专栏文章
KMP算法
算法·理论参与者 5已保存评论 4
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 4 条
- 当前快照
- 2 份
- 快照标识符
- @mliacfaj
- 此快照首次捕获于
- 2026/02/12 01:10 上周
- 此快照最后确认于
- 2026/02/19 01:19 10 小时前
upd: 图床崩了
引入
首先我们来看这样一个问题:
给出两个字符串 和 ,若 的区间 子串与 完全相同,则称 在 中出现了,其出现位置为 现在请你求出 在 中所有出现的位置。保证 , 中均只含大写英文字母。
首先我们能够想到一个简单的暴力做法:
- 枚举序列匹配时的出现位置 。
- 检查此时匹配的每一个位置是否相同,如果全部相同则记录答案。
理论实践复杂度:,虽然一般跑不满,但是十分容易被卡:
CPPaaaa ··· 这里一共2n个 ··· aaaa
aa ··· 这里一共n个 ··· aa
此时每一次检测都必须跑满,时间复杂度:,直接就 TLE 了。
我们可以总结一下暴力的问题: 对于每一个起始位置,我们都必须要重新做一此,尽管他们之间仅仅差了一位。
有一个大神提出了一种崭新的方法:KMP。
算法流程
下面我把匹配串(长的)成为
S, 模式串称为 T。S 的长度为 n,T 的长度为 m,注意下面所有代码都在字符串开头添加了一个无关字符 #,从而使字符串开始下标为 1。1. 求解 net 数组
这个
nxt[i] 数组表示的是对于 T 的长度为 i 的前缀,其最长 公共先后缀 的长度(不算它本身)。直接看可能有点难理解,所以这里给出一个例子:
CPPT: a b a b a
nxt: 0 0 1 2 3
比如对于
nxt[5] 即处理前缀 ababa,此时我们发现他们有一个公共前后缀 aba,因此 nxt[5]=3。先不管这个数组有什么用,但是明明感觉这个数组还是很难求。

首先我们发现如果需要求一个
nxt[i] 假设我们已经知道了 nxt[1~i-1],如果不管公共前后缀的最后一位(即图中标黑的),那么剩下的部分一定也是 前缀 i-1 的一个公共先后缀。所以我们可以找到一种简单的办法:
遍历所有前面字符串的公共前后缀,比较下一位,知道相等得出答案
但是如何遍历前面字符串的 公共前后缀 呢?
我们发现一个字符串的 公共先后缀 的 公共前后缀 还是这个字符串的 公共前后缀。

(这里黄色的即公共先后缀的公共前后缀)
只要我们每一次选择的 公共前后缀 都是最长的,一定满足能够不重样的遍历每一个 公共前后缀
所以我们可以得出代码:
CPPfor(int i=2,j=0;i<=m;i++){
// 之所以直接为 j 因为 nxt[i-1]=j
while(j && t[i]!=t[j+1]) j=nxt[j]; // 不断的遍历前面一个的公共前后缀
if(t[i]==t[j+1]) j++;
nxt[i]=j;
}
2. 查询答案
看到这里可能仍有疑问:
nxt[] 有什么用?我们在求解完
nxt[] 再次进行一轮匹配。我们仍是寻找一个 最长公共前后缀,但是我们现在寻找的是前缀在
T 中,后缀在 S 中。举个栗子:
CPPS: abbabc // 此时处理前5个字符
T: abd
这个时候求解出来的答案(处理到前 5 个)为
2,即此时求解出的 最长公共前后缀 为 ab,因为前五个字符为 abbab,可以证明没有更优的答案。这里的求解过程和前面求解
nxt[] 数组十分相近,只是字符串变成了两个。求解出的这个答案如果等于
m 代表 T 正好覆盖了当前处理的后缀,于是记录答案:举个栗子:
CPPS: abbabc // 此时处理的是整个字符串
T: abc
现在我们得到的这个 “最长公共前后缀” 正好是
3 = m,此时正好出现了一次匹配。所以这一部分的代码:
CPPfor(int i=1,j=0;i<=n;i++){
while(j && s[i]!=t[j+1]) j=nxt[j]; // 这个与上面的同理
if(s[i]==t[j+1]) j++;
nxt[i]=j;
}
完整代码:
CPPfor(int i=2,j=0;i<=m;i++){
