专栏文章
P3375 KMP 题解
P3375题解参与者 8已保存评论 7
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 7 条
- 当前快照
- 1 份
- 快照标识符
- @miqwm7jh
- 此快照首次捕获于
- 2025/12/04 11:56 3 个月前
- 此快照最后确认于
- 2025/12/04 11:56 3 个月前
使用背景
给定两个字符串 和 ,需要找到 在 中出现的所有位置。
暴力求解
我们很容易想到的就是匹配字符串时,我们从目标字符串 长度为 的 的第一个下标选取和长度为 的 长度一样的子字符串进行比较,如果一样,就返回开始处的下标值,不一样,选取 下一个下标,同样从 选取长度为 的字符串进行比较,直到 的末尾。
显然,我们发现了许多不合理的操作:比对失败时会从头开始匹配,浪费了许多时间,时间复杂度为 。
KMP 算法
根据上述原因,我们可以进一步优化。
在比对失败之后,如果可以向后移动多位,就可以减少不少时间。
-
next 数组
此时可以建立一个 next 数组(或 nxt),作为一个转移数组。它的含义就是一个固定字符串的最长前缀与最长后缀相同的长度。如:abcdefgabc不难发现,在这个样例下,相同的最长前缀与最长后缀就是abc。此时要注意,最长前缀是从第一个字符开始,但不包含最后一个字符。
例如:kkkk他的最长前缀是kkk。讲完上面的定义后,便进入正题。以字符串ababaca为例。
我们用 next 数组来计算字符串中相同的最长前缀与最长后缀。方便理解,next 数组下标从 开始,分别计算a,ab,aba,abab,ababa,ababac,ababaca。显然得出,其对应为- 无。
a只有一个字符,非相同,这是一个很重要的点。 - 无。
ab中a与b无法匹配。 a,aba中。ab,abab中开头结尾两个ab匹配。aba,ababa中先取前三个字符aba,再取后三个字符aba匹配。- 无。
ababac显然无法匹配。 a,ababaca开头结尾的两个a匹配。
这时,next 数组已经赋值为了{0, 0, 1, 2, 3, 0, 1}。我们想要用代码实现,可以用一张图来便于理解。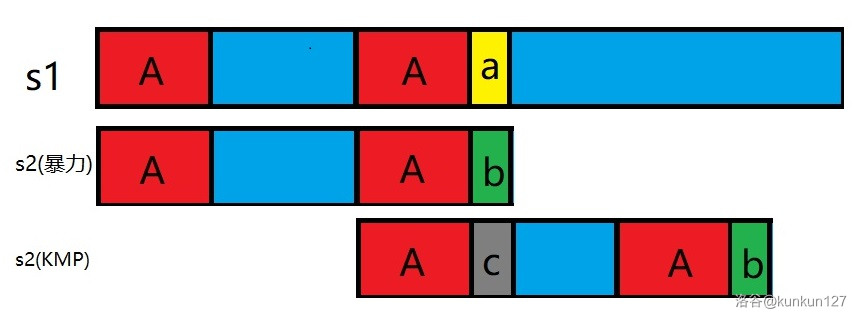 上图中的 是一样的。两个 之间的也是一样的,我们发现 和 不一样。之前的算法是把下面的字符串往前移动一个距离,重新从头开始比较,那必然存在很多重复的比较。现在的做法是,我把下面的字符串往前移动,使 尾部的 和 对齐,直接比较 和 是否一样。可以看到,匹配串每次往前移动,都是一大段一大段移动,假设匹配串里不存在重复的前缀和后缀,即 next 的值都是 ,那么每次移动其实就是一整个匹配串往前移动 个距离。然后重新一一比较,这样就比较 次,也就是,每次移动长度为 的距离,比较 次,移到末尾,就是比较 次,时间复杂度为 。假设匹配串里存在重复的前缀和后缀,移动的距离相对小了,比较的次数也小了,但时间也是 。这就是 KMP 算法的好处。
上图中的 是一样的。两个 之间的也是一样的,我们发现 和 不一样。之前的算法是把下面的字符串往前移动一个距离,重新从头开始比较,那必然存在很多重复的比较。现在的做法是,我把下面的字符串往前移动,使 尾部的 和 对齐,直接比较 和 是否一样。可以看到,匹配串每次往前移动,都是一大段一大段移动,假设匹配串里不存在重复的前缀和后缀,即 next 的值都是 ,那么每次移动其实就是一整个匹配串往前移动 个距离。然后重新一一比较,这样就比较 次,也就是,每次移动长度为 的距离,比较 次,移到末尾,就是比较 次,时间复杂度为 。假设匹配串里存在重复的前缀和后缀,移动的距离相对小了,比较的次数也小了,但时间也是 。这就是 KMP 算法的好处。 - 无。
代码实现
-
求 next 数组(建议写成 nxt)CPP
int len1 = s1.size(), len2 = s2.size(); int j = 0; for (int i = 1; i < len2; i++) { while (j > 0 && s2[i] != s2[j]) j = nxt[j - 1]; if (s2[i] == s2[j]) j++; nxt[i] = j; }外围的循环就是遍历整个 ,从 开始寻找的原因就是刚刚所说的,单个字符无法构成最长前缀,直接从第二个字符开始查找。
内层循环,如果 此时大于 ,并且 与 不匹配,那么就进行回溯()。
进入到下面的判断,此时如果 等于 , 加一。
此时再将 赋值为 ,也就是相同的最长前缀和最长后缀的长。 -
进行 KMP。CPP
for (int i = 0; i < len1; i++) { while (j > 0 && s1[i] != s2[j]) j = nxt[j - 1]; if (s2[j] == s1[i]) j++; if (j == len2) cout << (i + 1) - len2 + 1 << endl, j = nxt[j - 1]; }其实跟求 nxt 数组的过程差不多。只是我们不需要再更改 nxt 数组,而是当 等于 的长度时输出匹配成功的第一个字符的位置即可,再更新 。
这就是 KMP 算法的整个流程。
参考代码(模板)
CPP#include <bits/stdc++.h>
using namespace std;
int nxt[1000005];
int main()
{
string s1, s2;
cin >> s1 >> s2;
int len1 = s1.size(), len2 = s2.size();
int j = 0;
for (int i = 1; i < len2; i++)
{
while (j > 0 && s2[i] != s2[j]) j = nxt[j - 1];
if (s2[i] == s2[j]) j++;
nxt[i] = j;
}
j = 0;
bool flag = false;
for (int i = 0; i < len1; i++)
{
while (j > 0 && s1[i] != s2[j]) j = nxt[j - 1];
if (s2[j] == s1[i]) j++;
if (j == len2) cout << (i + 1) - len2 + 1 << endl, j = nxt[j - 1], flag = true;
}
for (int i = 0; i < len2; i++) cout << nxt[i] << ' ';
return 0;
}
时间复杂度
在预处理阶段,我们生成前缀函数这一步为 。后面搜索阶段,就算每次都不匹配,最坏情况下也只有 。因此,KMP 算法的时间复杂度为 。
相关推荐
评论
共 7 条评论,欢迎与作者交流。
正在加载评论...