专栏文章
树链剖分
算法·理论参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @miqu8i6m
- 此快照首次捕获于
- 2025/12/04 10:49 3 个月前
- 此快照最后确认于
- 2025/12/04 10:49 3 个月前
好用的树剖
part 1 前置芝士
-
树形结构
-
链式前向星
-
线段树
-
DFS序
-
LCA
DFS序
小定义:对树执行DFS遍历时的顺序
应用:Tarjan
性质(维护信息的基础):
1.一颗子树内,根的DFS序一定小于他的任意儿子的DFS序
2.一颗子树内,他的DFS序的范围就 rt:子树根节点 size:子树节点数量
part 2 思想
树链剖分(以下简称“树剖”)用于将数分割成若干条链的形式,以维护树上路径的信息
具体来说,将整棵树剖分成为若干条链,是它合成线性结构,然后用其他的数据结构维护信息
因为这些链的数量不会超过 ,所以可以用它维护许多东西
part 3 定义
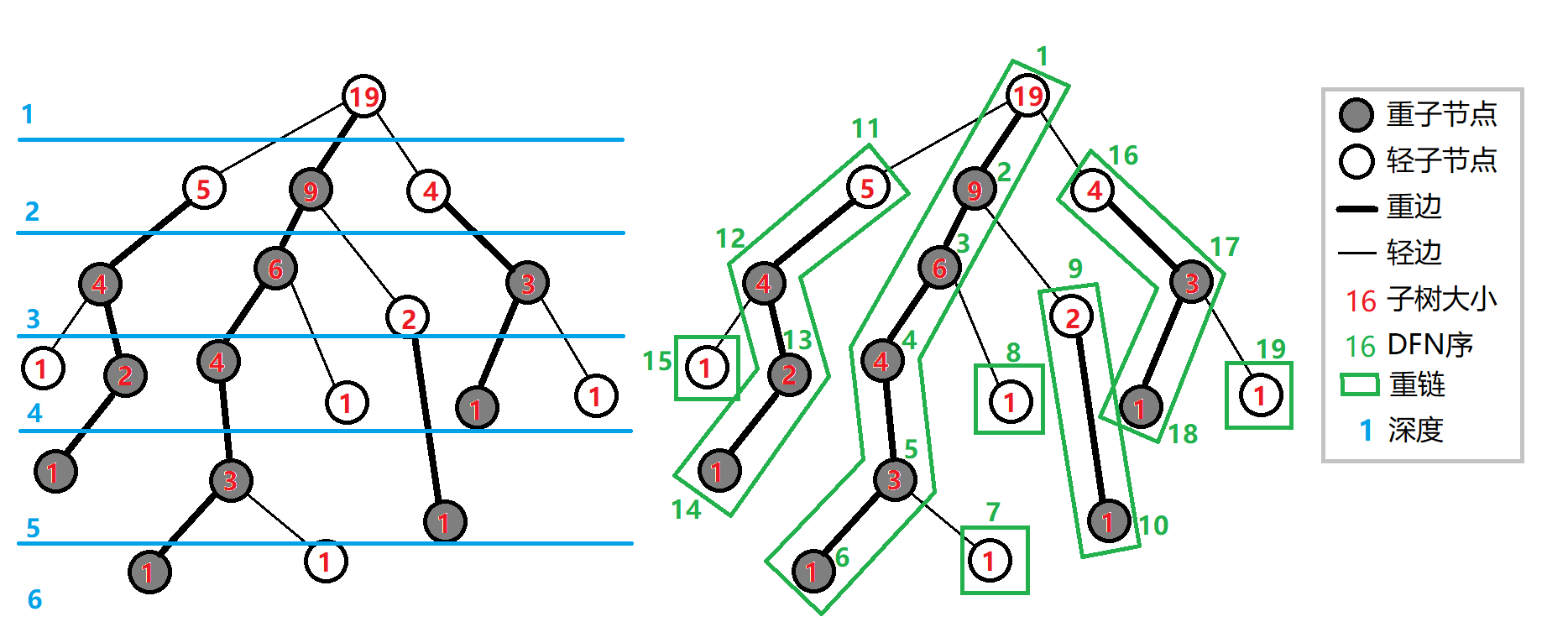
树剖指一种对树进行划分的算法,它先通过某种条件(如轻重边或长短边)剖分,将树分为多条链,保证每个点属于且仅属于一条链,然后再通过数据结构(树状数组、BST、Splay、线段树等)来维护一条链
树剖的目的是减少在链上修改、查询等操作的复杂度。
以轻重边剖分为例
若 表示以 为根的子树的节点个数
在 的所有儿子中, 最大的儿子就是重儿子,而 的其他儿子都是轻儿子,当前节点与其重儿子之间的边就是重边,多条重边相连为一条重链。
重子节点:表示其子节点中子树最大的子节点。如果有多个子树最大的子节点,取其一;若没有,就无重子节点。
轻子节点:除重子节点外剩余的所有子节点。
重边:从这个节点到重子节点的边。
轻边:到其他轻子节点的边。
重链:若干条首尾衔接的重边构成的链。把落单的节点也当做重链,那么整棵树就被剖分成若干条重链。
part 4 性质
如果v是轻儿子,u是v的父节点,则 ;
从根到某一点路径上,不超过条重链,不超过条轻边。
如果一个节点连向父亲节点的边是轻边,就必然存在子树不小于他的兄弟节点,那么父节点对应子树的大小一定超过该节点的两倍。每过一条轻边,子树大小就翻倍,所以最多只能经过 条。
part 5 步骤
进行两遍DFS,预处理出所有的节点信息。
根据题意,利用数据结构维护树上路径信息。
实现:预处理
第一遍DFS:
-
任意节点到达根的距离(深度);
-
任意节点的父亲节点(根默认为0);
-
任意节点子树的大小(包括其本身);
-
任意节点的重子节点(没有则为0);
代码
CPPvoid dfs1(int ver, int pre, int deep){
depth[ver] = deep, fa[ver] = pre, sz[ver] = 1;
int maxn = -1;
for(int i = h[ver]; ~i; i = ne[i]){
int j = e[i];
if(j == pre)continue;
dfs1(j, ver, deep + 1);
sz[ver] += sz[j];
if(maxn == -1 || maxn < sz[j]){
maxn = sz[j];
hson[ver] = j;//更新子节点
}
}
}
第2遍DFS:
- 遍历时的各个节点的DFS序:
- 每个节点所属重链的最顶端节点:
- dfs序对应的节点编号: ,有
- 每个节点在DFS序上的对应权值:
void dfs2(int ver, int topf){
dfn[ver] = ++timestamp;
val[timestamp] = a[ver];
top[ver] = topf;
if(!hson[ver])
return;
dfs2(hson[ver], topf);//先遍历重子节点
for(int i = h[ver]; ~i; i = ne[i]){
int j = e[i];
if(j == fa[ver] || j = hson[ver])
continue;
dfs2(j, j);//再遍历轻子节点
}
}
节点个数为权。
实现——预处理
之所以要先遍历重子节点,是因为要保证重链上的DFS序连续,这样才可以进行区间操作,按照DFN排序后的序列即为剖分后的链。
区间操作:
{
前缀和
差分
线段树
树状数组
分块
}
性质
- 树上每个节点都属于且仅属于一条重链。
- 所有的重链将整棵树完整剖分。
- 当向下经过一条轻边时,所在子树的大小至少会除以2,保证了复杂度的正确性。
LIKE 集合,用TARJAN
应用
选取左右端点所在树中深度更大的节点,维护他到所在重链顶端的区间信息。之后不断上跳,知道他和另一端点在同一链上,维护两点之间的信息。使用线段树或树状数组等数据结构,即可在 的时间内单次维护查询。
维护路径权值和
CPPvoid modify_range(int x, int y, int k){
