专栏文章
特殊结论 与 思维
个人记录参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @miobnth3
- 此快照首次捕获于
- 2025/12/02 16:34 3 个月前
- 此快照最后确认于
- 2025/12/02 16:34 3 个月前
1. 遇到二选一,或者某种互斥关系的,一般考虑建图。
- BSOI 13304 【8.11NOIP模拟】旋转 对向格子必须一边放,一边不放。
- BSOI 13319 【8.15NOIP测试】整数二元组 每对数必须选其中一个,不选另一个。
2. 斯特林数与 NTT
- BSOI 13320 【8.15NOIP测试】序列修改 中的 在 时为 。
待补 NTT 求斯特林数结论。
第二类斯特林数表:
第二类斯特林数表乘 :
观察技巧:
当 有其为 , 时为 , 时为 。
第一类斯特林数表:
3. 某一个变量范围比较小,然后又是求类似交/并的,考虑容斥反演。
-
某一道 AC 自动机 + 容斥的题目。
4. 遇到一些需要动态开点线段树的题目,考虑是否可以先进行离散化。
- BSOI 13316 【8.13NOIP模拟】网格染色 先将左右节点离散化再上线段树。
- BSOI 13321 【8.15NOIP测试】最小化 先将值域离散化后再线段树优化 DP。
5. 曼哈顿转切比雪夫: 映射到 那么则有 转为 。
-
BSOI 3185 「NOI模拟」图论科技 考虑转成切比雪夫距离再上费用流。
-
AT_arc076_b [ABC065D] Built? 受到启发:如果是最小曼哈顿生成树,考虑转化为切比雪夫,然后再考虑贪心。
6. 树链剖分相关的题目,建议将重心定为根,这样可以减少常数。
- P4751 【模板】动态 DP(加强版) 可以用重心当根。
- BSOI 13324 「NOIP模拟」树上的回忆 II 用重心当根,然后再加快读快写就会快不少。
7. 对拍去重
直接将其扔到
set 里面再拿出来。8. 多端点定序枚举问题的优化
即枚举一个序列 满足 ,这个复杂度是 ,但是实际上有一个 的常数,所以时间复杂度应该是 。
9. 差分转换
- ABC421G - Increase to make it Increasing 这里区间加,全局单调不降不好描述,把整个数组差分一下,就变成点对前面点加 ,后面点减 ,使得整个数组大于等于 。转为网络流模型。
- AGC006C - Rabbit Exercise 期望分析一下,变为单点进行这样的操作:。数形结合,相当于沿着 翻折。
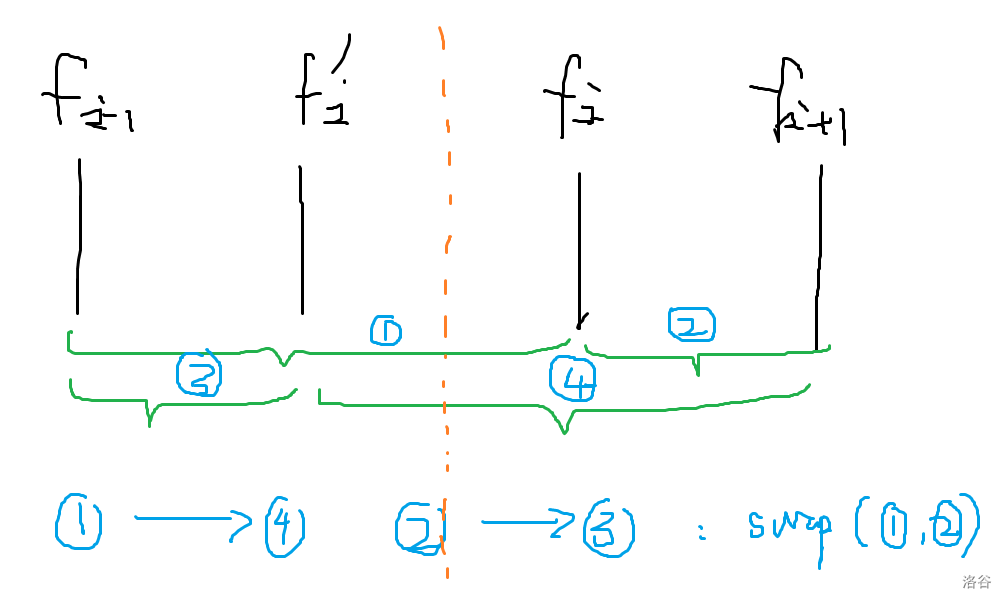
