专栏文章
树链剖分不详解
算法·理论参与者 3已保存评论 2
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 2 条
- 当前快照
- 1 份
- 快照标识符
- @mipfxk4u
- 此快照首次捕获于
- 2025/12/03 11:21 3 个月前
- 此快照最后确认于
- 2025/12/03 11:21 3 个月前
更新记录:
- 2024.xx.xx 完成本篇重链剖分部分。
- 2024.xx.xx ~ 2025 5.1 补充重链剖分部分内容。
- 2025.10.21 开始写长链剖分内容。
树链剖分の作用:
树链剖分将一个树划分为一个个链,使得更新后的编号能够使用各类数据结构来维护。如线段树。
重链剖分
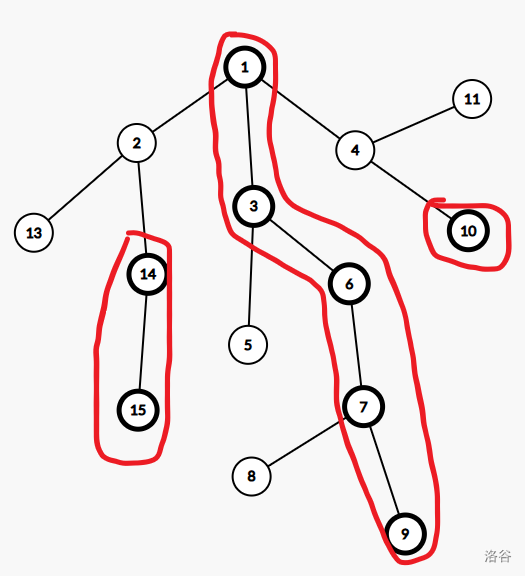
重链剖分の一些概念:
- 重儿子:一个节点的子节点中子树最大的节点叫做重儿子,如果子树大小最大的节点有多个,任意一个都可以。如果是叶子结点,就没有重儿子。
- 轻儿子:一个节点的子节点中除了重儿子的节点都为轻儿子。
- 重边:父节点到其重儿子的边为重边。
- 轻边:父节点到其非重儿子的子节点的边,都为轻边。
- 重链:首尾相连的重边所组成的链。
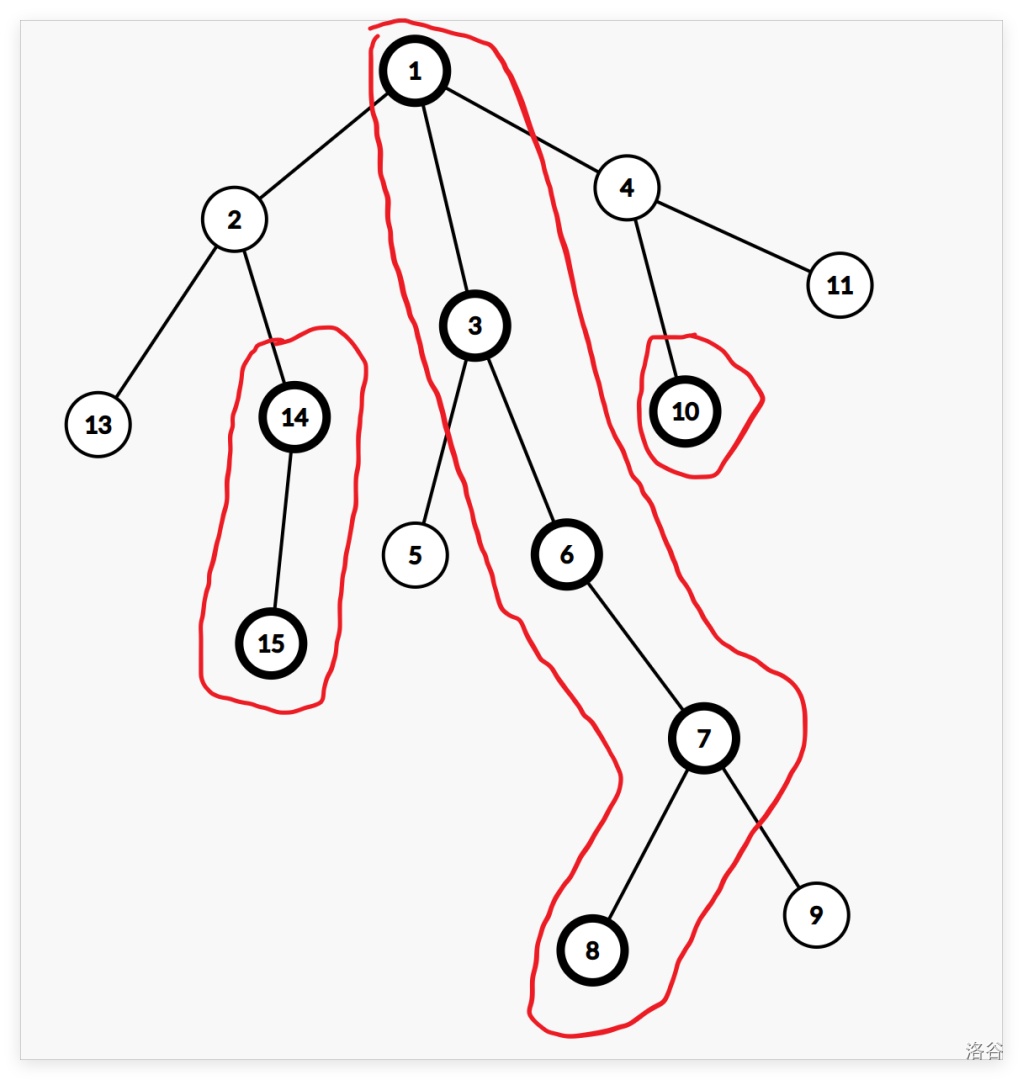
如图,加粗节点是重儿子,未加粗节点是轻儿子,红圈圈出的链是重链。
重链剖分の主要步骤:
第一步,定义各类变量:
定义如下变量:
- ——表示所连的边。
- ——表示深度。
- ——表示父节点。
- ——表示子树节点数。
- ——表示重儿子。
- ——表示这个节点所在重链的顶端,如果是轻儿子,那么这个节点就是自己。
- ——表示 dfs 后新的节点编号。
- ——表示这个节点的点权。
- ——表示更新后的节点编号所对应原来的节点编号。
还要实现维护所用的数据结构:如线段树。数据结构建议封装或写入一个结构体处理。
其中 一般放入结构体中。
code:
CPPstruct V{
vector<int> e;
int h;
int fa;
int id;
int son;
int top;
int size;
long long d;
} v[N];
int rk[N];
struct msjjg{ // 某数据结构
// ...
};
// 或
namespace MSJJG{ // 某数据结构
// ...
}
第二步,跑一遍 dfs
code:
CPPinline void dfs1(int u, int f, int d) {
v[u].h = d;
v[u].fa = f;
v[u].size = 1;
int cnt = -114514;
for(auto to: v[u].e) {
if(to == f) continue;
dfs1(to, u, d + 1);
v[u].size += v[to].size;
if(v[to].size > cnt) cnt = v[to].size, v[u].son = to;
