对于
F(x)=a0+a1x+a2x2+.... 和
G(x)=b0+a1x+a2x2+....,我们现在想做一件事情,就是把它们两个乘起来。
千里之行始于足下。任何一个伟大的思想,都有一个微不足道的开始。
首先我们意识到对于
n 次的多项式有
n+1 个系数,如果我们有
n+1 个类似于
(xi,F(xi))的点后,我们能算出这
n+1 个系数。
具体的原因(可省略不看),是
A=x10x20⋮xn+10x11x21⋮xn+11⋯⋯⋯x1nx2n⋮xn+1n=1≤i<j≤n+1∏(xi−xj)=0
设多项式
F(x) 系数构成的列矩阵为
b,代入
x1 到
xn+1 这
n+1 个数形成的结果的矩阵为
B而该矩阵
A,显然有
A∗b=B,那么我们就能反推
b=A−1∗B (只要
det(A)=0 ,
A−1 就存在)
也就是说,这
n+1 个点保存了该多项式所有的信息。
那么,对于这
n+1 个点的选取,为了保证能够在
nlogn 的时间内算出它们对应的
F ,我们选的是如下的数字。
首先,把
n 次多项式变成
2k−1 次多项式(高次系数自动补
0),这样我们需要代入
2k 个数。然后令
ω 为满足
ω2k=1 且
ω=1 的辐角最小的
ω,根据欧拉公式,我们有
ω=cos2k2π+sin2k2πiF(x)=a0+a1x+a2x2+⋯+a2k−1x2k−1=(a0+a2x2+⋯+a2k−2x2k−2)+x(a1x+a3x3+⋯+a2k−1x2k−1)
然后我们分别把
ω0,ω1,⋯,ω2k−1 代入。使用的是分治法。
F(x)=a0+a1x+a2x2+⋯+a2k−1x2k−1=(a0+a2x2+⋯+a2k−2x2k−2)+x(a1+a3x2+⋯+a2k−1x2k−2)
设
F1(x)=a0+a2x+⋯+a2k−2x2k−1−1,
F2(x)=a1+a3x+⋯+a2k−1x2k−1−1那么
F(x)=F1(x2)+xF2(x2)也就是说,我们只要求出
ω2,ω4,⋯,ω2k−2,也就是所有满足
ω22k−1=1 的
ω2 代入进去的值。而这对应的是
2k−1−1 次的多项式。对比我们进来要处理的多项式,这里直接少了一半!
子问题求解完毕以后,依次把
x 和对应的
F1(x) 和
F2(x) 代入即可求出
F 对应的
2k 个点值。
对于函数
F 和
G,都进行这样的操作。需要注意的是,由于
F∗G 的次数是
F 和
G 的次数总和,所以选择的
k 应当不小于
F 和
G 的次数总和。
我们把
F 和
G 求得的点值,按照横坐标对应相乘,得到的是
F∗G 的
2k 个点值。
至于如何把这
2k 个点值转换成系数。还是明天在看吧
⋯ 你先是打开了手机上的游戏。
副本模式开启,规则:接下来讨论的矩阵,行坐标和纵坐标都是从
0 开始。
嗖的一下,你的脑子里闪出了这个声音。奇怪,刚进来怎么就成副本模式了?
你一定要记得它,方能在该世界的重重迷雾中拨云见雾!
又是一道声音响起。
A=11⋮11ω1⋮ωn1ω2ω2n⋯⋯⋮⋯1ωnωn2
和
B=11⋮11ω−1⋮ω−n1ω−2ω−2n⋯⋯⋮⋯1ω−nω−n2
的乘积,是
diag(2k,2k,⋯,2k)你的脑海高速运转,手中的笔出现了重影,在纸上密密麻麻写下了证明
Ai,j=ωij,Bi,j=ω−ij
则
Ci,j=k∑Ai,kBk,j=k∑ωikω−kj=k∑ω(i−j)k而这个式子,你心想,如果
i=j 的时候,好说。那
i=j 的时候呢?
这时,你想到了
ω2k−1=(ω−1)(ω2k−1+ω2k−2+⋯+1)=0又
ω=1,所以
ω2k−1+ω2k−2+⋯+1=0,真是天助我也!
至于
(i−j) 的问题
⋯其实相对于上面的思考来说相对是比较显然的,于是你赶忙写下了显然二字,然后自信地把这张纸递给了身边的使者。
恭喜你完成了任务!
你回到了主世界。
如果令
E 是单位矩阵,我们发现
AB=2nE,也就是
B=2nA−1,也就是说
B 能够将点值重新变换到系数上面去!