类似这样,相当于反转差分数组,然后我们考虑差分数组,就相当于每次反转相邻的两个位置。根据置换,可以用环大小来表示这个到达的位置。
10. 计数转概率/转期望
- ARC086C Smuggling Marbles 列出转移方程,用长链剖分优化。发现要维护一个全局乘的乘法标记,较难维护。我们考虑将对象从计数转为概率,一开始状态为计数每一层出现石子的情况数量,改为求每一层出现石子的概率。此时不用因为当前结点选还是不选将整个 DP 数组乘 。 原因是我当前结点选和不选,DP 数组对应的原计数对象的所有情况,都会出现相同次,换言之,我相当于用概率来把这个某个点乘 的贡献,转到了最后相乘。
11. 图论问题/排列问题和基环树森林
每个点恰有一条出边,是内向基环树森林;每个点恰有一条入边,是外向基环树森林。
- AT_agc008_e [AGC008E] Next or Nextnext 考虑建基环树森林并分类讨论。
12. 树上选路径问题的思路
P5021 [NOIP 2018 提高组] 赛道修建
树上选路径问题,首先考虑二分,然后从下往上贪心选边。
这里采用这样的贪心思路:对于一个结点,其所有儿子结点传上来的路径只有一条路径可以传到其父亲结点上。所以在儿子结点优先匹配两条断头的路径,一定比传上父结点要优。
原题中我们需要选出若干条长度 的路径,考虑怎么选最好,维护儿子传上来的所有路径长度的
multiset。- 先把所有 的路径计入答案并删除。
- 然后从小到大扫,对于一个 ,每次找到一个 使得 和 不是同一个元素并且 ,则把 同时删除,计入答案。
- 否则直接删除,作为最大值的一部分,将最大值传上父亲。
- 通过
multiset的begin()函数 找到最小值。
这里有个问题,为什么不能选最大值然后扫最小值?因为如果选最大值,有可能把传上父亲的
maxn 劣化了:比如现在 ,集合元素为 ,扫 会把 算到,然后传最大值为 。但如果扫最小值则不会有这样的问题。那为什么扫最小值是对的?我们的目的是,我们求出子树内最大的匹配次数,然后在此基础上使得传上去的值最大。从小到大扫最小值,可以保证如果当前 能匹配到 ,那就不存在比 小的 使得 (因为 在此之前已经扫过了,否则其一定可以在先前就将 匹配到)。所以选 匹配能够传上去的值保证最优。
AT_arc088_d [ARC088F] Christmas Tree
这里是,在保证每条路径均 下,使得路径数量最少,并能覆盖整棵树。
和上一题比较一下,“在保证每条路径 下,使得路径数量最多。”
这道题这样描述:把路径数量最少,转化成合并树边使得合并次数最多。
沿用上一题思路:维护
multiset 从大往小扫,每次对于最大的 ,找到最大的 使得 ,并删除 ,计入答案。把子树最小值传上去(没有则为 inf)。13. 指数分治