}
}
主要处理 的信息。
第三步,再跑一遍 dfs
code:
CPPinline void dfs2(int u, int top) {
v[u].top = top;
v[u].id = ++_cnt;
rk[_cnt] = u;
if(!v[u].son) return;
dfs2(v[u].son, top);
for(auto to : v[u].e) {
if(to == v[u].son) continue;
if(to == v[u].fa) continue;
dfs2(to, to);
}
}
主要处理 的信息。
第四步,树链剖分相关函数
这里以树链剖分模板题举例。
对于查询/修改子树
这里就不放代码,因为是修改/查询子树,而一个子树内的编号是连续的,所以修改/查询的区间就是 。
对于修改路径内的节点
code:
CPPinline void add(int x, int y, long long c) {
while(v[x].top != v[y].top) {
if(v[v[x].top].h < v[v[y].top].h) x ^= y, y ^= x, x ^= y;
tree.add(1, v[v[x].top].id, v[x].id, c);
x = v[v[x].top].fa;
}
if(v[x].id > v[y].id) x ^= y, y ^= x, x ^= y;
tree.add(1, v[x].id, v[y].id, c);
}
就是让深度最低的节点不断向上跳,直到 与 属于一个重链。而向上跳时,对于重链,编号一定连续,直接线段树修改,后将深度最低的节点跳至其所属重链顶端的父节点,因为其所属重链的顶端已经被修改,所以跳至父节点。如果 与 属于了一个重链,直接修改 到 。
对于查询路径内的节点
code:
CPPinline long long ask(int x, int y) {
long long ans = 0, fx = v[x].top, fy = v[y].top;
while(fx != fy) {
if(v[fx].h >= v[fy].h)
ans += tree.ask(1, v[fx].id, v[x].id), x = v[fx].fa, fx = v[x].top;
else
ans += tree.ask(1, v[fy].id, v[y].id), y = v[fy].fa, fy = v[y].top;
ans %= p;
}
if(v[x].id <= v[y].id)
ans += tree.ask(1, v[x].id, v[y].id);
else
ans += tree.ask(1, v[y].id, v[x].id);
ans %= p;
return ans;
}
意思与修改差不多,故不做解释。
第五步,实现主函数
没什么要点,不做讲解。
对于时间复杂度の证明
重链剖分的时间复杂度是 。
怎么证明呢?
