专栏文章
知识点汇总
算法·理论参与者 1已保存评论 0
文章操作
快速查看文章及其快照的属性,并进行相关操作。
- 当前评论
- 0 条
- 当前快照
- 1 份
- 快照标识符
- @mip9ng5b
- 此快照首次捕获于
- 2025/12/03 08:25 3 个月前
- 此快照最后确认于
- 2025/12/03 08:25 3 个月前
基本技巧
高精度
使用情景
当一些运算的数据大大超过了诸如 等数据存储范围时,使用高精度进行算法的模拟
算法核心
通过对竖式运算的类模拟,进行数组中的运算。步骤大概如下:
字符串快速读入,并转换成数字
竖式运算模拟,注意进位退位
倒序输出答案数组
算法易错点
进位、左右端点维护等
代码(节选,加法和减法)
CPP#include<bits/stdc++.h>
using namespace std;
char a[300],b[300];
int A[300],B[300];
int main()
{
scanf("%s",a+1);
scanf("%s",b+1);
int ka=strlen(a+1);
int kb=strlen(b+1);
for(int i=1;i<=ka;i++)
{
A[i]=a[ka-i+1]-'0';
}
for(int i=1;i<=ka;i++)
{
B[i]=b[kb-i+1]-'0';
}
if(ka>kb) kb=ka;
for(int i=1;i<=ka;i++)
{
A[i]+=B[i];
A[i+1]+=A[i]/10;
A[i]=A[i]%10;
}
if(A[ka+1]==1) printf("%d",A[ka+1]);
for(int i=ka;i>=1;i--) printf("%d",A[i]);
return 0;
#include<bits/stdc++.h>
using namespace std;
char a[210],b[210];
int c[210],d[210];
int main()
{
scanf("%s%s",a,b);
int la=strlen(a);
int lb=strlen(b);
for(int i=1;i<=la;i++)
{
c[i]=a[la-i]-'0';
}
for(int i=1;i<=lb;i++)
{
d[i]=b[lb-i]-'0';
}
for(int i=1;i<=la;i++)
{
c[i]-=d[i];
if(c[i]<0)
{
c[i]+=10;
c[i+1]-=1;
}
}
int t=201;
while(c[t]==0)
{
t--;
if(t==0)
{
puts("0");
return 0;
}
}
for(int i=t;i>=1;i--)
{
printf("%d",c[i]);
}
return 0;
}
经典例题
分治算法
常见用途
用来将一个问题拆分成多个问题解决后再合并(这个是基本要求,不符合就不能用分治),时间复杂度恒为。分治的思想实际上还是递归,通过“分解——解决——合并”的步骤来处理问题。像二分查找、汉诺塔、归并排序都是分治思想的体现。
算法关键
分治算法的关键在于识别清楚各个子任务。类似动态规划的是,分治算法同样需要保证完全包含每一种情况,否则子任务合并时会出现结果错误。
关键代码
归并排序:
CPPvoid merge_sort(int l,int r)
{
if(l==r) return;
int mid=(l+r)>>1;
sorta(l,mid);
sorta(mid+1,r);
meger(l,mid,r);
return;
}
void meger(int l,int mid,int r)
{
int a1=l,a2=mid;
int b1=mid+1,b2=r,k=l-1; //对半分,由旧数组a[]更新到新数组b[]
while(a1<=a2&&b1<=b2)
{
if(a[a1]<=a[b1]) b[++k]=a[a1++];
else b[++k]=a[b1++];
} //两边的队首进行对比,直到一个数组结束
while(a1<=a2) b[++k]=a[a1++]; //清除残余,保证两边数组都被更新掉
while(b1<=b2) b[++k]=a[b1++];
for(int i=l;i<=k;i++) a[i]=b[i];
return;
}
经典例题
搜索
深度优先搜索( )
基础介绍
以深度为主要搜索方向,从一个点开始按某种条件搜索,直到满足一定条件后退出。顺序形如:
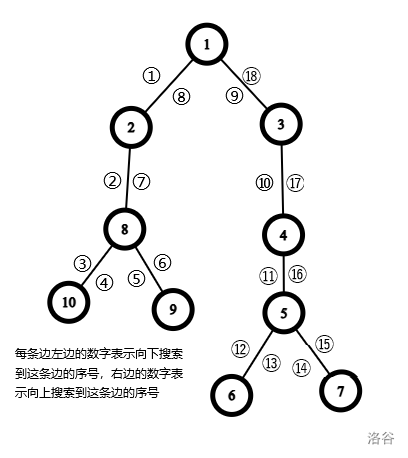
易错介绍
- 一定要写搜索的出口,否则容易死循环
- 对搜索的数据转移要小心(比如步数的转移),否则会答案错误
- 要保证搜索是完全的,不要少点多点
暴力部分分
对于一些时间复杂度极其苛刻的题,我们迫不得已就可以尝试暴力搜索得分,并且尽可能优化搜索
宽度优先搜索( )
算法介绍
相对于深度优先搜索,宽度优先搜索会像洪水蔓延一样从起点按照路径等级差每次搜索。
具体而言,是算法先搜索距离为 的点,再搜索距离为 的点,以此类推。
算法步骤
把根节点放到队列末尾
每次从队列的头部取出一个元素,查看这个元素的所有下一级元素,把他们放到队列的末尾
找到所要找的元素时停止搜索
算法用途
通过观察宽度优先搜索的特性:临近性、距离优先性、继承性等不难看出,这种搜索适合做
动态规划
区间
常见情形
当我们遇到像维护回文串等层层嵌套,有一定区间特点的问题时,我们可以考虑由小区间向大区间动态规划。
做题思路
先找到动态规划的次序,确保每一次动态规划,所需要的数值已经被求出;
随后考虑循环的上限、下限以及转移方程,根据题目具体特点分析。
区间 的题相对也不算复杂,重点是判断这道题是否使用。当我们发现这道题与区间 的题相似的时候,就考虑这么解决了。
例题
 这一题就是典型的回文串问题,看似毫无头绪,实际上我们套用区间 的思路,就会发现问题迎刃而解。这一题的正解就是由小及大地动态规划,每次都选择在右边或左边加减元素来维护回文串。当然我们也考虑区间扩大后,本身这个字符串就是回文串的情况,并相应地做出改变即可。
这一题就是典型的回文串问题,看似毫无头绪,实际上我们套用区间 的思路,就会发现问题迎刃而解。这一题的正解就是由小及大地动态规划,每次都选择在右边或左边加减元素来维护回文串。当然我们也考虑区间扩大后,本身这个字符串就是回文串的情况,并相应地做出改变即可。#include<bits/stdc++.h>
using namespace std;
const int N=110,M=2010;
int n,m,c[N],d[N],mp[M],f[M][M];
char s[M];
int main()
{
scanf("%d%d",&n,&m);
scanf("%s",s+1);
for(int i=1;i<=m;i++) mp[i]=s[i]-'a'+1;
for(int i=1;i<=n;i++)
{
char nxy;
cin>>nxy;
int zdc=nxy-'a'+1;
scanf("%d%d",&c[zdc],&d[zdc]);
}
memset(f,0x3f,sizeof f);
for(int i=1;i<=m;i++) f[i][i]=0;
for(int k=1;k<=m;k++)
{
for(int i=1;i+k<=m;i++)
{
int j=i+k;
f[i][j]=min(f[i][j-1]+min(c[mp[j]],d[mp[j]]),f[i+1][j]+min(c[mp[i]],d[mp[i]]));
if(mp[i]==mp[j])
{
if(j-i==1) f[i][j]=0;
else f[i][j]=min(f[i][j],f[i+1][j-1]);
}
}
}
printf("%d",f[1][m]);
return 0;
}
普通动态规划
常见步骤
观察数据范围与时间上限
确定算法时间复杂度
寻找 维 数组分别都是什么量
推导公式
找出等量关系,确定优化项目(确定时间复杂度的时候,允许在理论上有一定的超限,这样优化可能是有用的)
写代码
常见优化方法
不优化 在可行情况下能够控制在有限时间内就不用加优化
单调队列 在多维 中,确定一个下标,而其他下标取值有一定要求(比如要小于某数或维护单调性)的时候,可以使用单调队列进行优化 。
常见 大方向
松弛 由大及小地动态规划,找最好的分段点。一般多用于数列最小分段等类似的问题
传递 由前及后(线性中,多维的可能还有别的顺序)地动态规划,传递至某个位置。
矩阵
矩阵乘法
常见用途
- 优化多维快速幂
- 对于一些图论题目有奇效
这里的奇效主要指的是如下文的经典题目,结合矩阵乘法的原理,我们会发现它和最短路的松弛有异曲同工之妙,那这种时候我们推出式子,就可以考虑矩阵乘法了。
注意:矩阵乘法的式子不要通过找规律来推,更倾向于直接找本质(和动态规划是一样的)