指数分治是一个常见的技巧,多用于一般复杂度无法接受的范围。更广泛地,当一道题目因复杂度瓶颈时,思考能否将某两半东西,取较小地部分枚举,快速算较大部分的值。
AT_abc423_g Small Multiple 2
枚举前后数字长什么样。朴素枚举是枚举后面的数字,在 枚举,其中 是满足 的最小 。其中等于 时一定存在解。
发现这样一个性质,考虑数位对数字的偏序关系,发现当 时,任意 位数一定比任意 位数大。既然 一定存在解,那么所以这个数数位不可能超过 。
引导我们对前后数字进行分治。
枚举后面的数,用 Exgcd 算出前面最小的值。
枚举前面的数,用取模算出后面最小的值。
最后比较可以这样,如果两个答案串中 在答案串位置,那么则直接比较数字大小。
最后只会剩下 个候选答案串,直接暴力比较即可。
其实这道题还有一个坑。
数据范围是 时,不一定与复杂度没有关系,有可能是根号分治/bitset 优化。
不要下意识认为其只是为了卡暴力/防止爆
long long。14. 排列枚举 ()
对称性排列枚举,考虑先枚举排列的匹配,然后再枚举其在排列一边的位置。这样复杂度是 的。关于如何枚举:首先在 DFS 时,假设 匹配,在枚举到 时往后枚举,并钦定 与 是一对匹配元素。
本质上,排列对称性与不同相对位置无关,例子就是 和 、 是一致的。
15. 三维偏序转二位偏序
考虑三维偏序转二维偏序:考虑能否去掉一维条件,使得另外两维自动推导到这一维条件;或者如果遇到对称分类讨论,比如绝对值等,可以考虑能否直接用两部分讨论式子直接拼凑出来,省去分类讨论。
比如:
满足这两个条件偏序。
朴素做法,考虑拆绝对值:
转为三维偏序:
发现没有必要这样,考虑 成立,又因为 则 一定成立。或者两个三维偏序中后两个条件都可以推导出前一个条件成立。
16. 加和字符串偏序
考虑对字符串新定义一种偏序,具体地对于 和 :
有如下性质:
-
其具有传递性,即对于 且 则 。所以可以排序。
- 证明考虑: 等价于 ,后者具有偏序关系,则前者具有。( 指 不断重复的串。)
- 考虑直接证明可以把小的串不断拼在后面,讨论其前缀相同时后面的相等性。
- 感性理解可以考虑这样,把两个串当作一个向量,拼在一起则是向量相加:
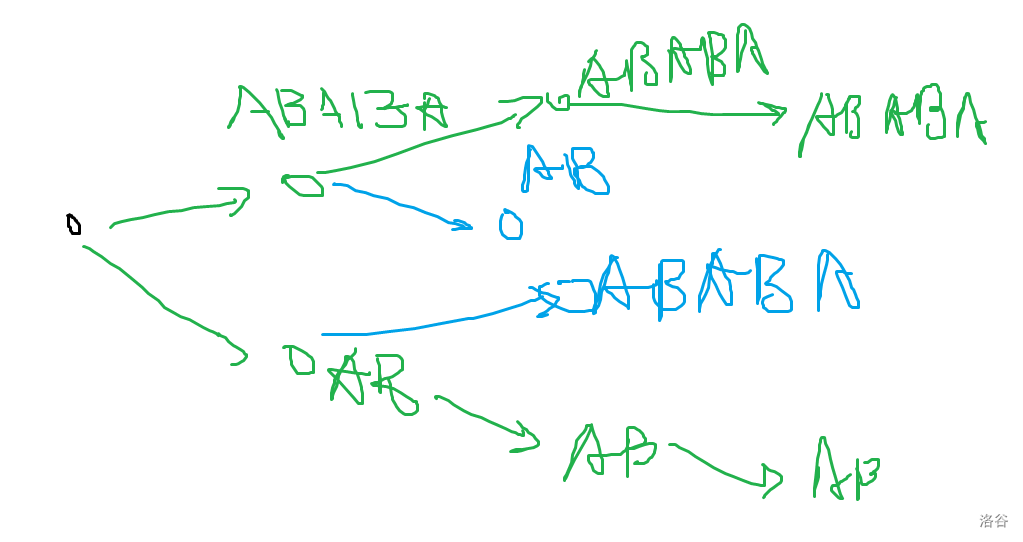
- 比如
ABABA和AB比较,考虑后面的向量的角度要比相同向量在前面的位置的角度要小,所以可以理解为后面向量对加和的向量的影响更小。考虑不断往两边走,等价于走一次之后往中间走,然后比较哪一个对向量的影响更大。 可以假想中间有一条线割开两边。 - 以后遇到一些向量的无限项加和的比较,并且后面的向量的影响越来越小,考虑能否把其交换一下,考虑前一个向量先导得更多。