重链剖分中每个节点到根的路径最多有 条轻边。因为如果 的边是一条轻边,那么 的子树大小一定 的子树大小,因为重儿子的子树一定 的子树大小。而重链剖分中是按重链的 来跳的,又因最多 条轻边,所以最多跳 次。而每次又会进行数据结构的查询操作,使用数据结构的区间操作单次普遍是 的,所以重链剖分的时间复杂度是 。
P3384 【模板】重链剖分/树链剖分
模板题,不做讲解。
code。
SP6779 GSS7 - Can you answer these queries VII
建议做完 P4513 小白逛公园 后,再做此题。
对于每个线段树上节点要额外维护的如下:
- ,包含左端点的最大子段和。
- ,包含右端点的最大子段和。
- ,最大子段和。
- ,区间和。
对于上传
- ,是左儿子的 ,和左儿子的 右儿子的 的最大值。
- ,是右儿子的 ,和右儿子的 左儿子的 的最大值。
- ,是左儿子的 右儿子的 。
- ,是左儿子的 ,右儿子的 和左儿子的 右儿子的 。
其余的问题,主要就是查询上的问题。
查询部分的代码:
CPPinline V ask(int x, int y) {
V l, r;
long long fx = v[x].top, fy = v[y].top;
while(fx != fy) {
if(v[fx].h >= v[fy].h) {
V _z = l, _y = tree.ask(1, v[fx].id, v[x].id);
pu(l, _y, _z), x = v[fx].fa, fx = v[x].top;
}
else {
V _z = r, _y = tree.ask(1, v[fy].id, v[y].id);