// 之所以直接为 j 因为 nxt[i-1]=j
while(j && t[i]!=t[j+1]) j=nxt[j]; // 不断的遍历前面一个的公共前后缀
if(t[i]==t[j+1]) j++;
nxt[i]=j;
}
for(int i=1,j=0;i<=n;i++){
while(j && s[i]!=t[j+1]) j=nxt[j]; // 这个与上面的同理
if(s[i]==t[j+1]) j++;
if(j==m) {cout<<i-m+1<<' ';j=nxt[j];} // 输出的是匹配串的左端点, 这里之所以要 j=nxt[j] 是因为 最长公共前后缀 不能是整个数组。
}
时间复杂度:
前后两部分基本相同,只用关注一边(前一半)。
每一次在
while(j && t[i]!=t[j+1]) j=nxt[j]; 时,j 在不断下降,而每一次 j 只会最多加一次,所以可得时间复杂度为 。小结:
这个就是基础 KMP 的全部过程了,其最基础的应用就是查询字符串相等。
应用
1. 求字符串循环节
这里寻找的是一个 最短循环节,先给出答案:
n-nxt[n]。看到下面这个例子: 每一个黑框是一个 最短循环节,最后一个不完整。
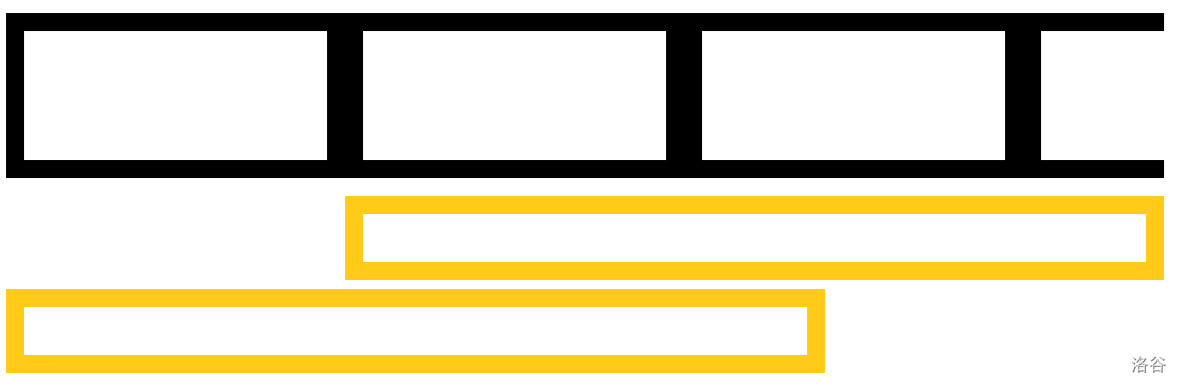
此时
nxt[n] 就是这两个黄框,我们发现 nxt[n]=n-(一个循环节长度),所以 ans = n - nxt[n]。代码:
CPPcin>>n>>s;
s=' '+s;
for(int i=2,j=0;i<=n;i++) {
while(j && s[i]!=s[j+1]) j=nxt[j];
if(s[i]==s[j+1]) j++;
nxt[i]=j;
}
int len=n-nxt[n];
cout<<len;
可以在写一下这道练习题:P10475 [USACO03FALL] Milking Grid(数据加强版) - 洛谷。
还有这一道:SP263 PERIOD - Period - 洛谷,vjudge:Period - POJ 1961 - Virtual Judge。
2. 应用
nxt[] 数组nxt[] 数组的定义是一个字符串指定前缀的 最长公共前后缀,在有的题目可能会用到。这里直接上例题 CF126B Password - 洛谷。
首先题目需要找的是一个字串满足即使前缀,又是后缀,还在中间出现。满足即使前缀,又是后缀及其 公共先后缀,可以使用while(j) j=nxt[j],遍历所有。但是如果考虑在中间也出现过,其实就是一个前缀的 公共前后缀,所以直接使用一个桶存储,就可以解决这个问题:CPP#include<bits/stdc++.h> #define int long long using namespace std; const int N=1e6+5; int n; bool T[N]; int nxt[N]; string s; signed main(){ cin>>s; n=s.size(),s='#'+s; for(int i=2,j=0;i<=n;i++){ while(j && s[i]!=s[j+1]) j=nxt[j]; if(s[i]==s[j+1]) j++; nxt[i]=j; if(i!=n) T[j]=1; } for(int i=nxt[n];i;i=nxt[i]){ if(T[i]){ cout<<s.substr(1,i)<<'\n'; return 0; } } cout<<"Just a legend\n"; return 0; }
3. KMP + DP
在这种题目中其实主题是 DP,而 KMP 的作用主要是用来判断字符串是否相等,所以实际上很多题目可以直接使用 hash 同样完成。