- 就是
- 考虑
- 这个可以考虑优化复杂度。
- 也可以:
- 考虑
- 这个可以使比较式两边用同一种变量表示,考虑可以优化偏序关系、定序。
-
对于 个字符串按某种顺序拼接使得合成串字典序最小,等价于对这 串按 偏序排序。
-
证明考虑调整法。考虑两个 转为 一定不劣。冒泡排序最后可以转为上升段。
-
实际例题:AT_abc225_f。
-
17. 线性基异或和为 的方案数
根据打表发现,对于一个大小为 的线性基有 个自由元,则对于线性基能异或出来的 个数的每个数,都恰好有 种表示方法。所以一个线性基表述要么为 的自由元个数次幂,要么为 。
18. 一个 01 序列相邻删除相同/不同元素
考虑可以将偶数位翻转,那么现在就变为了删不同/相同元素,原理是每删除两个数,剩下所有元素的奇偶性不发生改变。 可以对正解有一定提示作用。
19. 若干个单调性询问考虑转二分为扫描线
如果若干个询问呈单调性,考虑不去二分,转为指针去扫一遍。
20. 树上问题一个点是否为另一个点的祖先
不要什么都想树剖,考虑 DFS 序是否包含/被包含。
所以这个题,考虑先二分答案,然后转为贪心选择大于等于前一项的最小值,在增加下标的同时维护一个 表示当前点是否可以选这个值,双指针增加 并检查这个点是否可以在 步到达。然后发现其实是基环树是否包含,如果是在同一个基环树内,先判断环上距离,然后再考虑
dfn-bot 是否包含,来 check 祖先关系。 用深度数组算出这个值即可。21. 。
如题。
22. Kruskal 重构树
-
两个点的最大边权最小路径中其中一个最大的点在两点 K 树的 LCA 上。
-
对于边权建 K 树考虑直接把边当作点,把边当作点,把边权当作点权。把点权用极大/极小值忽略掉即可。
-
一个图上,每个点有点权 。考虑求一个点游走,到达的点点权不能超过 的点中的最大点权。这恰好等于点权 K 树中 往上跳父亲跳到深度最小的使得 的最大 。
-
考虑这样证明:
-
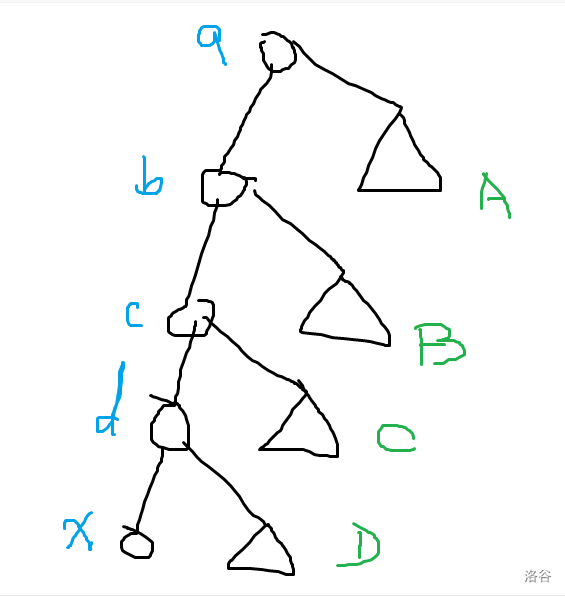
-
考虑 K 树性质,对于某个点对其权值为 LCA 的权值。那么对于一个点 不断往子树上爬父亲时,其兄弟子树的所有点到 的距离 恰好 等于当前父亲的权值。比如说从 爬到 ,那么从 到 的其它子树的所有点的权值都等于 的权值。
-
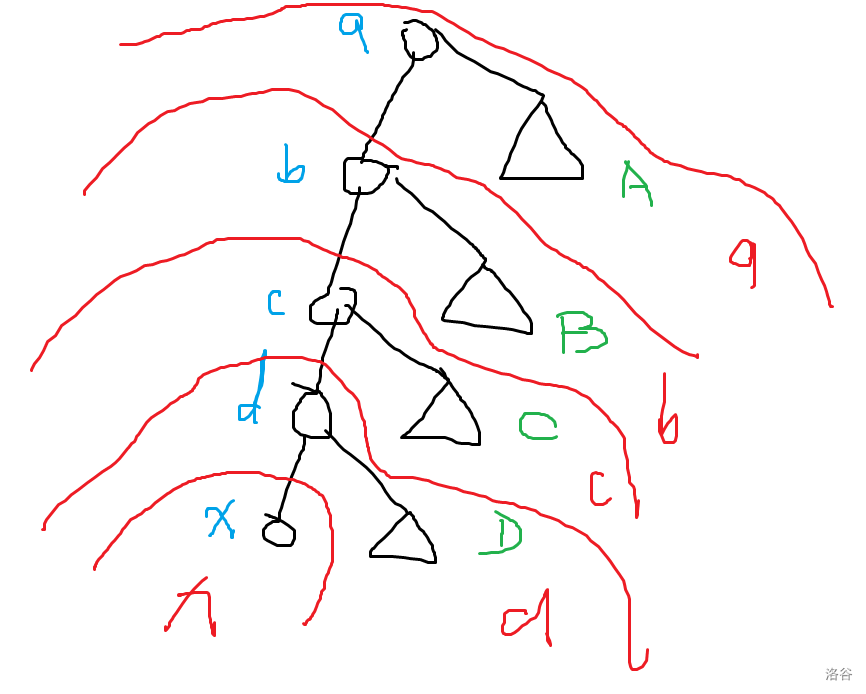
-
最终从 出发,到达其他点的路径最小权值恰好如 辐射状 往外散开,且每一部分以 的父亲作为割分,越往外权值越不优。(注意点权相同时,割分段不能直接用 LCA 来表示,而是一段连续段来表示。)