pu(r, _y, _z), y = v[fy].fa, fy = v[y].top;
}
}
if(v[x].id <= v[y].id) {
V _z = r, _y = tree.ask(1, v[x].id, v[y].id);
pu(r, _y, _z);
}
else {
V _z = l, _y = tree.ask(1, v[y].id, v[x].id);
pu(l, _y, _z);
}
V yr_ak_ioi;
swap(l.lans, l.rans);
return pu(yr_ak_ioi, l, r);
}
基本没什么问题吧,可能有问题的两个地方:
- 第一个,为什么是要用两个变量来记录最后的答案。原因是:重链调换顺序是无法正确处理答案的。只用一个变量来记录就有可能会出现这种情况:本来路径之间的点权是 。最大子段和是 。但是两个跳跃混用一个变量,就可能会导致下面的结果:记录的点权 最大子段和变为了 。
- 第二个为什么是
pu(r, _y, _z),而不是pu(r, _z, _y)。如果按第二种跳,就是错误的,举个🌰:本来路径之间的点权是 。为了方便起见,假设 在 的祖先节点,而 在 的第三条重链的顶端,那么按照第二种合并方法,合并出来的的序列是 。这个序列无法通过任何翻转操作来使其与正确的序列相匹配,所以错误。
注:举例中相同颜色的一段表示这些点权所在的点在同一个重链。
code。
P4114 Qtree1
这道题与普通的树链剖分的区别:普通是点权,这个是边权。
对于给出的一个树,可能是这样的:
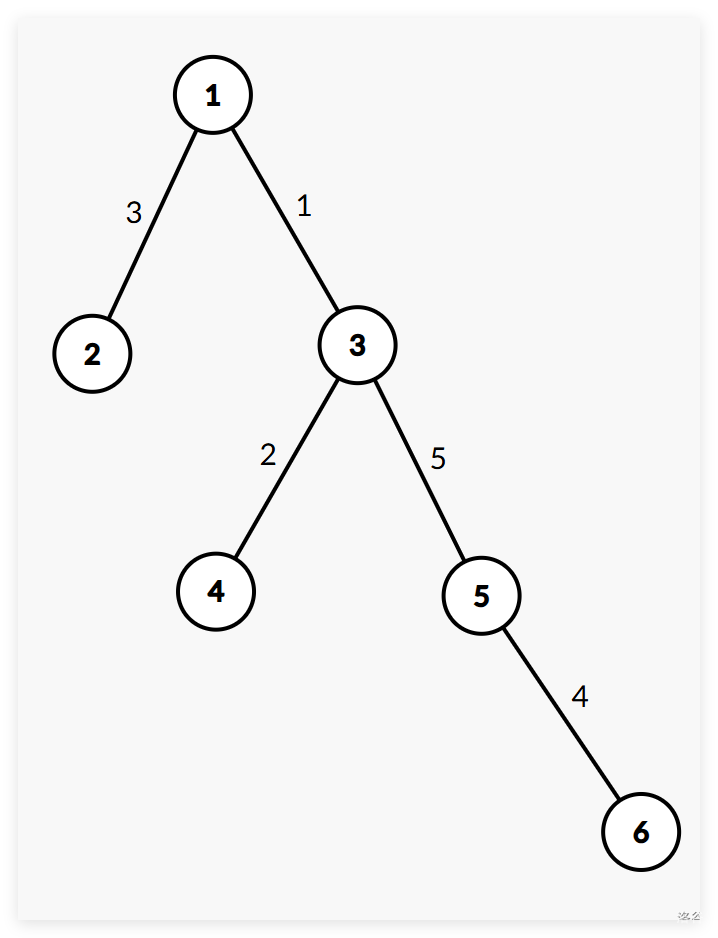