你对这个结果感到非常满意,而它在代码中的体现,则是把
ω 的
k 次方,变成了
−k 次方,只需要该一个点就行了(也就是把纵坐标取相反数)
const double Pi=acos(-1);
struct CP
{
double x,y;
CP (double xx=0,double yy=0){x=xx,y=yy;}
CP operator + (CP const &B) const
{return CP(x+B.x,y+B.y);}
CP operator - (CP const &B) const
{return CP(x-B.x,y-B.y);}
CP operator * (CP const &B) const
{return CP(x*B.x-y*B.y,x*B.y+y*B.x);}
}f[Maxn<<1],p[Maxn<<1],sav[Maxn<<1];
void fft(CP *f,int len,bool flag){
if (len==1)return ;
CP *fl=f,*fr=f+len/2;
for (int k=0;k<len;k++)sav[k]=f[k];
for (int k=0;k<len/2;k++)
{fl[k]=sav[k<<1];fr[k]=sav[k<<1|1];}
fft(fl,len/2,flag);
fft(fr,len/2,flag);
CP tG(cos(2*Pi/len),sin(2*Pi/len)),buf(1,0);
if (!flag)tG.y*=-1;
for (int k=0;k<len/2;k++){
sav[k]=fl[k]+buf*fr[k];
sav[k+len/2]=fl[k]-buf*fr[k];
buf=buf*tG;
}for (int k=0;k<len;k++)f[k]=sav[k];
}
int main()
{
scanf("%d%d",&n,&m);
for (int i=0;i<=n;i++)scanf("%lf",&f[i].x);
for (int i=0;i<=m;i++)scanf("%lf",&p[i].x);
for(m+=n,n=1;n<=m;n<<=1);
fft(f,n,1);fft(p,n,1);
for(int i=0;i<n;++i)f[i]=f[i]*p[i];
fft(f,n,0);
for(int i=0;i<=m;++i)printf("%d ",(int)(f[i].x/n+0.49));
return 0;
}
这是我们的第一版代码,
 模板题
模板题会被卡掉两个点,不够优秀。
一个常数优化,是我们发现
26,27 行的 buf*fr[k] 出现了两次,复数的乘法是很吃时间的。所以我们可以把它们两个补到一起。
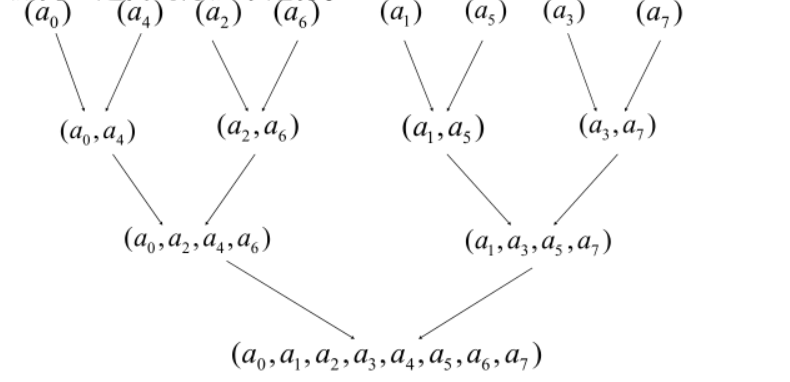
再者,我们 FFT 函数的框架是递归。但是递归的方法对空间的要求很高,从原代码可以看到每次递归调用时都需要新的系数数组传入递归过程内部。因此我们自然想到是否可以用非递归,即从底向上迭代的方法来计算。我们观察一下 FFT 时系数变动到的位置,应当如下图所示。
假设
ai 最后移到了位置
ri
用数学归纳法可以得出
r2i=21r[i],r2i+1=r2i+21n
我们预先把
ai 移到位置
ri,然后自下而上去迭代计算,能够大大提高程序效率。
这个优化便叫做蝴蝶效应
但是我们发现
FFT 依赖复数,精度会产生误差(我反正被卡过),所以我们需要找一个东西来替代原先的单位根
ω我们上面对
ω 用到的性质,好像就只要求对于最大的
k,有
ω2k=1 且
ω0,ω1,⋯,ω2k−1 互不相同且
ω=1。其他的应该都能从这三个性质里推出来(当然前提是在实数域里面)
很遗憾,在实数域里面
ω=cos2k2π+sin2k2πi 是唯一满足条件的。
但是,由于OI是由无数OI爱好者开发的基于模的游戏……等下,模?
你好像意识到了什么。
特别的,我们有
998244353=7×17×223+1,里面有你最喜欢吃的
2!这个和
2k 是不是很搭啊!
3 是
998244353 的原根,也就是说,
(3119)223≡1(mod998244353)
更一般的,我们考察一个质数
p 和它的一个原根
g,有
gk 关于
p 的阶
ordp(gk)=(k,p−1)p−1要让它等于某一个满足
r∣p−1 的
r,只需要令
k=rp−1 即可!
而当
p=998244353 时,
p−1 能分解出大量的因子
2,正好能满足我们 FFT 的需求!
*拓展:不用原根的方法
一般的,我们有质数
p 满足
p−1=s∗2r (
s 是奇数)
随机出一个二次非剩余
v,根据其定义,不存在
x 使得
x2≡v(modp),并且由于
(v,p)=1,
v 可被表示成
gk 的形式,显然
k 为奇数。
如此,
ordp(vs)=ordp(gks)=(p−1,ks)p−1=(s∗2r,ks)s∗2r=(2r,k)2r=2r因此,
(vs)n2r 就是 关于
p 的
n 阶单位根
这里可能有的同学会疑问了,最后算出来的系数应该是关于某一个质数模过的,有可能和真实的系数不一样(比如原来的结果为负数或者比模数大)。所以,在什么情况下,能够使用NTT呢?
首先,计数问题用 NTT 一般没问题,因为计数问题一般最后算出来的系数都是正的。
其次,取模问题 NTT 一般没问题,在取模意义下,就算最后算出来是负数,也会被还原成正数。