-
23. 点覆盖区间模型
最朴素的问题是:给出 个区间,然后选出若干个点,使得覆盖所有区间,且选出的点数量最少。
一个常见的贪心思路是:“右排左扫”,就是将其按右端点排序,然后从左边开始依次扫描到右边,每一次贪心选择该区间选不选,若需要选择,则选择这个区间的最右端。
考虑为什么要这样子做:发现对于一个区间,每次把要选区间的右端点 选择,等价于说:右端点小于 的已经用最优策略解决了,此时 又必须要选择,所以选择 是最优的。
这种贪心实际上在说这个:我用恰好 个点最多能覆盖多大的区间,希望最小化 使得右端点小于等于 的都被覆盖了。
某个点覆盖后,未覆盖的区间一定被分成了两部分。这就启发我们这个可以做区间 DP。
考虑设 表示将左右端点都在区间 的区间的答案。枚举区间的某个端点并强制选择其,分治到两边。
所以:点覆盖区间模型 的 一个偏序关系 是:对于 [l,r] 包含的区间构成一个偏序集。
也可以这么来理解,我当前选了之后,后面的区间会被割开变为两半,且分界点无交。这个同时可以在 DP 时用作,状态为在这里选择时的贡献。可以从上一次分割点转移,保证没有区间完全在两个分割点之间即可。
24. Ad-hoc 计数题中的 DP 状态优化
若干的子序列计数方法
25. 随机化技巧和骗分
这道题为什么场上没有做出来。发现第一个原因是 checker 写得不够简洁。
常见的子序列 DP 可以这样设置状态:以当前位置结尾的,计数以第一次出现时当前位置为结尾的子序列数量。DP 就是从 个字符转移。
转移类似于 ,。
答案为 。
也有将这个过程取反,那么就变为 ,,答案为 。
然后就会有线性的两种转移方法:
here。
一种是前缀优化,设 表示以 结尾且之前没出现过的子序列个数,那么 。
另一种是容斥,设 表示前缀的答案,发现当前的贡献为 ,但是会算重已经算过的部分为 ,减去。然后加上自己这一位置的贡献。
但是发现这个也不行。
这样才行。就是算 表示在 到 的子序列以 结尾的数量。然后发现当前这个结点首先只会对 有影响。考虑转移,要么前面为 为 ,要么为 为 ,要么单独开一个为 。所以:,
考虑刻画为向量则为:现在有两个数 :一开始全为 ,然后每一次要么 ,要么 。一种方法是整体替换,把 写成 然后就变为 ,发现是更相减损法。
考虑如果没有发现可以整体替换(把 写成 然后就变为 )的时候能否做?讨论一下,其实可以直接减去即可。
26. 数据结构维护,考虑独立的操作能否分别维护
考虑操作 1 和 2 可以分开。如果某个思路断了的时候,考虑能否用两个数据结构分开维护。
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...