考虑边权下放至深度更低的节点的点权。
如图所示:
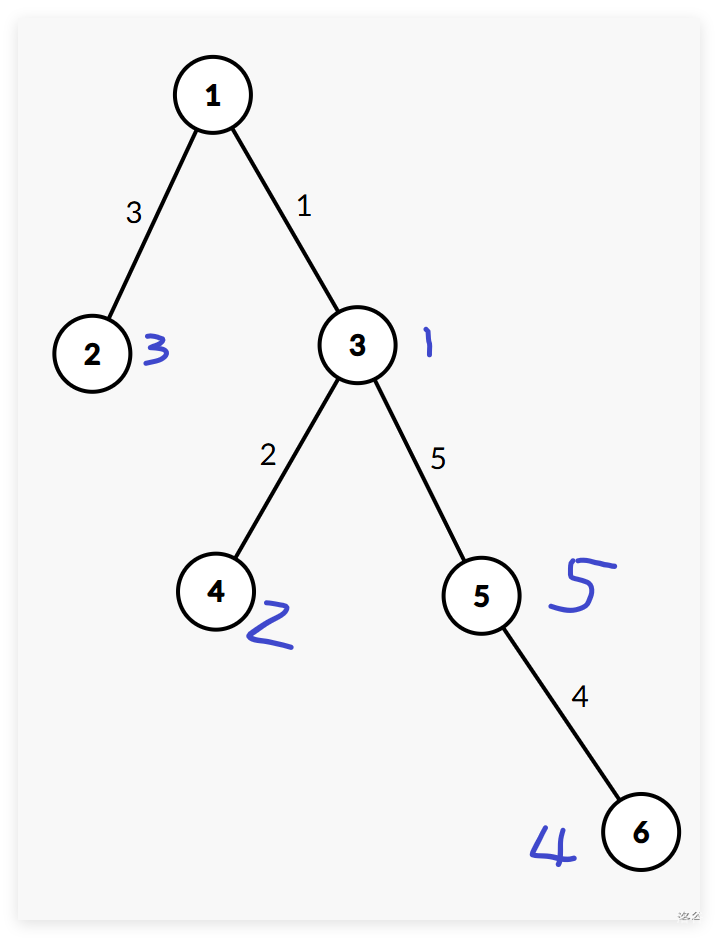
那么修改操作就为单点修改。
那对于查询操作呢?
还是上幅图,对于查询 到 之间的路径。
会发现计算的最大值会考虑多余的最大公共祖先 的点权。即计算最大值时,不应该算上最近公共祖先。
那么,两点不在一条重链时,还是按照普通的来跳。
但在一条重链时,只能求最深的节点到最浅的节点的重儿子。即最浅节点的编号 。
code。
P2486 [SDOI2011] 染色
与 SP6779 类似,对于每个线段树上节点只需额外维护以下信息:
- ,包含左端点的颜色段的颜色。
- ,包含右端点的颜色段的颜色。
- ,颜色段数目。
对于上传节点:
- ,就是左儿子的 。
- ,就是有右儿子的 。
- ,就是左儿子的 ,加上右儿子的 。注意!如果左儿子的 等于右儿子的 ,那么还要再 。
code。
P4312 [COI 2009] OTOCI
这道题看似需要用 LCT 来做,实际用树链剖分来做也可以。因为题目保证所有的加边操作完成后一定是个森林,而且不强制要求在线,所以可以先用并查集来直接进行加边操作。将最后形成的森林的边确定后,就直接进行树链剖分。然后再用并查集进行所有操作的模拟。
注意:由于形成的可能是森林而不是树,所以要
for(int i = 1; i <= n; i++) if(!v[i].h) dfs1(i, 0, 1), dfs2(i, i); 这么写。code。
P7735 [NOI2021] 轻重边
这道题是 P2486 [SDOI2011] 染色 的类似题。