认为矩阵乘法与动态规划的区别在于,矩阵乘法的某个值是极大的,另一个值是极小的,这就可以指数级优化大数而开一个小的二维数组。动态规划则不然(一般是一维的)
MARKDOWN题目描述
游乐园里有一个奇怪的迷宫,迷宫内有n个点,每个点之间都可能会有一条有向边(可能会有自环)
现在游乐园主有个问题想请你帮忙:
问:从s点走到f点,恰好走过m条边(边可以重复走),总共有多种不同的方案(两种方案只要有一条边不同,就是不同方案)
现在你只需要输出方案数对P取模的结果就可以了。
输入
一个整数n
下面跟着n行n列的邻接矩阵,两个数之间有一个空格
在下一行依次是整数m、s、f、p。
1<=n、s、f<=50
1<=m<=10^6
1<=p<=10^5
输出
一个数即方案数对p取模的结果。
样例输入
5
0 1 1 1 1
0 0 0 0 0
1 1 0 1 1
0 0 0 0 1
0 0 0 0 1
3 1 5 1994
样例输出
5
基础介绍
基于系统栈的数据结构,个人感觉其实手搓栈和这个没有太多区别,但是使用 的便捷性显然更优一些,能够使代码变得更简洁。
不支持迭代器和指针,每次都只能访问队头和队尾元素( 结构),如果需要访问中间元素的话要使用其他数据结构(数组等)。不过 对一些只需要访问队头队尾的问题(比如单调队列优化动态规划)就会有奇效。
使用介绍
CPP#include<bits/stdc++.h>
using namespace std;
queue<int>q; //声明一个int类型的队列,数据类型和队列名称是可以变化的
signed main()
{
printf("%d %d\n",q.empty(),q.size());
for(int i=1;i<=4;i++) q.push(i);
printf("%d\n",q.back());
q.pop();
printf("%d %d\n",q.empty(),q.size());
printf("%d\n",q.front());
return 0;
}
/*
q.empty() //如队列为空,返回1,否则返回0
q.size() //返回队列中的元素个数,遍历队列默认从0开始,如 for(int i=0;i<=a.size();i++)
q.front() //返回队头元素值
a.back() //返回队尾元素值
q.pop() //删除队头元素
q.push(a) //在队尾插入a
*/
输出:
MARKDOWN1 0
4
0 3
2
常见优化方向
- 深度优先搜索、广度优先搜索的栈储存
- 优化单调队列
- 优化结构体(整形数据可以变成结构体数据)
基础介绍
基于红黑树的数据结构,可以建立任意两个数据类型之间的映射,大大便利了我们对某些特殊数据的查询,能够很好地优化空间复杂度。
会对关键字从小到大排序,并保证关键字的唯一性。对于一个键值对, 描述关键字, 描述存储对象,插入键值对后关键字不可修改,但存储对象可以修改
提供迭代器,所有对 的操作都是 级别的。
近几年逐渐成为比赛的主要算法之一,使用频率是 里面相对高的。尤其对于一些数据较大较稀疏的情况,使用 可以避开空间复杂度优化(就这个 大法好
功能介绍
CPP#include<bits/stdc++.h>
using namespace std;
map<string,int>mp; //建立一个从string映射到int的map,其中string是关键字类型,int是存储对象类型
//当然我们也可以建立一个同一种数据类型之间的映射,比如:map<int,int>mp;
map<string,int>::iterator it; //生成一个对于map的指针(含指针的代码会有点难调,推荐入门者使用数组遍历法
int main()
{
mp.insert({"nxy",5});
mp.insert({"aoteman",4}); //插入键值对的时候不要忘了加“{}”
mp.insert({"beiliya",3});
mp.insert({"ljb",2});
mp.insert({"nailong",1});
mp.insert({"xiaomi su7",6});
mp.insert({"xiaomi yu7",6});
cout<<(mp.begin()->first)<<' '<<(mp.begin()->second)<<endl;
cout<<(mp.end()->first)<<' '<<(mp.end()->second)<<endl; //mp.end()对应一个空键值对.
