度,所以先不用考虑强行维护修改,还是先每次询问把每个 答案算出来。
那么这里关键的是所有合法区间的整体结构。画到平面上,可以发现是一个斜条带:
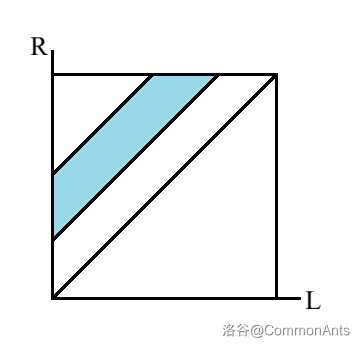
怎么统计这个呢?这种梯形区间集合是比较难统计的,我们统计只有一侧长度限制还行,两侧限制就比较难。所以划分一下:
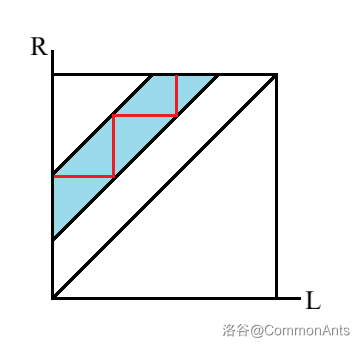
把合法区间集合划分成若干个三角形统计。这些三角形中每一个实际上都是两种形式之一:
- 某个给定区间 的子区间,且长度 。
- 某个给定区间 的超区间,且长度 。
这两种情况的贡献,可以枚举 和被统计的区间之差,这个差可以刻画为从 向内或向外两侧的前缀/后缀的贡献。我们直接枚举前缀,则对应的满足长度的后缀范围单调,双指针计算贡献和覆盖。
具体来说:
- 某个给定区间 的子区间,且长度 。
- 当 大于区间长度一半,设区间中点(或者第 个点也行)为 ,必经 。
- 对于这种情况,我们设一个要统计的区间是 。那么它可以被视为减去前缀 再减去前缀 再加上固定的 。后缀和前缀的总长度不超过某个定值。
- 首先预处理每个前缀和后缀的最小后缀和/前缀和。
- 枚举每个 ,查出这个 对应的所有可能 的最大区间和,并且贡献给 。
- 枚举每个 ,查出这个 对应的所有可能 的最大区间和,并且贡献给 。
- 再枚举每个 ,把上述 和 的贡献实际贡献到每个位置。
- 否则,每隔 个选一个关键点 ,区间至少经过一个关键点。枚举第一个经过的关键点统计区间,统计方法仍然类似。
- 分两种情况处理是为了保证 较大但 和区间长度差距小时,复杂度是正确的和区间长度减 同阶,而不是区间长度同阶。你也可以认为其实都是每隔 个选一个关键点,但处理方法还是要分类。
- 当 大于区间长度一半,设区间中点(或者第 个点也行)为 ,必经 。
- 某个给定区间 的超区间,且长度 。
- 对于这种情况,我们设一个要统计的区间是 。那么它可以被视为后缀 拼接上前缀 再加上固定的 。后缀和前缀的总长度不超过某个定值。
- 首先预处理每个前缀和后缀的最大后缀和/前缀和。
- 枚举每个 ,查出这个 对应的所有可能 的最大区间和,并且贡献给 。
- 枚举每个 ,查出这个 对应的所有可能 的最大区间和,并且贡献给 。
- 再枚举每个 ,把上述 和 的贡献实际贡献到每个位置。
- 把上面所有的贡献的最大值贡献给
时间复杂度和贡献区间个数是 的,也就是不超过图上红线段长度。所有小三角形加起来的红线段长度是 的,故总时间 。
然后算答案。上面的统计我们一共给出了 个贡献区间,现在还要对于每个位置计算所有覆盖它的贡献区间的最大值。直接枚举端点,单调栈维护即可。
总之这个问题的关键是采样法,即找到一些关键点,满足定长度限制的区间一定经过这些关键点,然后拆分前后缀进行统计。直接进行倍增采样(倍增值域分块)也可以做。
时有原题 LOJ6490,不过网上的题解通常带 。
注意统计过程中需要 查区间最值,这个 预处理一下就行。
题目能不能更优化呢?是困难的。输入一个长为 值域较大的数列,对于每个 求所有长度 区间和的最值,这个问题可以归约大值域单调序列 卷积(中间放一个巨大数保证选了,然后把两个序列底对底延伸两侧即可),目前不能多项式低于 次方。
时间复杂度:
采用较好的统计顺序可以不用维护任意区间最值查询,都改用单调队列等统计,可以改进到单纯的 时间。
题外话
知识点征集项目中 NOIP2025 T4 序列询问 / query 的技巧内容:
- R183. 带长度限制的区间统计(条状/梯形分治) - Guoyh ← liaoz123
- R276. 定长分块(定距采样法) - nzhtl1477
- R528. 倍增值域分块(倍增采样法) - 「佚名」
更多知识请看 知识点征集速报!!!! 第二期(2025.11.12-11.16) - 星语社Σ*
来参与征集! 有奖征集 OI 小知识点,思考题和科普
个人著作权声明:严禁任何未经本人(刘承奥,常用笔名/网名:蔡德仁 CommonAnts LCA liu_cheng_ao)书面授权者在梦熊联盟,或者任何虚假宣传或不实营销炒作或不正当竞争行为严重的 OI 机构的课程内或交流平台(包括但不限于品牌集训线下讨论,交流群,OJ,公众号,视频号等)上引用、传播、讨论此内容,以及本人于2024年5月及之后发布的所有内容,包括声明为公开的内容在内。
相关推荐
评论
共 100 条评论,欢迎与作者交流。
正在加载评论...