这里我们定义f[i]为长度为i的前缀是否能够被拼出可以推出递推式:f[i]|=f[i-s[i].size],(s[i].size表示第i个字符串的长度)。这里有一个条件,就是这个时候的后缀必须与s[i]完全匹配。所以直接使用 KMP 就可以了,用 hash 的效果一样。CPP#include<bits/stdc++.h> using namespace std; const int N=2e5+5; int n,m; int f[N]; bool mat[205][N]; string s[205],t; int nxt[205]; void solve(int x){ memset(nxt,0,sizeof nxt); for(int i=2,j=0;i<s[x].size();i++){ while(j && s[x][i]!=s[x][j+1]) j=nxt[j]; if(s[x][i]==s[x][j+1]) j++; nxt[i]=j; } for(int i=1,j=0;i<=n;i++){ while(j && t[i]!=s[x][j+1]) j=nxt[j]; if(t[i]==s[x][j+1]) j++; if(j==s[x].size()-1) mat[x][i]=1,j=nxt[j]; } } signed main(){ while(cin>>s[++m] && s[m]!="."){ s[m]='#'+s[m]; } s[m--]=""; string x; while(cin>>x) t=t+x; n=t.size(),t='#'+t; //------------------------------ for(int i=1;i<=m;i++) solve(i); f[0]=1; int ans=0; for(int i=1;i<=n;i++){ for(int j=1;j<=m;j++){ if(mat[j][i]) f[i]|=f[i-s[j].size()+1]; } if(f[i]) ans=i; } cout<<ans<<'\n'; return 0; }
4. KMP + 重新定义相等
这种题目一般需要重载
== 和 !=,修改成题目所需,一般都会有一些构造:例题:P4696 [CEOI 2011] Matching - 洛谷( QMR 说这道题题面比下面那道短,就当作例题了)。
重点依然是如何重定义两个字符是相同的。首先我们需要确定为什么能够使用 KMP 。这里十分重要!!!KMP 的一个利用特性在于字符串的连等:S1=S2 , S2=S3 => S1=S3。这道题目显然满足,我们可以把题目中的第一个序列a[]转换为b[],即以值为下标,存储数值为位置。例如序列2 1 5 3 4变成2 1 4 5 3。这个样子就可以把两个序列相等的条件转化为两个序列经过离散化之后相同,比如4 2 ==> 2 1与2 1相同。这个时候显然有连等性。然后考虑如何定义相等:
- 思路一: 我们发现只要两个序列中当前比较字符的比他小的元素的个数相等,那么一定相同,于是出现了题解中有一篇使用树状数组的解法。
- 优化: 我们可以变为比较其前驱和后记,记录一下其中一个字符串每一个字符相对其前驱和后继的距离,然后再另一个字符传中是否也满足前驱后继(直接比较大小)。
但是这里也有一个需要注意的,我们记录的前驱和后继必须是在当前比较区间中的(下面那一道题一样)。因为当前比较的字符一定是目前区间的最后一个,所以只需要保证前驱和后继都在当前字符之前,所以直接搞一个链表,然后从后往前便利,把一个字符处理完了之后就把他在链表中删去(把前后连在一起)。CPP#include<bits/stdc++.h> using namespace std; const int N=1e6+5; int n,m; int L[N],R[N]; int l[N],r[N]; int a[N],b[N],c[N]; void init(){ for(int i=1;i<=n;i++) b[a[i]]=i, L[i]=i-1,R[i]=i+1; for(int i=n;i>=1;i--){ if(L[b[i]]) l[i]=a[L[b[i]]]-i; if(R[b[i]]<=n) r[i]=a[R[b[i]]]-i; L[R[b[i]]]=L[b[i]]; R[L[b[i]]]=R[b[i]]; } } bool cmp(int A[],int x,int y){ return (A[x+l[y]]<=A[x]) && (A[x+r[y]]>=A[x]); } int