while(top[x] != top[y]){
if(depth[top[x]] < depth[top[y]])
swap(x, y);
SGT.modify(1, dfn[top[x]], dfn[x], k);
x = fa[top[x]];
}
if(depth[x] > depth[y])
swap(x, y);
SGT.modify(1, dfn[x], dfn[y], k);
}
int query_range(int x, int y){
int res = 0;
while(top[x] != top[y]){
if(depth[top[x]] < depth[top[y]])
swap(x, y);
res = (res + SGT.query(1, dfn[top[x]], dfn[x])) % mod;
x = fa[top[x]];
}
if(depth[x] > depth[y])
swap(x, y);
res = (res + SGT.query(1, dfn[x], dfn[y])) % mod;
return res;
}
维护子树信息
思路相似,但更加简单,经过DFN重新划分后,一颗子树的dfn序一定在 之间,单次维护即可,时间复杂度 。
CPPvoid modify_subtree(int x, int k){
SGT.modify(1, dfn[x], dfn[x] + sz[x] - 1, k);
}
int query_subtree(int x){
return SGT.query(1, dfn[x], dfn[x] + sz[x] - 1);
}
求LCA
- 其思路与倍增求法相似,但常数更小。
- 每次选取重链顶端节点深度更大的节点上跳,直到两者在同一重链上,此时深度较小这位两节点LCA。
int lca(int a, int b){
while(top[a] != top[b]){
if(depth[top[a]] > depth[top[b]])
a = fa[top[a]];
else b = fa[top[b]];
}
return depth[a] < depth[b] ? a : b;
}
struct Tree{
struct Node{
int l, r, sum, tag;
inline int len(){
return r - 1 + 1;
}
}tr[N << 2];
void pushup(int u){
tr[u].sum = (tr[lc].sum + tr[rc].sum) % mod;
}
void build(int u, int l, intr){
tr[u].l = l, tr[u].r = r;
if(l == r)return tr[u].sum = val[l], void(0);
int mid = (l + r) >> 1;
build(lc, l, mid);
build(rc, mid + 1, r);
pushup(u);
}
void pushdown(int u){
if(!tr[u].tag)return ;
tr[lc].sum = (tr[lc].sum + tr[u].tag * tr[lc].len()) % mod;
tr[rc].sum = (tr[rc].sum + tr[u].tag * tr[rc].len()) % mod;
tr[lc].tag += tr[u].tag, tr[rc].tag += tr[u].tag;
tr[u].tag = 0;
}
void modify(int u, int l, int r, int k){
if(l <= tr[u].l && tr[u].r <= r){
tr[u].sum = (tr[u].sum + tr[u].len() * k) % mod;
tr[u].tag += k;
return ;
}
pushdown(u);
int mid = tr[u].l + tr[u].r >> 1;
if(l <= mid)
modify(lc, l, r, k);
if(r > mid)
modify(rc, l, r, k);
pushup(u);
}
int query(int u, int l, int r){
if(l <= tr[u].l && tr[u].r <= r)return tr[u].sum;
pushdown(u);
int mid = tr[u].l + tr[u].r >> 1;
int res = 0;
if(l <= mid)res = (res + query(lc, l, r)) % mod;
if(r > mid)res = (res + query(rc, l, r)) % mod;
return res;
}
}SGT;
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...