对于操作 1. 考虑对点进行染色。
如:
对于样例这颗树: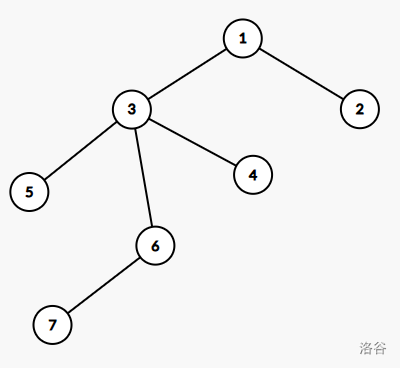
先对每个点染一个不同的颜色: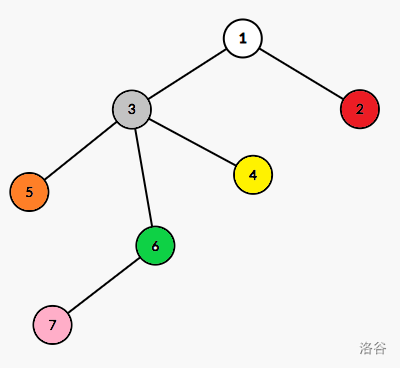
那么对于操作一,就是对 的路径进行染色。
而对于操作二,就是求 求有多少个相邻的同色点。
对于样例的第一个操作,即是 重新染一个与之前完全不同的颜色: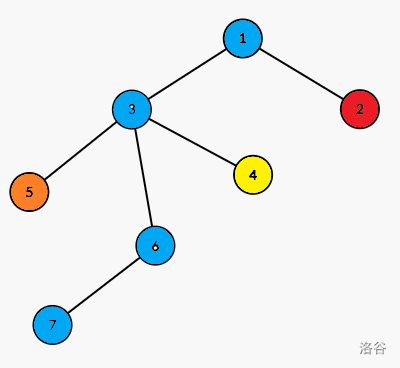
对于样例的第二个操作, 之中,只有 这两个相邻的点同色,所以答案是一。
接下来就是普通的树剖(注意查询时合并的顺序)。
code。
P3979 遥远的国度
一道典型的换根树剖。
因为每次换根就重构一次明显会 TLE,所以考虑维护一个假根,再定义一个 记录真的根,最后大力分类讨论即可。
对于操作 ,直接更新 即可。
对于操作 ,直接按照普通的更新就可以了。
对于操作三,大力分讨。为了方便,先假设假根是 ,查询是 的子树,绿色节点表示在给出的条件下 能取的节点。
-
,即
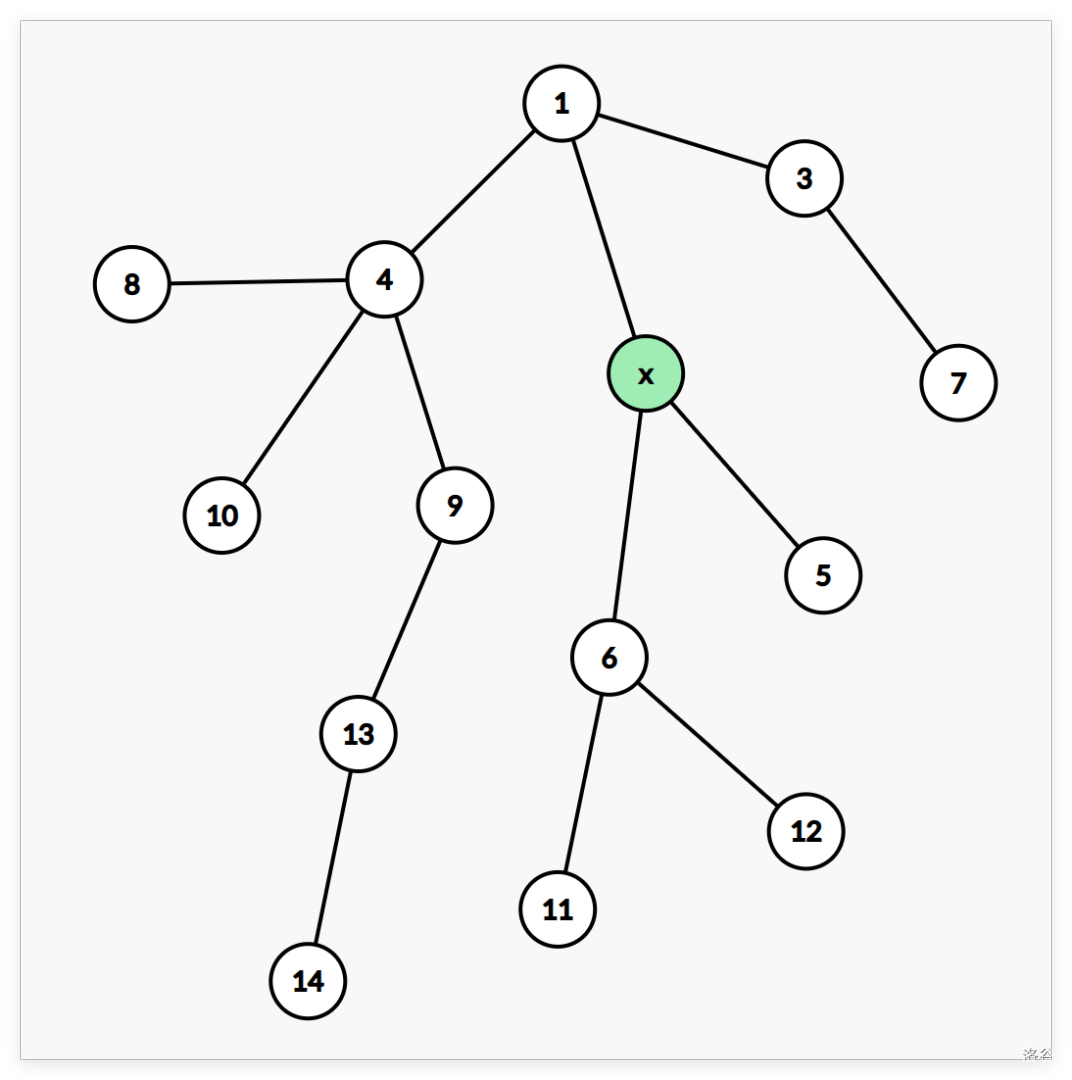 答案就是整个树的最小值。
答案就是整个树的最小值。 -
不在 的子树内,即
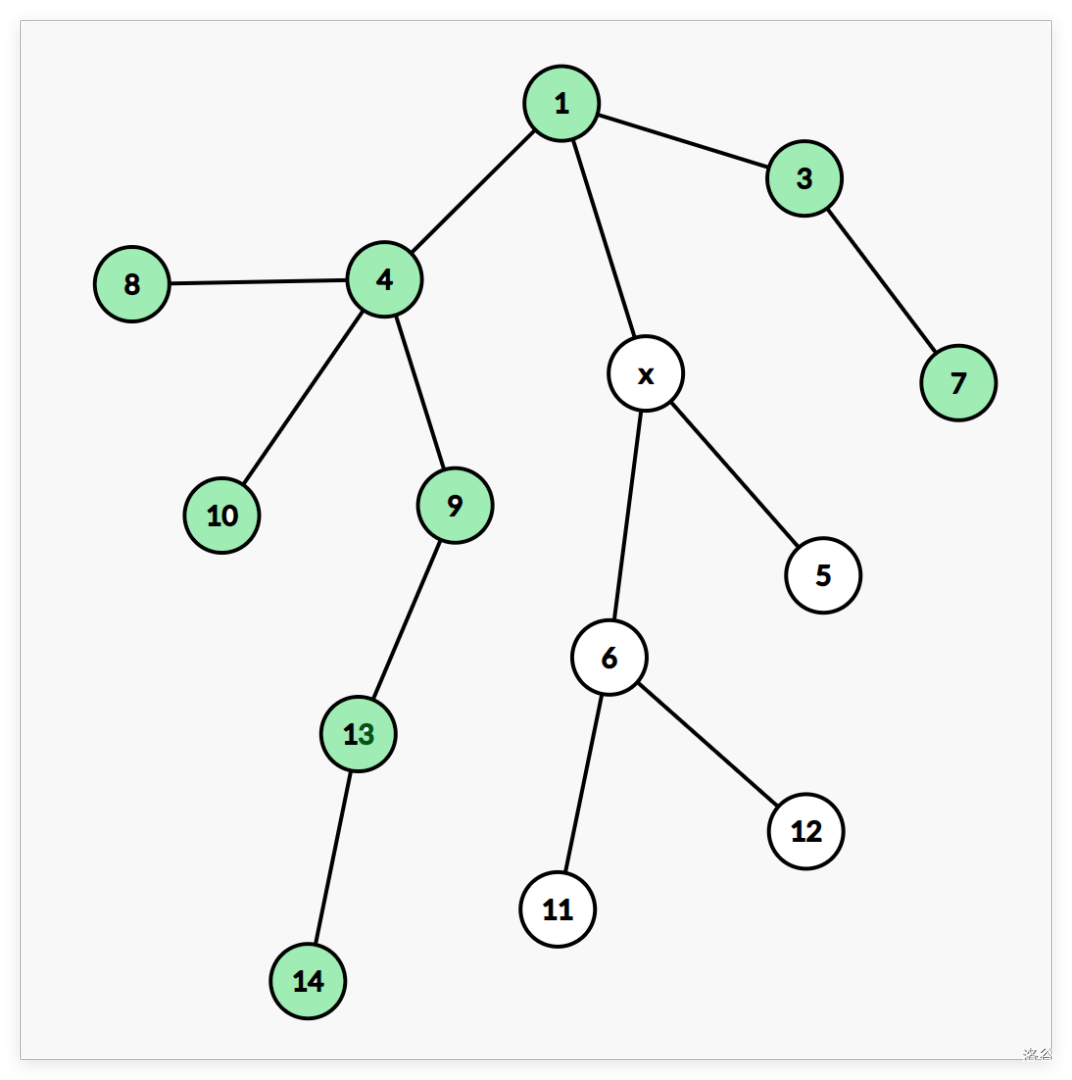 此时答案就是 的子树的最小值。
此时答案就是 的子树的最小值。 -
在 的子树内,且 ,即
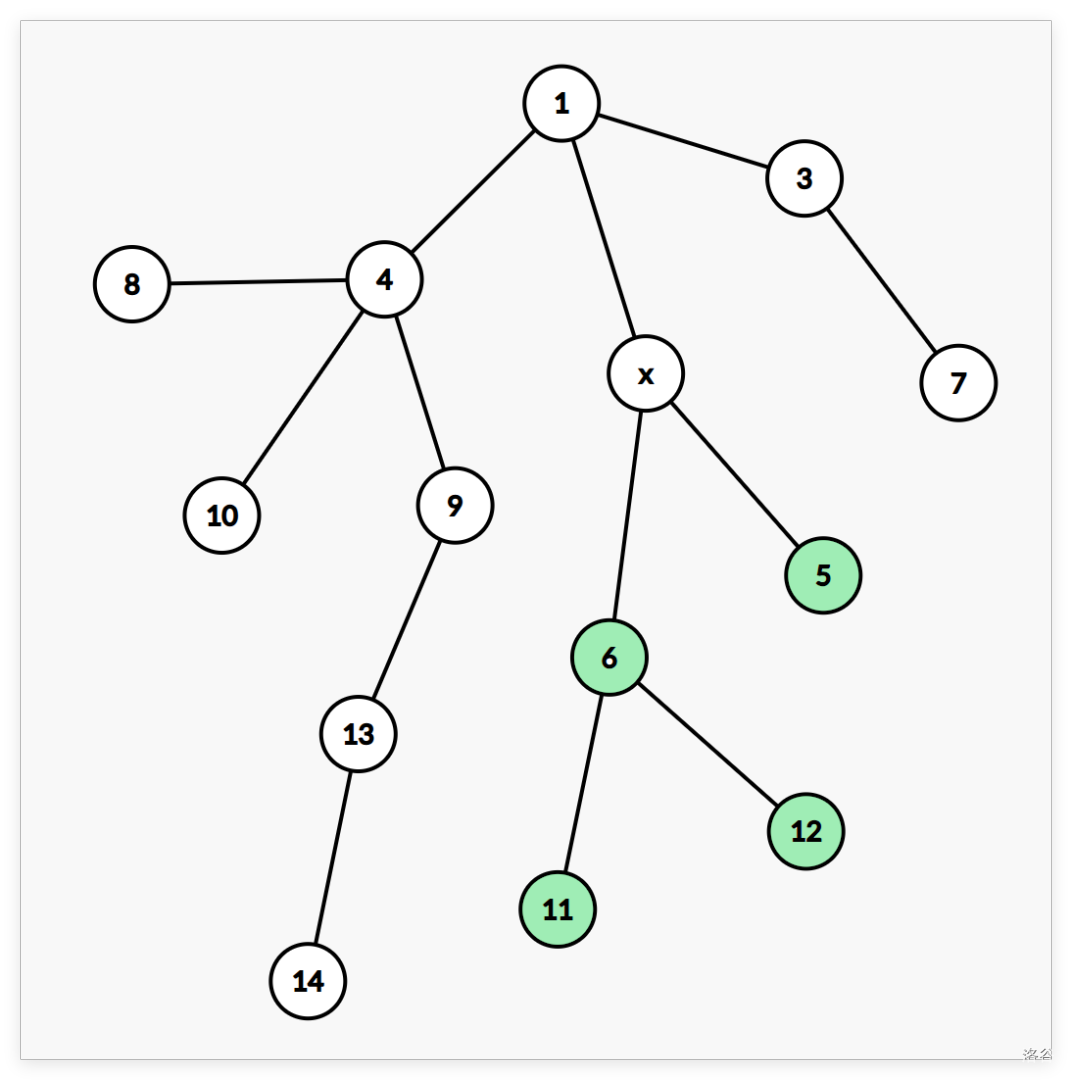 答案就是除了 到 路径上的 的子节点的子树的节点的最小值。