top,st[N]; int nxt[N]; void KMP(){ for(int i=2,j=0;i<=n;i++){ while(j && !cmp(b,i,j+1)) j=nxt[j]; if(cmp(b,i,j+1)) j++; nxt[i]=j; } for(int i=1,j=0;i<=m;i++){ while(j && !cmp(c,i,j+1)) j=nxt[j]; if(cmp(c,i,j+1)) j++; if(j==n) st[++top]=i-n+1,j=nxt[j]; } } signed main(){ cin>>n>>m; for(int i=1;i<=n;i++) cin>>a[i]; for(int i=1;i<=m;i++) cin>>c[i]; init(); KMP(); cout<<top<<'\n'; for(int i=1;i<=top;i++) cout<<st[i]<<' '; return 0; }
练习题:P5256 [JSOI2013] 编程作业 - 洛谷, (正好以前写过,就放上来了)。
如果把‘相同’当作完全相同,则这就是一个 KMP 板子,所以我们主要是要知道如何判断两个字符是 相同的。我们定义两个数组 s,t,表示当前字符对应的最近的上一个字符的距离,如abcab为00033,(这里仅是示例),我们可以观察到如果两个字符串是‘相同的’,则它们按这个规则组成的数组也一定相等 。有一种特殊情况,比如CPPababb和cdd。这时两个分别为00221和001, 所以需要特判是否在比较范围内,及 KMP 时的j.#include<bits/stdc++.h> using namespace std; const int N=1e6+5; int Q; int n,m; int pre[N]; int s[N],t[N]; int nxt[N]; string S,T; bool cmp(int x,int y,int len){//compare between x and y if(x<0 && y<0) return x==y; return x==y || (x>len && y>len); } void KMP(){ memset(nxt,0,sizeof nxt); nxt[1]=0; int ans=0; for(int i=2,j=0;i<=m;i++){ while(j && !cmp(t[i],t[j+1],j)) j=nxt[j]; if(cmp(t[i],t[j+1],j)) j++; nxt[i]=j; } for(int i=1,j=0;i<=n;i++){ while(j>0 && !cmp(s[i],t[j+1],j)) j=nxt[j]; if(cmp(s[i],t[j+1],j)) j++; if(j==m) ans++,j=nxt[j]; } cout<<ans<<'\n'; } void solve(){ getline(cin,S); getline(cin,T); n=S.size(),m=T.size(); S='%'+S,T='%'+T; memset(pre,0,sizeof pre); for(int i=1;i<=n;i++){//Do with S if(S[i]>='a'&&S[i]<='z'){ s[i]=i-pre[S[i]-'a'+1]; pre[S[i]-'a'+1]=i; }else s[i]=-S[i]; } memset(pre,0,sizeof pre); for(int i=1;i<=m;i++){//Do with T if(T[i]>='a'&&T[i]<='z'){ t[i]=i-pre[T[i]-'a'+1]; pre[T[i]-'a'+1]=i; }else t[i]=-T[i]; } KMP(); } signed main(){ cin>>Q; getline(cin,S); while(Q --> 0) solve(); return 0; }
相关推荐
评论
共 4 条评论,欢迎与作者交流。
正在加载评论...