专栏文章
NFLSHC集训Day3
算法·理论参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @miotw96k
- 此快照首次捕获于
- 2025/12/03 01:04 3 个月前
- 此快照最后确认于
- 2025/12/03 01:04 3 个月前
安排
不想多说,早八上课下午答疑,中午睡一下,但是我今天依然戴了手表
今日大纲
- 学习字符串哈希
- 线段树基础
字符串哈希
哈希的基本理念
字符串哈希,就是一种用 的时间复杂度完成字符串比较和子串提取的工作,但是一般人会想,不是用 或者 更便捷吗?但是太慢了!这两个都是 的复杂度,套个循环,放个大数据就完蛋了,这个时候就要有请哈希上场了
一般字符串哈希的思想是把字符串由数字代替,是一种特殊的编号方法,让每个字符串能对应一个唯一的整数,但是方法有很多种,应该如何选择呢?
这时候有人跳出来(没错我说的):可以直接把字符串看为K进制数,完成十进制转换就行,关键在于如果只有小写(或大写)字母时就是26进制,都有(包括数字)就是62进制,举个例子:
字符串""就是27进制下的,算算就行
理想很丰满,但是也就想想吧,这个情况实在是太理想化了!int只有32位,很快就超了!那怎么办呢?
这时候又有人跳出来:因为正常来讲造数据的人不会很认真的卡你的常,而正常来讲普通运算和模2的31次方得出的结果是一样的,那么可以找一个数作为基数,再找一个大质数(一般来讲用 )作为模数,这样的哈希算法更高效
事实证明,这种想法理论上完全可行,但很不幸的是出数据的人万一就在茫茫数据海里碰到了一组冲突数据就完蛋了,所以这种模数法要基于和出数据的人心理博弈的能力以及超高校级的自信,保底写这个也是OK的,只不过效率有点低,看看示例:
CPPconst int M = 1e9 + 7;
const int B = 233;
#define ll long long
int hash(string s)
{
int res = 0;
for (int i = 0; i < s.size(); ++i)
{
res = ((ll)res * B + s[i]) % M;
}
return res;
}
bool cmp(string s, string t)
{
return hash(s) == hash(t);
}
这个时候还有人跳出来(什么?!还有高手?!):一个哈希不够就来两个,模数不同就可以
事实证明确实可行,双值哈希往往是安全且不赌命的选择,来看看示例:
CPP#define ull unsigned long long
ull base = 131;
ull mod1 = 212370440130137957, mod2 = 1e9 + 7;
ull hash1(std::string s)
{
int len = s.size();
ull ans = 0;
for (int i = 0; i < len; i++)
{
ans = (ans * base + (ull)s[i]) % mod1;
}
return ans;
}
ull hash2(std::string s)
{
int len = s.size();
ull ans = 0;
for (int i = 0; i < len; i++)
{
ans = (ans * base + (ull)s[i]) % mod2;
}
return ans;
}
bool cmp(const std::string s, const std::string t)
{
bool f1 = get_hash1(s) != get_hash1(t);
bool f2 = get_hash2(s) != get_hash2(t);
return f1 || f2;
}
看到这里,简单的哈希模板就结束
字符串哈希的应用
哈希当然是不错的选择,但是去重可以直接用 ,看看我写的:
CPP#include <bits/stdc++.h>
using namespace std;
int main()
{
set<string> S;
int n;
cin >> n;
for(int i = 1; i <= n; i++)
{
string s;
cin >> s;
S.insert(s);
}
cout << S.size() <<endl;
return 0;
}
字符串哈希和栈结构的应用,我写到一半才发现我其实没有用哈希,我先让自己和自己匹配,再让两个字符串匹配,看着比哈希清楚不少:
CPP#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 9;
int len1, len2, res;
char s1[N], s2[N];
int f[N], p[N];
int St[N], top;
int main()
{
int i, j;
scanf("%s", s1 + 1);
scanf("%s", s2 + 1);
len1 = strlen(s1 + 1);
len2 = strlen(s2 + 1);
for(i = 2, j = 0; i <= len2; i++)
{
while(j && s2[i] != s2[j + 1])
{
j = p[j];
}
if(s2[i] == s2[j + 1]) j++;
p[i] = j;
}
for(i = 1, j = 0; i <= len1; i++)
{
while(j && s1[i] != s2[j + 1])
{
j = p[j];
}
if(s1[i] == s2[j + 1]) j++;
f[i] = j;
St[++top] = i;
if(j == len2)
{
top -= len2;
j = f[St[top]];
}
}
for(int i = 1; i <= top; i++)
{
cout << s1[St[i]];
}
return 0;
}
线段树基础
线段树是一种维护区间的数据结构,助手小李给个图例:
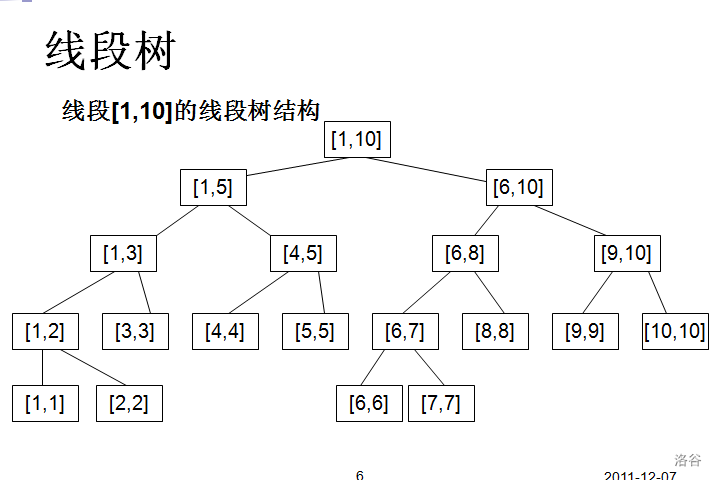
线段树可以进行答案合并,通过子节点的答案计算自己的答案,也被称为 ,看看我写的:
CPPvoid pushup(int p)
{
sum[p] = sum[p << 1] + sum[p << 1 | 1];
}
如何构造线段树?从编号再到区间,最后 ,看看我写的:
CPPvoid build(int p, int l, int r)
{ //节点p管理l至r
if(l == r)
{
sum[p] = 0;
return ;
}
int mid = (l + r) / 2;
build(p << 1, l, mid);
build(p << 1 | 1, mid + 1, r);
pushup(p);
}
如何修改线段树单点?向下遍历,在节点处直接修改,回溯并,看看我写的:
CPPvoid upd(int p, int l, int r, int x, int val)
{ //节点p管理l至r,在x位置加上val
if(l == r)
{
sum[p] += val;
return ;
}
int mid = (l + r) / 2;
if(x <= mid) upd(p << 1, l, mid, x, val);
else upd(p << 1 | 1, mid + 1, r, x, val);
pushup(p);
}
线段树的基础应用
完完全全板子题,但是其中有一个区间和需要进一步分析,实则查询区间,分段找点,看看代码:
CPP#include <bits/stdc++.h>
#define int long long
using namespace std;
const int N = 100100;
int sum[N * 4];
void pushup(int p)
{
sum[p] = sum[p << 1] + sum[p << 1 | 1];
}
void build(int p, int l, int r)
{ //节点p管理l至r
if(l == r)
{
sum[p] = 0;
return ;
}
int mid = (l + r) / 2;
build(p << 1, l, mid);
build(p << 1 | 1, mid + 1, r);
pushup(p);
}
void upd(int p, int l, int r, int x, int val)
{ //节点p管理l至r,在x位置加上val
if(l == r)
{
sum[p] += val;
return ;
}
int mid = (l + r) / 2;
if(x <= mid) upd(p << 1, l, mid, x, val);
else upd(p << 1 | 1, mid + 1, r, x, val);
pushup(p);
}
int qry(int p, int l, int r, int x, int y)
{
if(l == x && r == y) return sum[p];
int mid = (l + r) / 2;
if(y <= mid) return qry(p << 1, l, mid, x, y);
if(x > mid) return qry(p << 1 | 1, mid + 1, r, x, y);
return qry(p << 1, l, mid, x, mid) + qry(p << 1 | 1, mid + 1, r, mid + 1, y);
}
signed main()
{
int n, m, x, y;
char op;
cin >> n;
build(1, 1, n);
cin >> m;
while(m--)
{
cin >> op >> x >> y;
if(op == 'x')
{
upd(1, 1, n, x, y);
}
else
{
cout << qry(1, 1, n, x, y) <<endl;
}
}
return 0;
}
看似中位数,实则线段树,唯一不同的点在于中位数的处理需要提前进行离散化,具体思路为:去重;找第 大的数值输出,在此之前教两个函数:
函数
是C++语言中的STL函数,功能是将数组中相邻的重复元素去除。然而其本质是将重复的元素移动到数组的末尾,最后再将迭代器指向第一个重复元素的下标,使用方法如下:
CPPsort(a + 1, a + n + 1);
n = unique(a + 1, a + n + 1) - a;
for(int i = 1; i <= n; ++i)
{
printf("%d ",a[i]);
}
_ 函数
_是C++ STL中的一个二分查找函数,用于在有序序列中查找第一个不小于给定值的元素位置,返回指向该位置的迭代器,使用方法如下:
CPPfor(int i = 1; i <= n; i++)
{
a[i] = lower_bound(b + 1, b + m + 1, a[i]) - b;
}
介绍到这里新知结束,合在一起即可,看看我写的:
CPP#include <bits/stdc++.h>
using namespace std;
const int N = 100100;
int sum[N * 4], a[N], b[N];
void pushup(int p)
{
sum[p] = sum[p << 1] + sum[p << 1 | 1];
}
void build(int p, int l, int r)
{ //节点p管理l至r
if(l == r)
{
sum[p] = 0;
return ;
}
int mid = (l + r) / 2;
build(p << 1, l, mid);
build(p << 1 | 1, mid + 1, r);
pushup(p);
}
void upd(int p, int l, int r, int x)
{ //节点p管理l至r,在x位置加上val
if(l == r)
{
sum[p]++;
return ;
}
int mid = (l + r) / 2;
if(x <= mid) upd(p << 1, l, mid, x);
else upd(p << 1 | 1, mid + 1, r, x);
pushup(p);
}
int getans(int p, int l, int r, int k)
{
if(l == r) return l;
int mid = (l + r) / 2;
if(sum[p << 1 | 1] >= k) return getans(p << 1 | 1, mid + 1, r, k);
else return getans(p << 1, l, mid, k - sum[p << 1 | 1]);
}
int main()
{
int n;
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> a[i];
b[i] = a[i];
}
sort(b + 1, b + n + 1);
int m = unique(b + 1, b + n + 1) - b - 1;
for(int i = 1; i <= n; i++)
{
a[i] = lower_bound(b + 1, b + m + 1, a[i]) - b;
}
build(1, 1, m);
for(int i = 1; i <= n; i++)
{
upd(1, 1, m, a[i]);
if(i % 2 == 1) cout << b[getans(1, 1, m, (i + 1) / 2)] <<endl;
}
return 0;
}
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...