答案就是除了 到 路径上的 的子节点的子树的节点的最小值。
code。
P4211 [LNOI2014] LCA
这是一道区间 LCA 深度和。因为深度是 deep,于是考虑使用 deepseek
求 LCA 的深度,有一种很弱智聪明的做法:假设对点 和 求 LCA,先让 往根跳,对 跳时经过的节点打上标记,再让 往上跳, 遇到第一个有标记的节点,假设是 。那么 就是 和 的 LCA,LCA 的深度就是 的深度。这种方法的最劣复杂度是 。
的时间复杂度一定会TLE,于是有了一个聪明的优化,即将 往上跳时经过的点点权 ,那么 LCA 的深度就是 到 的点权之和。时间复杂度 。明显,多个点一起求不仅不会影响单个点的答案,还可以减少常数。
的时间复杂度也是会 TLE。由于问题可以离线,所以采用离线思想。
将 ,拆为 。
对于行如 的求和,按照 来排序。
然后分别求出前缀和,再求出区间正确的答案。
时间复杂度被优化到了
code。
P3401 洛谷树
考虑使用一个位运算相关题目中较为常用的技巧:拆位。
分别统计第 位上两点间的异或值为 的点对数,再将第每一位上对答案的贡献求和即可。
那么怎么统计第 位上点间的异或值为 的点对数呢?
由于我太蒟,所以只会一个十分笨拙的写法。
考虑类似区间最大子段和的方法,对于每个线段树节点额外统计以下信息:
- 当前区间的点对数。记作 。
- 当前区间的和的奇偶性。记作 。
- 以区间左端点为左端点的和为 的区间树。记作 。
- 以区间左端点为左端点的和为 的区间树。记作 。
- 以区间右端点为右端点的和为 的区间树。记作 。
- 以区间右端点为右端点的和为 的区间树。记作 。
那该如何合并呢?