it=mp.end();
it--;
cout<<it->first<<' '<<it->second<<endl;
puts("");
printf("%d\n",mp.size());
printf("%d\n",mp["nxy"]);
puts("");
mp["nxy"]=12;
mp.erase(mp.find("xiaomi su7"),mp.find("xiaomi yu7")); //后面那个指针对应的键值对不会被删除
puts("");
for(it=mp.begin();it!=mp.end();it++) cout<<it->first<<' '<<it->second<<endl;
puts("");
it=mp.lower_bound("nailong");
cout<<it->first<<' '<<it->second<<endl;
puts("");
it=mp.upper_bound("nailong");
cout<<it->first<<' '<<it->second<<endl;
return 0;
}
输出:
MARKDOWNaoteman 4
0
xiaomi yu7 6
7
5
aoteman 4
beiliya 3
ljb 2
nailong 1
nxy 12
xiaomi yu7 6
nailong 1
nxy 12


图论
最短路
最短路实际上可以区分为单源最短路和任意两点之间的最短路。当然,如果你已经求出了单源的最短路,实际上就已经求出后者了。即便是多次询问,我们也不会选择将每两个点之间的最短路径都求出来(也就是 ),这个时间复杂度是远远高于使用其他方法先求出单源路径的。
因此,我们这里不介绍 复杂度的 ,而重点谈谈 和 。
实际上 在最短路的应用中应限制在判负环一种应用,因为在实际竞赛中,其不稳定的时间复杂度可能被极端数据卡死。因此,这里我们先给出 的模板,简单介绍原理和如何判负环后就选择跳过了。
模板代码
CPP#include<bits/stdc++.h>
using namespace std;
const int N=2e5+10; //内存复杂度依照具体题目改变
int to[N],val[N],nxt[N],head[N],tot;
int dis[N];
bool in_q[N]; //判断是否在队列q中
void add(int x,int y,int z)
{
to[++tot]=y;
val[tot]=z;
nxt[tot]=head[x];
head[x]=tot;
}
// 以上是常规的链式前向星建边
void spfa(int x) //以x为起点的最短路
{
dis[x]=0;
queue<int>q;
q.push(x);
in_q[x]=true;
while(!q.empty())
{
int u=q.front();q.pop();
in_q[u]=false;
for(int i=head[u];i;i=nxt[i])
{
int j=to[i],w=val[i];
if(dis[j]>dis[u]+w)
{
dis[j]=dis[u]+w;
if(!in_q[j]) in_q[j]=true,q.push(j);
}
}
}
}
signed main()
{
int n,m;
//自行读入
//接下来是对spfa和链式前向星的初始化
for(int i=1;i<=N;i++)
{
nxt[i]=-1;
head[i]=-1;
in_q[i]=false;
dis[i]=1e9;
}
for(int i=1;i<=m;i++)
{
int u,v,w;
scanf("%d%d%d",&u,&v,&w);
add(u,v,w);
//如果是无向边别建错了
}
return 0;
}
主要就是一个宽度优先搜索的思路,不断地利用队列先进先出的特点,对已经加入的点进行有规律的松弛,从而做到求出单源最短路径
模板代码
CPP#include<bits/stdc++.h>
using namespace std;
const int N=2e5+10, INF=0x3f3f3f3f;
int head[N], nxt[N], to[N], val[N], tot;
int dis[N]; // 存储最短距离,替代原ans数组
bool vis[N]; // 标记是否已确定最短路径
// 链式前向星加边
void add(int x, int y, int z) {
to[++tot] = y;
val[tot] = z;
nxt[tot] = head[x];
head[x] = tot;
}
// 优先队列节点(距离+节点编号)
struct Node {
int dis, id;
// 重载小于号,使优先队列成为小根堆(距离小的先出队)
bool operator<(const Node& x) const {
return x.dis < dis;
}
};
// Dijkstra算法实现(x为起点)
void dijkstra(int x) {
priority_queue<Node> q;
dis[x] = 0; // 起点距离为0
q.push({0, x}); // 直接构造节点,省略make_node
while (!q.empty()) {
Node cur = q.top(); // 取堆顶
q.pop(); // 弹出堆顶(拆分语句,修正语法错误)
int u = cur.id, d = cur.dis;
if (vis[u]) continue; // 已确定最短路径,跳过
vis[u] = true;
// 遍历邻边
for (int i = head[u]; i; i = nxt[i]) {
int v = to[i], w = val[i];
if (!vis[v] && dis[v] > d + w) { // 未确定且可松弛
dis[v] = d + w;
q.push({dis[v], v}); // 直接构造节点入队
}
}
}
}
int main() {
int n, m, s; // s为起点
scanf("%d%d%d", &n, &m, &s); // 补全输入:节点数、边数、起点
// 初始化(在读取n后进行,避免n未赋值)
tot = 0;
memset(head, 0, sizeof(head)); // 链式前向星头节点初始化为0
memset(vis, 0, sizeof(vis));
memset(dis, 0x3f, sizeof(dis)); // 距离初始化为INF
// 读入边
for (int i = 1; i <= m; i++) {
int u, v, w;
scanf("%d%d%d", &u, &v, &w);
add(u, v, w);
// 若为无向图,添加 add(v, u, w);
}
dijkstra(s); // 传入起点参数
// 此处可添加输出逻辑,例如输出各点到起点的最短距离
return 0;
}
相关推荐
评论
共 0 条评论,欢迎与作者交流。
正在加载评论...