假设要合并的节点是 ,要和到节点 中。
那么 的信息该这样合并:
接下来就是普通的树剖了,还有要注意要按照 SP6779 GSS7 - Can you answer these queries VII 的方法进行区间的查询。
P5478 [BJOI2015] 骑士的旅行
这题写了个题解,就去看题解吧:【传送门】。
长链剖分
长链剖分の一些概念:
和重链剖分十分相似,可以参考重链剖分的部分,唯一区别在于是按照子树深度最大来定义重儿子的。
如图,加粗节点是重儿子,未加粗节点是轻儿子,红圈圈出的链是轻链。
长链剖分的用处
很明显,这个东西一定有什么特别的用处,否则发明这个的人一定是吃饱了撑着,所以这个有什么用呢?常见的用处就是解决一些关于深度的一部分问题,以及优化树形DP。
长链剖分的例题
就拿 P5903 【模板】树上 K 级祖先 来作例题。
分析
首先这道题如果直接倍增暴力做 说是会被卡,但是实际卡没卡也不知道。所以还是要考虑每次询问 的解法。
那如何做呢?不难想到,可以利用预处理降低查询的复杂度,所以思路就有了,具体维护就可以维护每条轻链链定分别向上和向下走的数组,每次询问先向上走 ,此时就可以直接查询了。
第一步,定义维护的内容
对于此题,我们总共要维护以下内容:
- ——每个链的链顶。
- ——每个节点的深度。
- ——每个节点的重儿子。
- —— 的最大的二进制位。
- ——第 个节点的子树的最大深度。
- ——第 个点为链顶的链的长度。
- ——第 个节点向上走 步所到达的节点。
- ——第 个点为链顶时,从下往上总共 步所能够到达的节点。
第二步,处理出重儿子
和重链剖分极其类似,只是判断条件变了。
CPPinline void dfs(LL u, LL fa, LL h) {
v[u].h = h, f[u][0] = fa, v[u].s = v[u].h;
for(auto to: v[u].e) {
if(to == fa) continue;
dfs(to, u, h + 1);
if(v[to].s > v[u].s) v[u].s = v[to].s, v[u].son = to;
}
}
第三步,处理链
也是和重链剖分极为相似。
CPPinline void dfs2(LL u, LL top) {
v[u].top = top, len[top]++;
if(v[u].son) dfs2(v[u].son, top);
for(auto to: v[u].e) {
if(to == f[u][0]) continue;
if(to == v[u].son) continue;
dfs2(to, to);
}
}
第四步,进行预处理。
这一步主要是预处理 和 ,也是非常简单,没有技术含量。
CPPfor(LL i = 1; i < L; i++) for(LL j = 1; j <= n; j++) f[j][i] = f[f[j][i - 1]][i - 1];
for(LL i = 1; i <= n; i++) {
if(v[i].top != i) continue;
LL x = i;
for(LL j = 1; j <= len[i]; j++) {
if(v[x].son == 0) break;
x = v[x].son;
}
for(LL j = 1; j <= len[i] * 2; j++) {
v[i].a.push_back(x);
x = f[x][0];
if(x == 0) break;
}
}
for(LL i = 1; i <= n; i++) {
for(LL j = L - 1; j >= 0; j--) {
if((i >> j) > 1) {
h[i] = j + 1;
break;
}
}
}
第五步,对于答案进行计算。
这里我为了我使用了分讨。
- ,那么最后的点直接是 。
- ,直接暴力跳。
- 先往上跳 ,剩下的 ,一定小于原来 的二分之一,再直接暴力查表。
for(LL i = 1; i <= q; i++) {
LL x = (RAND::get(RAND::s) ^ last_ans) % n + 1, k = (RAND::get(RAND::s) ^ last_ans) % v[x].h;
if(k == 0) {
cnt ^= i * x;
last_ans = x;
continue;
}
if(k - (1 << h[k]) == 0) {
cnt ^= i * f[x][h[k]];
last_ans = f[x][h[k]];
continue;
}
x = f[x][h[k]];
k -= (1 << h[k]);
cnt ^= i * v[v[x].top].a[len[v[x].top] - v[x].h + v[v[x].top].h + k - 1];
last_ans = v[v[x].top].a[len[v[x].top] - v[x].h + v[v[x].top].h + k - 1];
}
注意:应为我的深度是存在结构体里的,所以讲解中的 在代码实现中是全局的 。
关于正确性的证明
对于这道题,详细有不少人都对于这个处理的正确性感到怀疑(这就是为什么我中间已知没更5个月,因为很懵所以摆了),而且绝大部分题解都没有给出证明。其实这个还是比较容易去想的,可以根据跳的步数一定大于剩余步数,以及自行构造几组数据,然后再根据长剖按深度为重儿子的特点,就可以证明了。
code。
证明过程
挖坑待填……
由于我刚学OI,所以没刷几道树链剖分的题。所以只能给出这些了。之后也许还会再加入有些题目。
主要参考资料与题单:
- OIwiki。
- @Hoks 的 『应用(折磨)篇』重链剖分 和 『应用(折磨)篇』重链剖分 Part 2。
- 同样是@Hoks 的 『从入门到入土』树链剖分学习笔记。
相关推荐
评论
共 2 条评论,欢迎与作者交流。
正在加载评论...